概述
- 数据:从类似的网站爬下来(https://www.linuxcool.com/)
- 后台:使用免费的netlify或者heroku,数据库用免费的MongoDB。
- 前端:web有点腻了,做小程序端和electron吧。
数据
我们需要拿到的数据有:指令名称,指令语法,参数实例。json结构如下:
{
"name":"ls",
"usage":"ls [选项] [文件]",
"params":[
{"param":"-a","explain":"显示所有文件及目录"},
{"param":"-l","explain":"使用长格式列出文件及目录信息"}
]
}
看下页面构造,总结以下结论
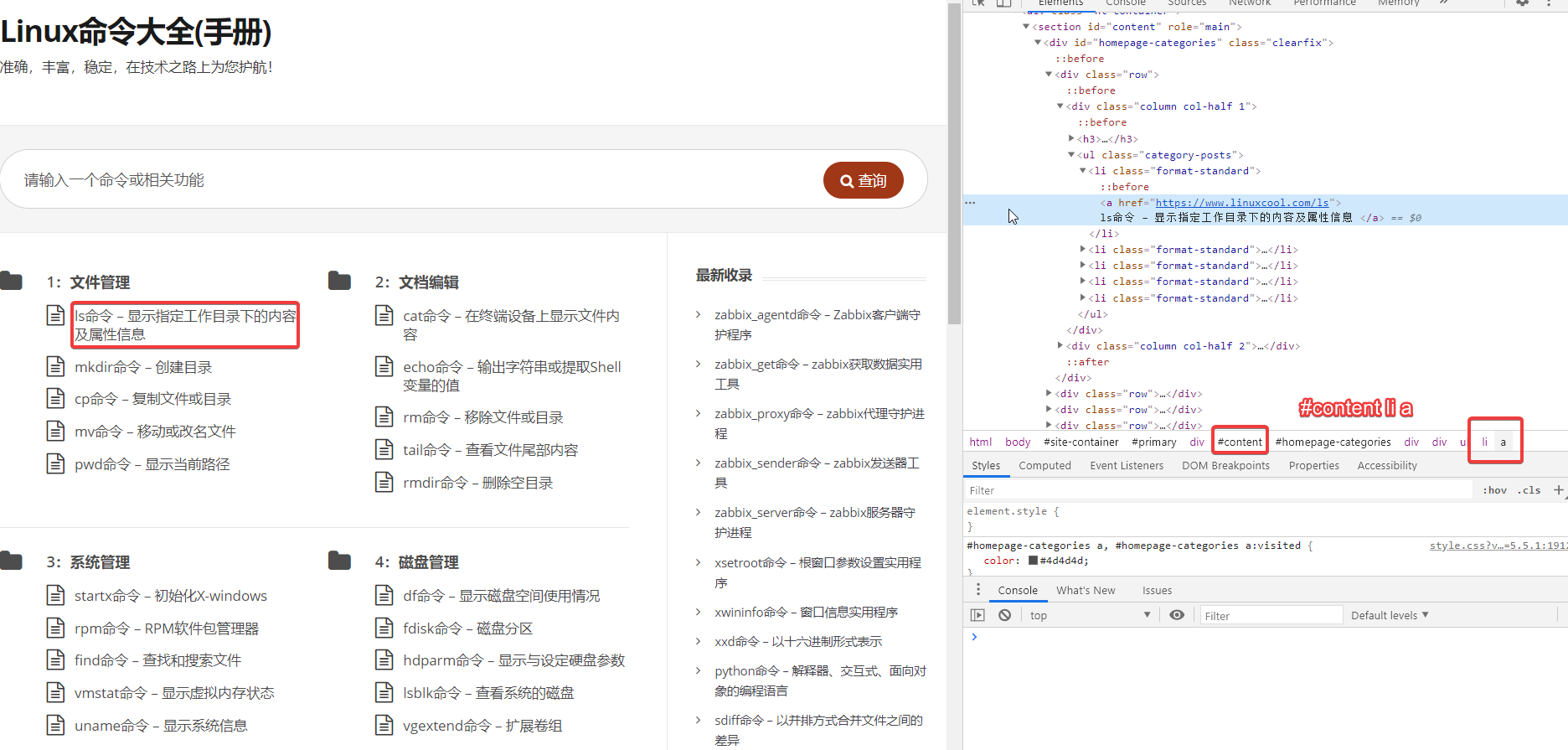 首页的指令直接通过
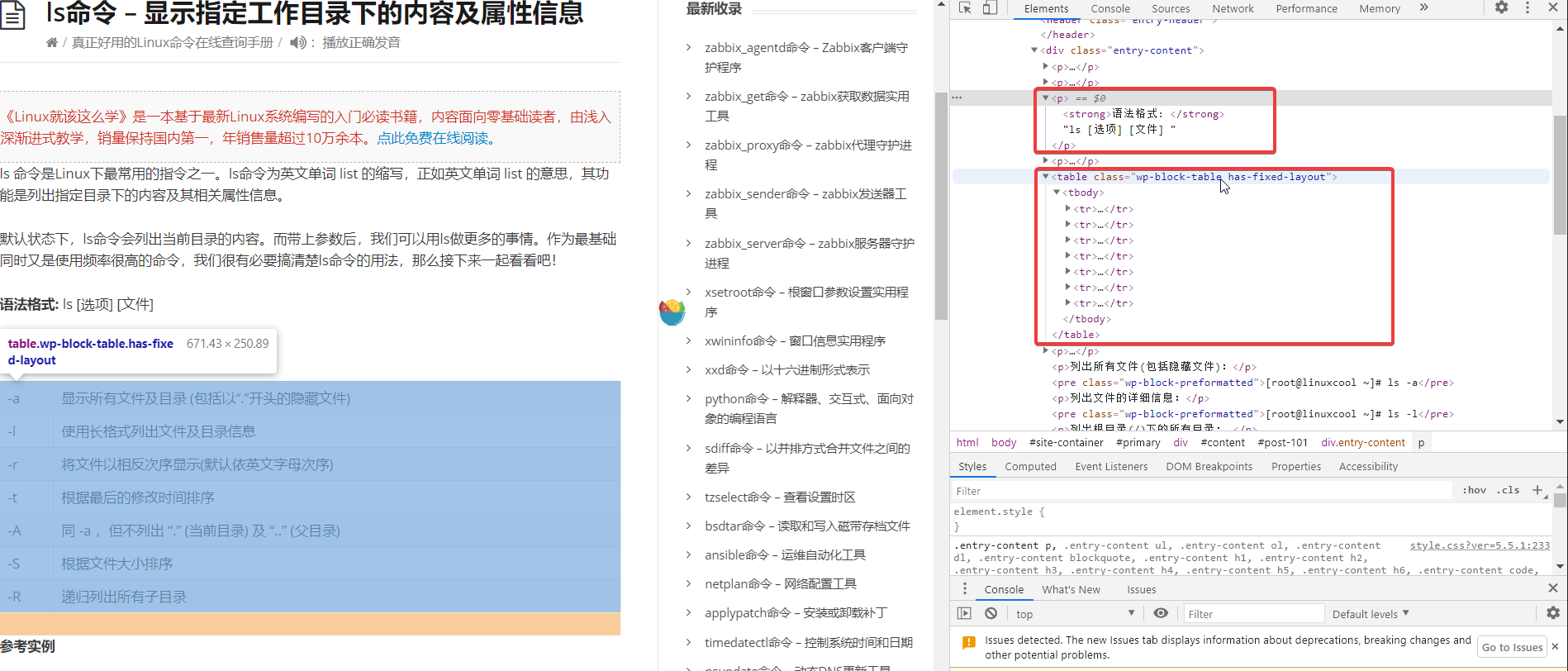
首页的指令直接通过section li a能拿到对应的元素,然后这个href属性就是需要打开的详情页,且href最后是指令名。通过href打开新的页面后,.entry-content中含有strong标签,且内部含有"语法格式"的后面就是语法说明,继续往下table标签中就是各种参数的用法,每种用法是tr td中的内容。
这个页面爬虫非常简单,可以用很多种方式来爬,这里搞三种吧:
- python Requests+xpath
- nodered 页面点击直接爬
- 浏览器 直接在console爬
1 python
安装python,安装requests xpath。
pip install requests lxml
电脑没装python,直接用之前numpy视频下载的jupyter镜像了,发现没有lxml,先安装一下。