内存
本文系统的聊一聊内存的方方面面,后面有新的内容会补充上来。
- 1 操作系统的内存管理
- 2 系统内存分类
- 3 java中的内存
- 4 BRK、MMAP、共享内存、零拷贝
1 操作系统的内存管理
这个在之前的文章中讲过,这里简单讲,详情可以参考。
1.1 基础: 虚拟内存 物理内存 页表
虚拟内存地址是指一个程序认为自己能操作的内存地址,虚拟内存地址的个数取决于操作系统是32位还是64位,32位能操作4G个地址,每个地址存储1Byte数据,因而32位程序认为自己能操作4GB内存空间。64位则是2^34GB,估计我有生也不会有这么大内存的PC。
物理内存是指内存条,64位系统能操作的内存非常大,但是实际上可能只有8GB的内存条。程序中看到的是虚拟内存,实际需要寻址映射到物理内存。每个字节都映射效率太低,映射表也需要非常大,所以提出了分页,假设页大小4K(常见大小),就是虚拟内存每4K空间与物理内存4K进行映射。
页表就是来存储这个映射关系的,为了区分物理内存和虚拟内存的页,我们把物理内存的页暂时叫做帧。页表就是将页号映射成帧号或者映射到磁盘。
重点:
因为虚拟内存可能远远大于物理内存,我们可以启动申请10G内存的java程序,而此时我们的操作系统能用的内存可能只有8G。另外的2G是在页表中是映射到磁盘的。当真正需要8G以上的内存的时候,就会映射到磁盘,此时会触发缺页中断(或叫缺页异常)从用户态进入内核态,操作系统运用页置换算法,将不咋用得到的内存帧置换到磁盘,将这部分帧给我们的这个程序来使用,并更新页表。
虚拟内存会有很多超乎想象的效果,下文中会提到java中使用unsafe申请堆外空间的时候申请超过整个机器的内存上限(65G)的内存,都不会报错退出。其实使用C语言也有相同的效果,我之前看过一个视频,小哥用malloc申请了130000+GB的内存程序才退出,而如果在malloc后给申请的地址填写值,事情就不那么顺利了。https://www.youtube.com/watch?v=Fq9chEBQMFE
细节:
- 页号数量大于帧号数量,会使页表中页号可能是10位数,帧号可能是5位数
- 缺页中断是触发从用户态进入内核态,触发用户->内核的情况是中断、异常和系统调用
- 一个内存地址内的"住户"是一个字节而不是一个比特
- 页表存在主存中,而不是cpu或者特殊硬件

1.2 优化:多级页表、快表、cpu缓存
页表占用空间很大,为了解决空间问题,有了多级页表,一级页表记录二级页表的位置,依次类推。多级页表可以有效地节省空间。
快表TLB,页表存于主存中,内存寻址需要两次访问主存,时间较长。为了解决时间问题,有了快表。每个进程有个快表,快表在cpu中特殊硬件,容量很小。快表记录进程最常访问的页的映射关系,是对页表中热点的缓存。快表可以有效地解决时间问题。
cpu缓存,常见的策略有
- PIPT,物理内存缓存,是查页表映射到物理内存时,先查下cache中有没有缓存。坏处是非常慢,前期都没有加速,好处就是进程可以共享了。
- VIVT,虚拟内存缓存,是查页表之前就先看cache是不是有存了,好处是非常快,坏处是每个进程的逻辑地址都是独立的,进程间不能共享。
- VIPT,将两者结合,用逻辑地址查找cache,cache中数据部分前面添加一个对应物理地址的tag。这样拿到这个tag后到tlb、页表中查看下这个对应关系是否正确,如果正确就直接读cache。这样速度和共享性都是折中的。
2 系统内存分类
2.1 linux free指令
在linux中通过free -h可以看到当前系统的内存情况:

mem是物理内存,swap是交换分区,是用来将内存暂时放到磁盘上的。
total总内存大小,used用户使用的内存大小,free空闲的内存大小,shared共享内存大小,buff/cache文件缓存大小,available可用内存大小。
total = used(含shared) + free + buff/cache
这里需要理解buff/cache,他们在老一些的内核中是分开显示的分别是buffer cache和page cache,都是对磁盘的缓存。其中buffer cache是硬件层面,对磁盘块中的数据进行缓存,缓存的单位当然也是块。而page cache是文件系统层面,对文件进行缓存,缓存单位就是页。buffer cache的提出非常的早,两者并存时会遇到重复缓存了相同的内容的情况。
较新的内核已经将两者合并,或者说将buffer cache合到了page cache。虽然也还是能缓存磁盘块,但是存储单位也是页了。并且buffer使用前会先检查page cahce是否已经缓存了对应内容,如果是则直接指过去。
buff/cache占用大,会不会影响后续程序申请内存?
