XML Path Language
xml路径语法,xml是常见的一种序列化方式,html页面就是一种xml。学习xpath可以使用其快速定位xml元素。
基础语法
首先打开http://xpather.com/,这个页面是一个很好的学习xpath语法的页面,上方的输入框可以输入xpath语法,过滤出来的元素会高亮,并在右侧显示。
选取节点:
- . 表示当前节点,默认从最根部开始
- .. 向上翻,即父节点
- / 一级子节点,app/xx 表示app下的一级子节点中的xx元素
- // 子孙节点,app//xx 表示app下所有的xx元素
- * 匹配任意类型节点,app/* 表示app下所有节点(不含app)
- [] 过滤节点,匹配多个节点时用[1]表示第一个,注意下标是从1开始而非0
例如选取 第一个extra-notes下的一级子节点中的第二个note元素,就可以这么写:
//extra-notes[1]//note[2]

选取属性和文本
- /@ 拿属性,app/@name 表示获取app元素中的name属性值.
- //@ 拿属性,app//@name 表示app及以下所有元素中的name属性值
- [@xx='aa'] 过滤属性xx值是aa的节点。
- /text() 获取当前元素下的文本
- //text() 获取当前元素和子元素下的文本
- [text()='hh'] 获取文本内容是hh的元素,
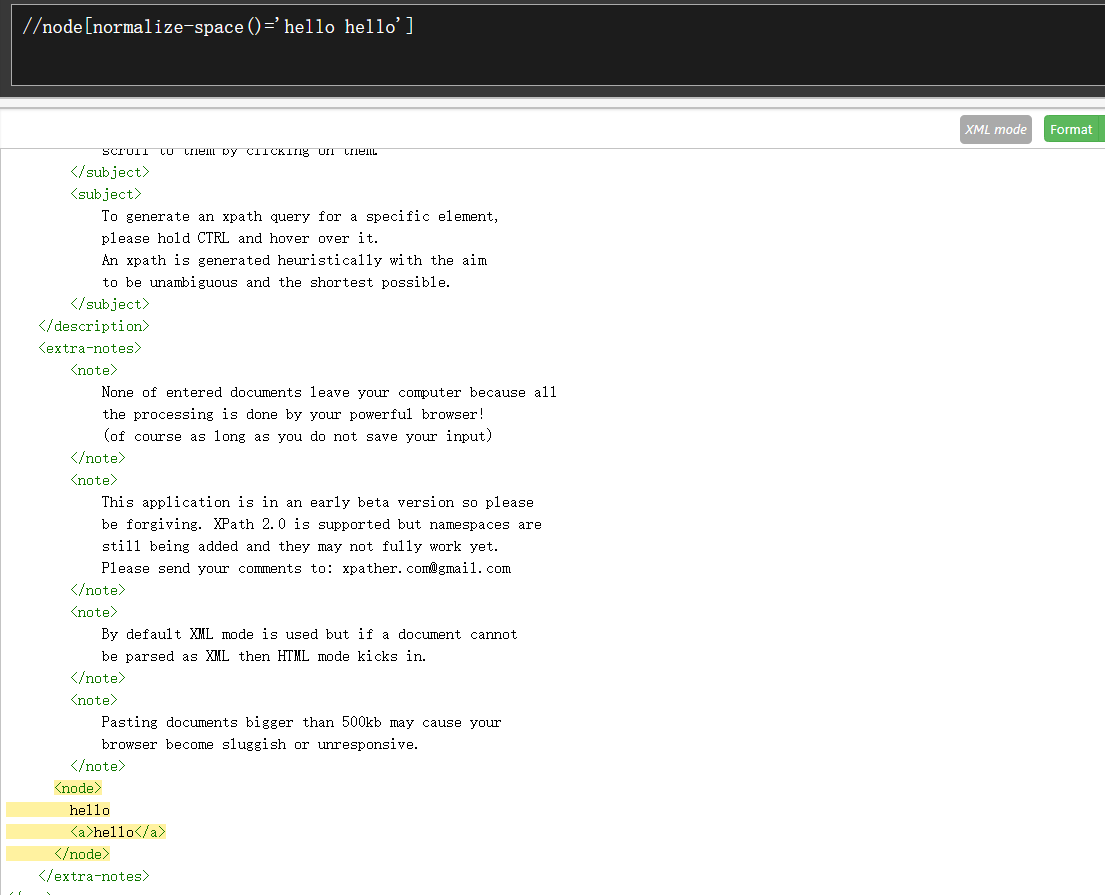
- /normalize-space() 获取当前元素的内部文本去掉空格。经常hh前面有空格,导致匹配不出来可以使用//*[normalize-space() = 'hh'],注意该函数修饰的节点如果有子节点文本是拼起来用空格隔开的。
常见的函数(除了上面的text normalize-space)
- name() 标签名
- contains 文本包含,//*[contains(@name,'Fra')] name属性包含Fra的节点
- lower-case 小写,//*[contains(lower-case(@name),'fra')]
- starts-with/ends-with //*[starts-with(text(),'Fra')]
- node 所有节点,/a/node() 等价于 /a/*
- child::node() 子节点。
- parent::node() 父节点 等价于..
- ancestor::node() 所有祖节点,父,祖父...
- count 求表达式选出的节点数 count(//app)