字符
不同语言中基本都会提供一个基础的字符类型char,但是不同语言的char的编码和内存占用是不同的。
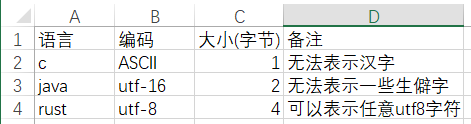
ASCII是最基础的字符编码,c语言中的char就是基于ASCII编码的,一个char只有1个字节,表示范围也只是ASCII范围内的所有字符。
Unicode是一个字符集,他收录了全世界各个国家的字符,甚至包括表情,utf8/utf16是使用了Unicode字符集的编码方式,两者都是变长编码,utf8一个码元长度是1字节,最短1字节,最长是4字节。utf16码元2字节,最短2字节也就无法兼容ASCII编码了,好处是绝大多数字符都可以用1个码元表示,极少数用2个码元。
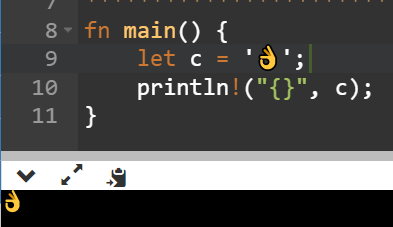
这么看下来除了rust,其他大多数语言的char都是不能表示所有的字符的,例如👌这个表情
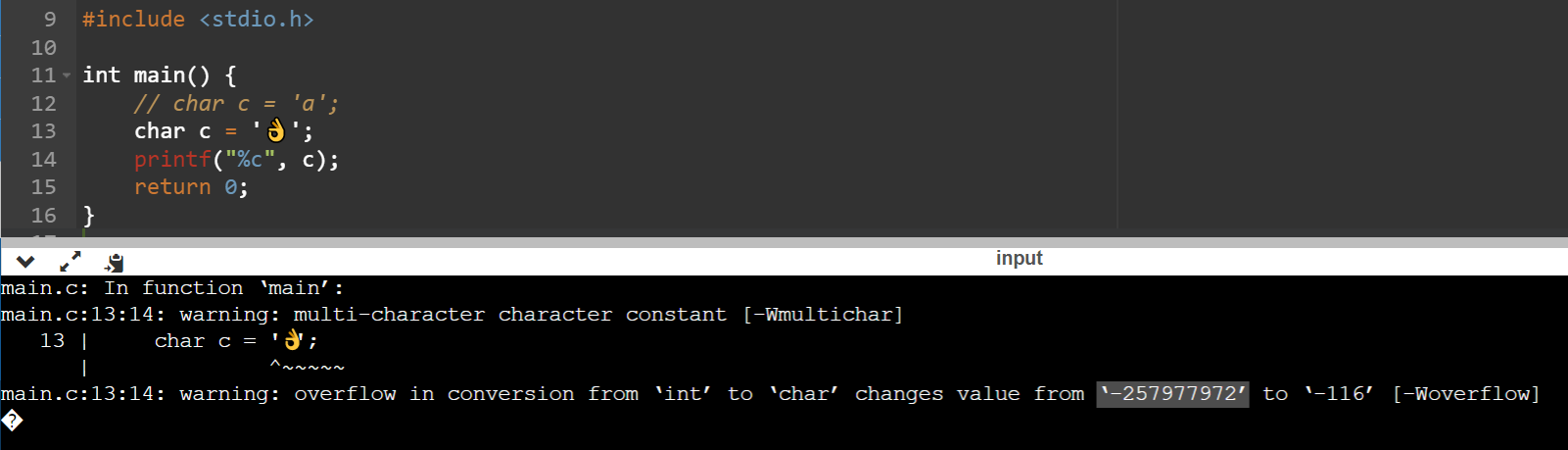
在c语言中会有个警告表示这玩意是一个int(4字节)能表示的东西强转成char就成了-116,所以打印的东西也不对了。
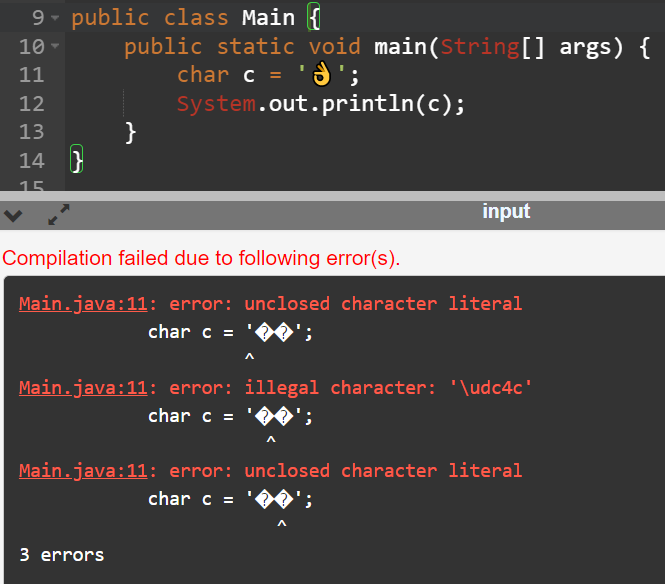
java中一个char是2字节,也就是utf16一个码元范围的字符也没有这个👌,他是2个码元才能表示的,所以编译就报错。
而rust中一个char是4字节,完整的utf8编码映射都能表示,因而毫无压力。
那如何在java语言中使用这些字符呢?