不会,一旦用户程序需要申请内存,buff/cache就会释放掉一部分。换句话说buff/cache是在内存比较空闲的时候,尽量利用一下来加速文件读写的。如果有大哥需要用内存,是会拱手让出的。
2.2 已提交内存
在windows任务管理器中jprofile查看java内存利用情况的时候经常看到已提交内存
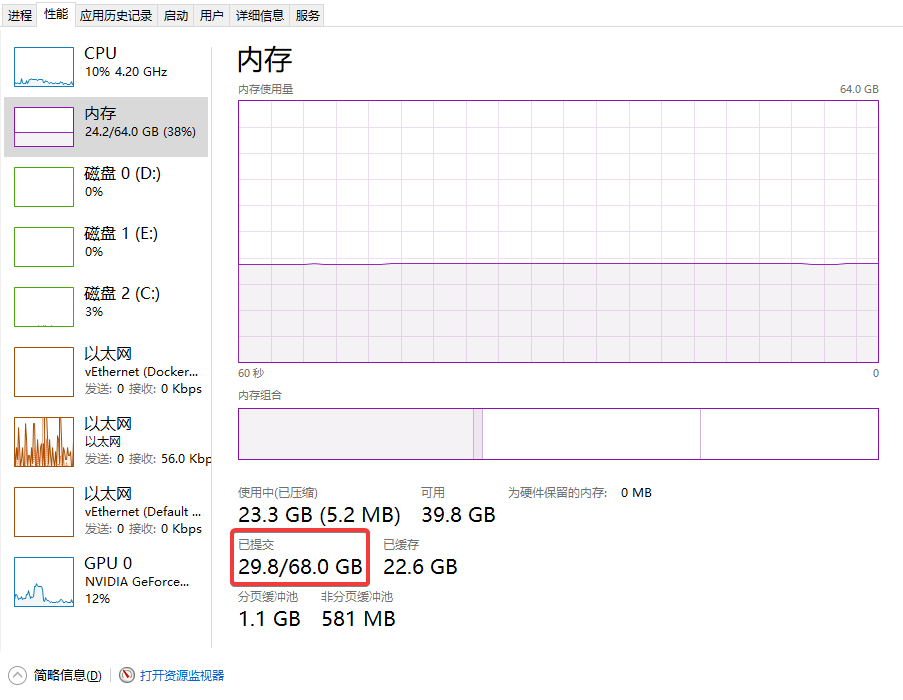
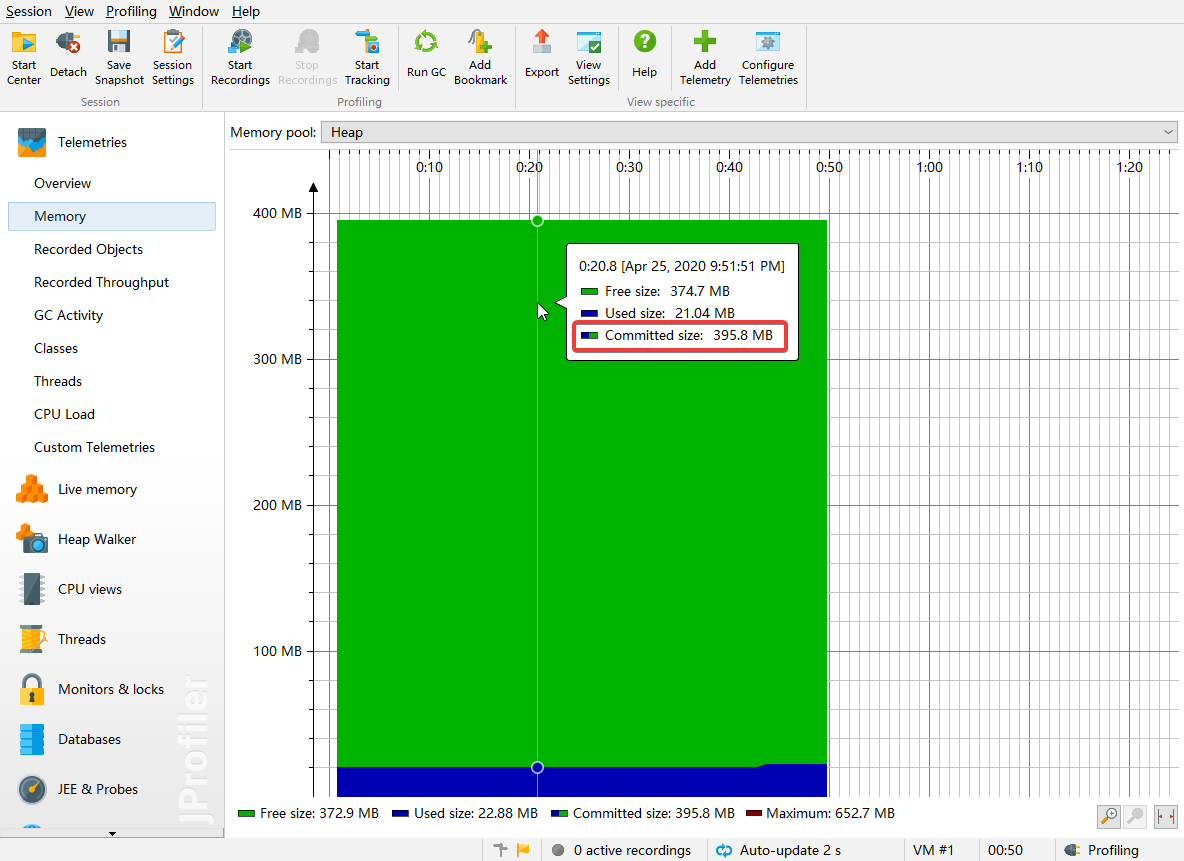
已提交的意思是已经向操作系统申请了这么多的内存,操作系统可以已经给了这么多内存了,但是也可能没有给那么多(映射到了磁盘)。
2.4 64位系统虚拟地址并非64bit
很多人想当然的会认为64位系统的虚拟地址就是64位,这其实不对。
#include <stdio.h>
int main(){
int x = 10;
printf("%p",&x)
}

明显看到是48位,通过cat /proc/cpuinfo最后几行能看到物理地址和虚拟地址的大小。当然我的这台linux只有2G,其实物理地址不会有43位,只是cpu最多支持43位物理地址。
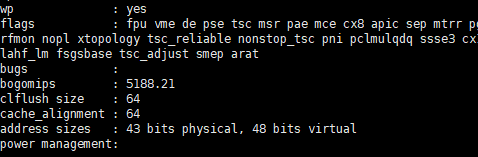
小细节:栈是仅次于内核的高位地址,所以看到前面这个地址基本能推算出分给内核的虚拟空间应该是0xffff ffff ffff - 0x8000 0000 0000。
3 java中的内存
java内存其实之前也有比较详细的描述jvm内存模型,这里还是做下综述。
3.1 jvm内存各区
堆主要存储新对象、常亮区从jdk7开始也移到了堆中。栈主要是函数运行存储局部的变量,存储单位是栈帧。一般是存储基础数据类型和对象的引用。方法区jdk8之后方法区位于元空间,使用的是操作系统内存。本地方法栈C++程序的栈。程序计数器记录当前函数执行位置。
栈、本地栈、计数器都是线程私有的。栈上有时候也能分配对象,需要满足对象大小不能太大,逃逸分析后发现没有逃出当前栈等条件。
3.2 java对象的大小
java对象由对象头、内容和填充3部分构成,而对象头由三部分构成:
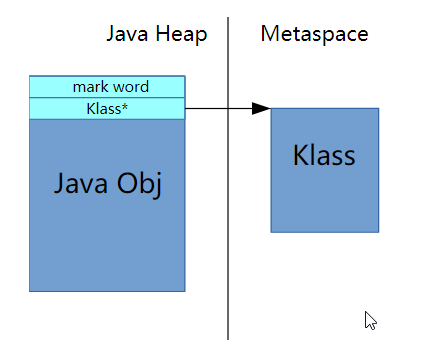
- Mark Word(64bits) 当前对象一些运行时数据如锁
- Klass Word(32bits) 类型指针,指向类结构元数据Klass地址(不是自己的地址)
- array length(32bits) 数组对象才有 对象头详情可以参考
填充是指对象大小必须是8Byte的倍数,如果不是则进行填充。8字节是可以调整的通过-XX:ObjectAlignmentInBytes 参数。
java中64位系统下,堆内存小于32G的时候,是默认开启指针压缩的,也就是一个对象的地址可以用32bit(4字节)表示,而不是8字节。对象的地址开了压缩,同理原空间的类对象地址也需要开启压缩。
https://stuefe.de/posts/metaspace/what-is-compressed-class-space/
Compressed Object Pointers (“CompressedOops”) and Compressed Class Pointers. Both are variants of the same thing.
这是怎么做到的呢?因为对象8字节对齐,所以我们只需要记录当前对象起始地址是第几个8字节。32GB是2^35,8字节是2^3,所以32GB内存最多容纳2^32个8字节,换句话说32G最多放2^32个对象,所以地址只需要2^32个,因而用4字节就可以标识每个对象的地址了。
但是超过32G的堆的java进程就不行了,只能使用更多的字节来表示地址了,一般是8字节。所以会遇到33G的堆反而没有32G堆的java进程能用的内存多。
3.3 元空间
metaspace介绍全部参考https://stuefe.de/posts/metaspace/what-is-metaspace/
元空间无疑是堆外空间,他主要是来存储类的元数据信息。
Q1:元空间内存什么时候分配?
一个新的类在需要被加载的时候,会使用ClassLoader在元空间申请内存,并存储类的元数据信息。
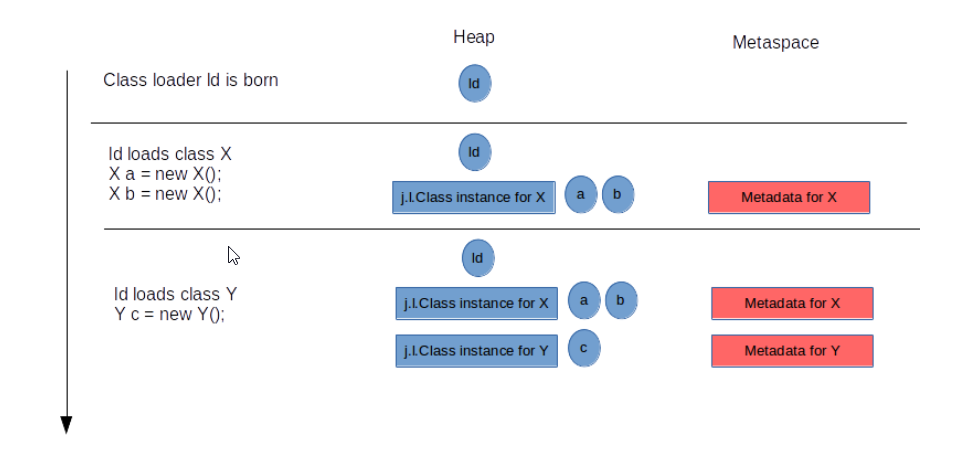
Q2:元空间存储的内容是什么?是Class这个对象吗?Klass到底是指哪些元数据。
Class对象是存在堆中的,如上图。元空间存的是这个类的一些元数据信息。存储的内容如下,有类结构的Klass、记录方法的vtable、itable、字节码、方法、注解等等。
其中Klass包括了类的修饰符、类名、父类、类加载器等等。
Q3:元空间什么时候释放内存?
元空间的内存是ClassLoader持有的,所以说只有对应的ClassLoader卸载掉的时候才会释放。ClassLoader又是需要他所加载的类都消失的时候才能消失。一般是伴随在一次GC的过程中进行这个释放。元空间如果超过了上限也会导致OOM。
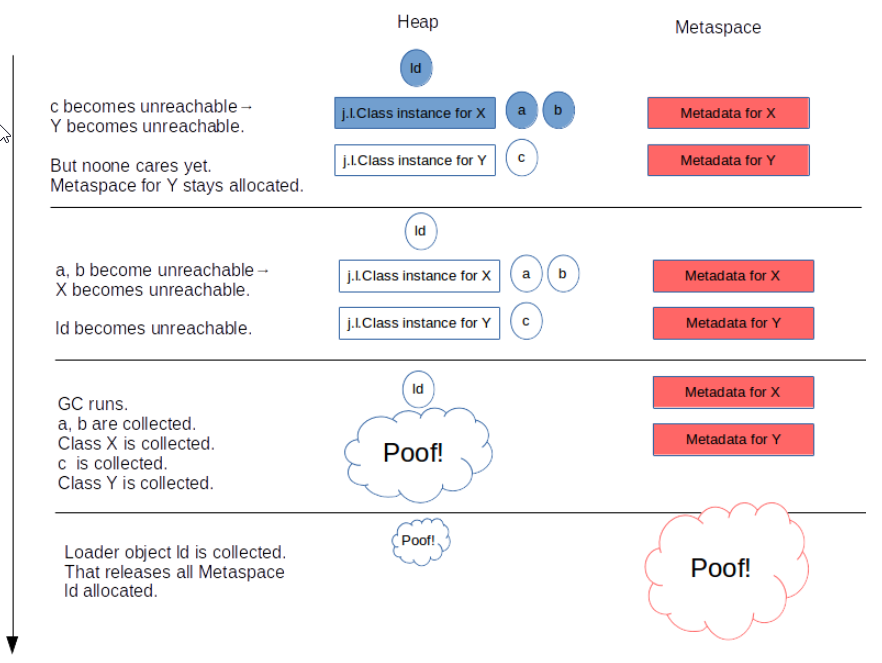
Q4:Metaspace和CompressedClassSpace区别?
在Jprofile中内存栏,能看到堆外内存有三类。分别是CodeCache、CompressedClassSpace和Metaspace(non-class)
CodeCache就是代码的缓存,这个很好理解,一般就几兆到几十兆取决于代码多少。而对于后两者,压缩类空间存放的是Klass(类结构的元数据),而non-class存储的是除了Klass之外的其他元数据。 压缩类空间存储的Klass并没有压缩,只是对象头中指向Klass地址的部分被压缩了(从8字节压缩到4字节)。
有的地方把存Klass的压缩类空间和Non-class的Metaspace统称为Metaspace,有的地方却是分开说,这里知道这么个事就可以了,不用纠结到底该怎么分类。
关闭指针压缩后,-XX:-UseCompressedOops或者超32G内存。统一称为Metaspace.

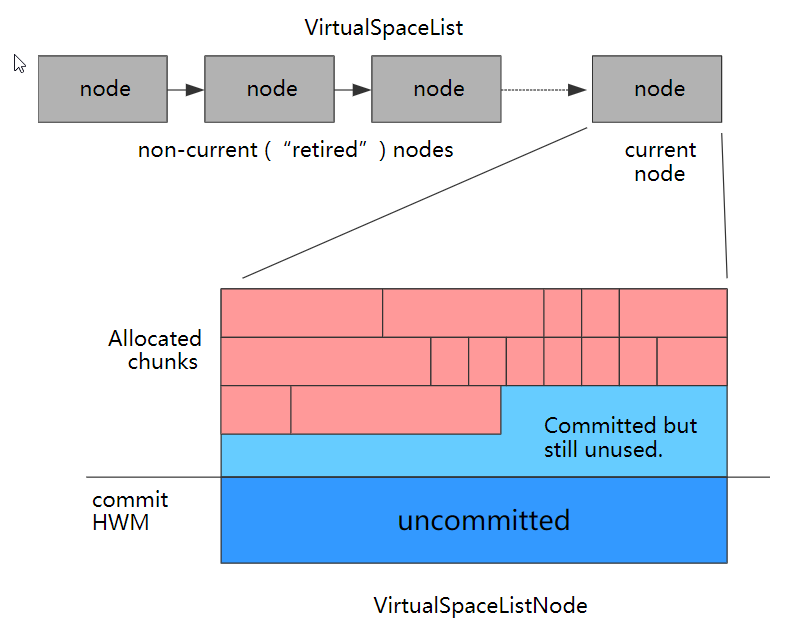
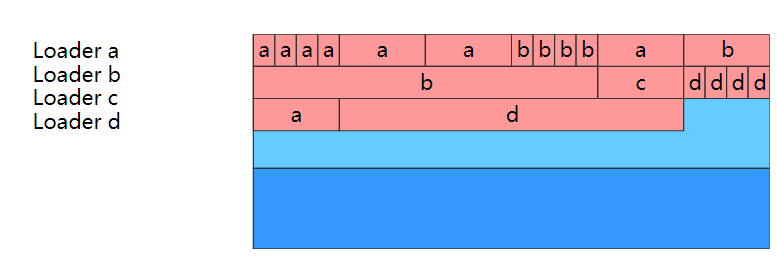
Q5:元空间里面是什么样子的?
元空间中内存都是每2M一个Node,链表形式连起来。每个Node节点中是由很多Metachunk组成的。每个类加载器对应多个chunk,每个chunk内又是由多个metablock组成,每个block存储了一个Klass(a Metablock houses one InstanceKlass, for instance)
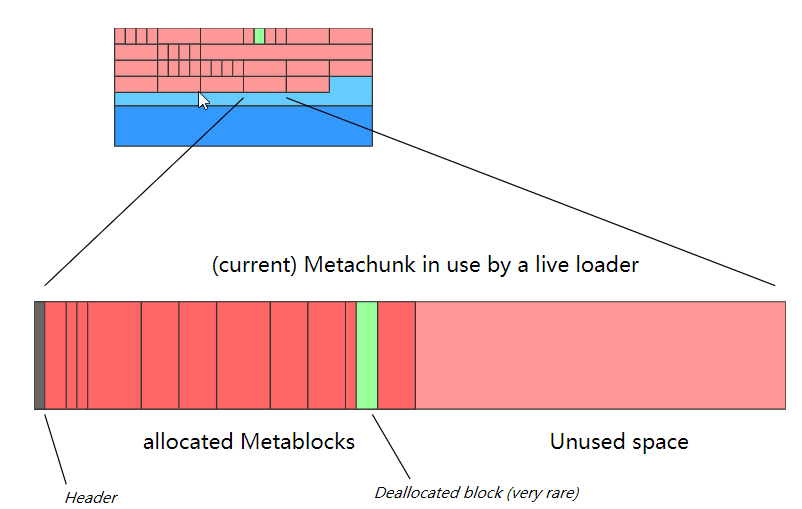
Q6:指针压缩是什么?
64位系统下,逻辑地址是8字节的。但是java中对象是8字节对齐的。此时,32G以内的JVM,32G=2^35B,最多放多少个对象呢?2^35除以2^3等于2^32,所以用4个字节就可以标识每个对象的地址了。这种用4字节表示对象地址的方式就是普通对象指针压缩。在32G以内的时候java默认就会开启,而超过32G则会自动关闭(此时引用就是8字节)
上面说的是普通对象指针压缩Compressed Object Pointers (“CompressedOops”),这其实跟压缩类空间无关,因为Klass不是普通对象,他的指针还是8字节。这里其实还有个Compressed Class Pointers概念,但是两者一般是同时生效的。所以顺带也把Klass指针给压缩了。我们知道前者是因为8字节对齐和堆32G限制,使压缩成为可能。那后者呢?
Q7:上面的问题:Klass指针是如何做到压缩的?
These restrictions are harsh. They are also only really needed for Klass structures, not for other class metadata: only Klass instances are currently being addressed with compressed references. The other metadata get addressed with 64bit pointers and hence can be placed anywhere.
只有Klass(类的结构信息)是需要指针压缩的,其他类的元数据信息不需要。因为对象头中只记录Klass地址,Klass里有偏移多少位是什么字段等重要的结构信息。因此跟之前一样,限制Klass所在的压缩类空间大小是32G以内,就可以完成压缩了。
So it was decided to split the metaspace into two parts: a “non-class part” and a “class part”:
The class part, housing Klass structures, has to be allocated as one contiguous region which cannot be larger than 32G.
The non-class part, containing everything else, does not.
Q8:Klass与Class关系?
Klass是C++对象InstanceKlass,里面有个_java_mirror指向对应的Class对象。https://zhuanlan.zhihu.com/p/51695160
3.4 堆外空间
上面的CodeCache和Metaspace毫无疑问是jvm管理下的堆外空间。但是除了这些常规的堆外空间,jvm还可以使用一些native方法,直接申请堆外内存。
例如做这么个demo,我们设置一个简单的java程序的堆大小是10M,此时用jprofile查看内存堆提交了10M实际使用9M多,堆外提交了12M实际使用11M左右。所以算下来是20M+。直接查看进程内存会略大于这个值,因为这个20M是虚拟机内部的内存,本身运行还是需要一些额外内存的,进程提交的内存有90M,实际使用内存47M


接下来我们使用Unsafe申请1G堆外内存。
public static void main(String[] args) throws InterruptedException, IllegalAccessException, NoSuchFieldException {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe us = (Unsafe) f.get(null);
long addr = us.allocateMemory(1024 * 1024 * 1024);
System.out.println("Hello World");
System.out.println(addr);
while(true){
Thread.sleep(1000L);
}
}
可以看到提交的内存1G多,实际使用内存也是47M。
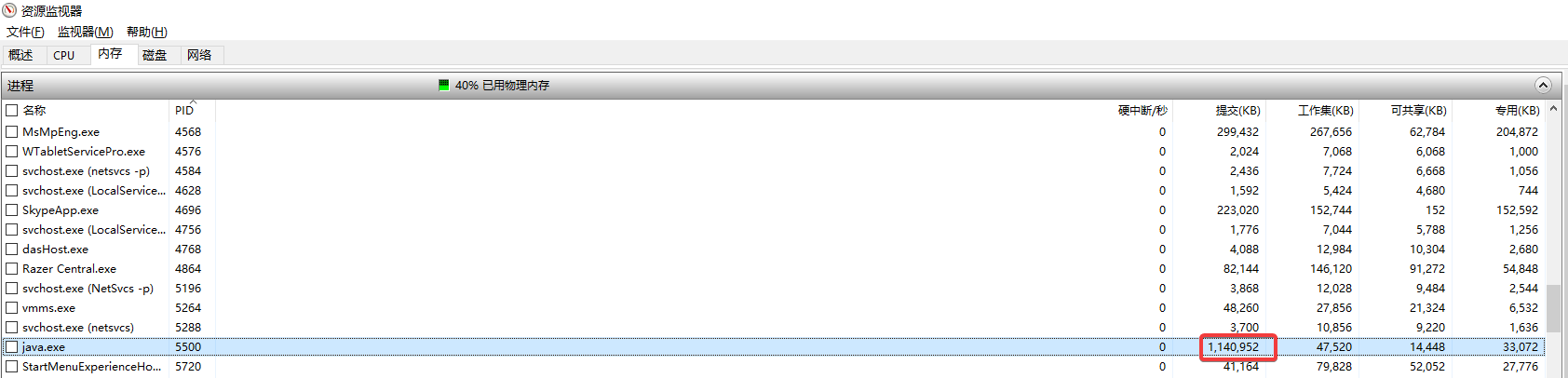
我甚至可以调整申请65G的内存,要知道我的电脑也只有64G的内存,但这仍不会报错,可以看到提交的内存已经超过了物理内存上限,但是得益于前面讲的虚拟内存的管理模式,使得应用申请了超过物理大小的内存,而如果真的使用起来的话,会有页置换来协调。

上面的提交内存很大但是实际使用内存却并不大:
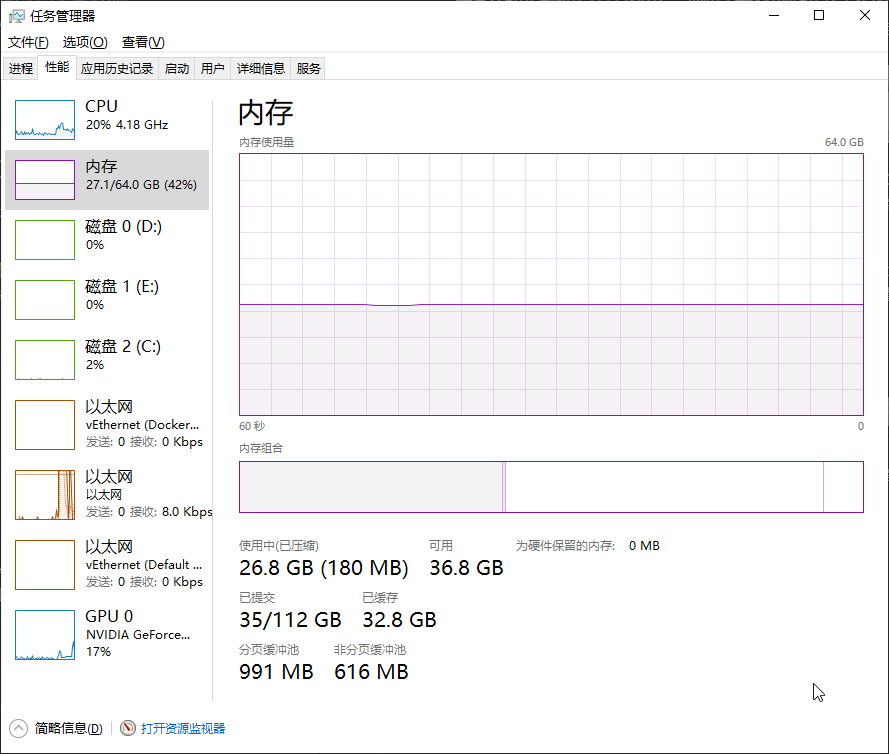
Unsafe是很危险的一个类,不建议在任何情况下使用。但是可以帮助我们理解有些框架是如何工作的。比如Ehcache提供了堆外缓存就是用Unsafe申请的。堆外缓存需要自己实现序列化,因为Unsafe设置内存只能设置01字节码不能设置为java对象。
堆外缓存的好处:缓存一般是短时间不需要清理的,如果在堆上则肯定会进入老年代,占用固定的一大块空间,使得触发full GC的门槛降低了,很容易到了那个门限值。而且GC过程中还要去遍历这些对象,效率较低。
除了Unsafe,NIO中的ByteBuffer.allocateDirect()也能直接在堆外malloc空间。
堆外内存的坏处:序列化需要自己实现,清理也需要自己实现,访问速度比heap要慢。
4 BRK、MMAP、共享内存、零拷贝
C语言中使用malloc开辟内存,malloc实际上是通过调用brk或者mmap这两个系统调用实现的内存分配。进程的虚拟内存地址的分段情况是这样的 最高的地址部分是内核内存,这部分内存是所有进程共享的,内核空间。往下挨着的是栈,最下面是代码和元数据区,稍微高一点的是堆。堆向上生长,栈向下生长。中间的部分是函数区:
 上图是32位系统,内核占用1G,64位则是大于这个值的。不过这里的重点是中间的函数区。
上图是32位系统,内核占用1G,64位则是大于这个值的。不过这里的重点是中间的函数区。
4.1 brk
malloc小于128K(阈值可修改)的内存时,用的是brk。C语言中sbrk(可函数)是brk(系统调用)的简单封装,下面代码打印的值可以看出first因为申请了0大小,所以和second指针位置相同。而third则表示的是second的尾部地址。可以看到虚拟地址是连续分配的,brk其实就是向上扩展heap的上界。
#include <stdio.h>
#include <unistd.h>
int main(){
void *first = sbrk(0);
void *second = sbrk(1);
void *third = sbrk(0);
printf("%p\n",first);
printf("%p\n",second);
printf("%p\n",third);
}
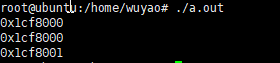
如果此时在 third+1地址处去初始化一个int值,是可以成功的,并不报错。
#include <stdio.h>
#include <unistd.h>
int main(){
void *first = sbrk(0);
void *second = sbrk(1);
void *third = sbrk(0);
int *p = (int *)third+1;
*p = 1;
}
这是因为页大小是4K,sbrk(1)其实也是申请一页,所以third+1位置也是安全的。如果我们将second这行改为4096,那就是另一个故事了,会触发段错误。
void *second = sbrk(4096);

4.2 mmap
malloc大于128K的内存时,用的是mmap。
// addr传NULL则不关心起始地址,关心地址的话应传个4k的倍数,不然也会归到4k倍数的起始地址。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
//释放内存munmap
int munmap(void *addr, size_t length);
mmap用法有两种,一种是将文件映射到内存,另一种空文件映射,也就是把fd传入-1,就会从映射区申请到一块内存。malloc就是调用的第二种实现。
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
int main(){
int* a =(int *) mmap(NULL, 100 * 4096, PROT_READ| PROT_WRITE, MAP_PRIVATE| MAP_ANONYMOUS, -1, 0);
int* b =a;
for(int i=0;i<100;i++){
b = (void *)a + (i*4096);
*b =1;
}
while(1){
sleep(1);
}
}
这里提交400K内存的申请,并且在每页中都进行内存的使用。可以看到不映射文件的话触发的是minflt次数是100次。
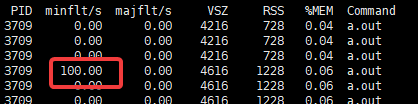
这里是mmap内存的惰性加载,一开始mmap100页时其实都没有分配给进程,在用到的时候开始真正拿到内存,此时触发minflt缺页中断,但是不用从磁盘中调内存,所以是小错误。但是仍是消耗性能的。brk则不会导致缺页。
如果mmap是映射的磁盘文件,也会惰性加载,在初次加载或者页被逐出后再加载的时候,也会缺页,这个时候就不是小错误minflt了,而是majflt,这里不再展示代码,因为下面提到零拷贝的时候会再讲。
4.3 共享内存
共享内存是进程间通信的一种方式,(管道 信号 信号量 套接字也是进程通信的方式)。共享内存的例子比比皆是,windows下最明显,比如这个上传文件的对话框就是共享内存里的,同一时间windows下不会弹出两个该对话框。再比如动态链接库,也是共享内存中的,多个进程可以共享,两个进程mmap相同文件的方式可以实现共享内存,shmget则是更广泛的共享内存的系统调用。
共享内存原理就是两个进程中页,映射到了相同的帧。代码这里不写了,直接参考https://www.geeksforgeeks.org/ipc-shared-memory/。
4.4 零拷贝
mmap、sendfile和splice是常见的零拷贝的系统调用。说道零拷贝,就要提一下用户态和内核态、用户空间和内核空间。内核空间就是4章第一个图中的高位的kernel的那部分内存,其他部分是用户空间。而内核态指的是一种状态,就是把cpu掌控权交给内核。
为什么要有内核态呢?因为所有的设备都不允许用户直接控制,包括内存条、硬盘、甚至是屏幕、usb外设。都是需要内核统一控制的,如果用户程序想用这些设备必须进入内核态。有三种方式进入内核态,中断、异常和系统调用。中断和异常界限不是特别明显,上文多次提到缺页异常(有时候也叫缺页中断)就是用户态进入内核态的一种。系统调用上面也提到过了,mmap、brk这些都是系统调用,比较熟悉的比如read/write/select/poll/epoll也是系统调用。
mmap的作用第一个是将文件映射到内存中,映射的区域是堆和栈之间的lib区,是用户空间的一部分内存。这时候我们其实通过系统调用将硬盘的内容直接放到了用户空间中,当然了在初次访问或者被逐出后的初次访问时,仍旧会触发缺页,导致读取很慢。但是在页填充好之后的读取是很快的。但是前面说过只有内核有资格直接和文件交互,所以其实这里映射到用户空间的这部分物理内存,在内核中同时也做了映射,即用户和内核共享了这部分物理内存(注意不是虚拟内存)。
通过read这个系统调用读文件(fread是read封装好的库函数),是将文件内容读到内核空间,再从内核空间拷贝到用户空间,这个过程中,对文件的读写,必须经过内核空间,所以需要频繁的内核空间和用户空间的拷贝。用MMAP可以将文件直接映射到用户空间内存,省去了拷贝,所以mmap是零拷贝的一种实现形式。
上面一直说的是文件,其实linux下一切皆是文件,网络接收数据的套接字也是文件描述符fd。
例如我们读取文件再通过网卡发送的过程中,其实是有磁盘IO和网络IO本就是很慢的,再加上多次的拷贝。所以这种场景下一般都用零拷贝来搞,一般使用的是支持scatter/gather的DMA控制器,外加sendfile系统调用来做到最少次数的拷贝和状态切换。
mmap可以简单的把文件和网卡都映射到用户空间,并像操作普通内存一样实现转发。但是不确定的缺页异常触发会使得性能不好评估。sendfile则针对性的进行了函数上的简化,为“零拷贝”而生。
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
按照维基百科的说法“零拷贝协议对于网络链接容量接近或超过CPU处理能力的高速网络尤其重要。 在这种情况下,CPU几乎将所有时间都花在复制传输的数据上,因此成为瓶颈,将通信速率限制为低于链接的容量。”
在这篇文章中,解释了普通read/write、sendfile和mmap实现上面网络转发场景的详细过程。