使用字符串,多个char来表示就行了。
字符串
字符串就是多个字符组成的串,一般的实现方式就是char数组,例如c语言中没有专门定义string结构体,直接用char[]来表示string,以\0标识字符串的结尾。
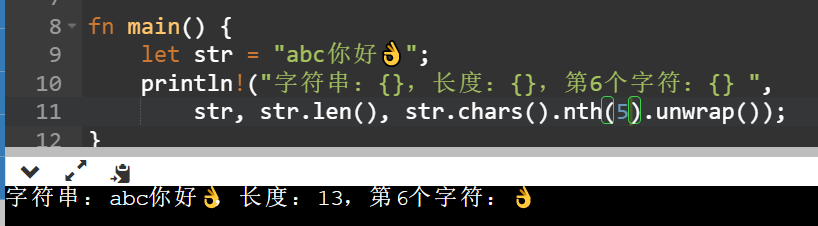
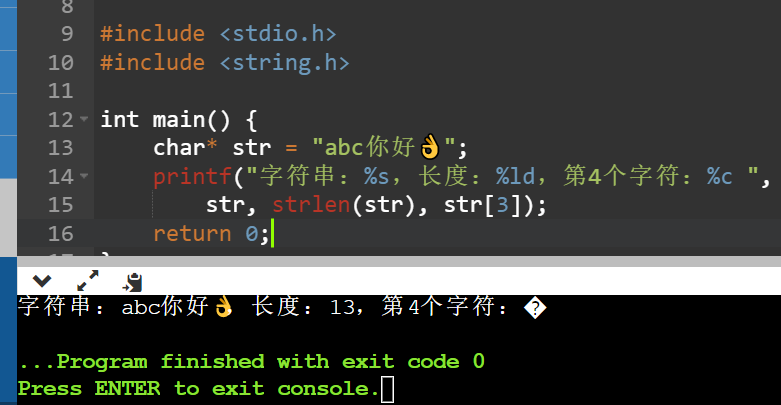
C语言的字符串使用utf8编码,汉字一般是3个字节,👌是4字节,所以下面长度是13,其实并不是我们理解的6个,而是字节数是13。
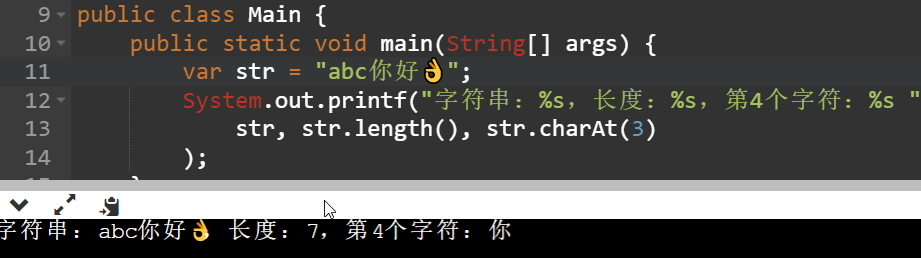
java有String对象,String本质上是包了个char[],一般对于一个字符来说用2个字节还是一个字节区别不大,但是字符串都用两个字节,在全是字母文字的语言,像英语中就很亏,他只用一个字节就能表示的自付范围,现在每个字符都是2个字节,像"abc"实际就要使用6个字节,内存就比较浪费。jdk9之后String中不再是char[]而是byte[],并且coder字段标识是latin1还是utf16,如果是latin1则在字符串内一个byte表示一个字符,utf16则是2个。
可以看到同样的字符串java中求出长度是7,abc和中文你和好utf16都是一个码元就能表示,都算一个长度,而👌需要用2个码元,所以占2个长度。
rust有String结构体,他的底层是u8数组,和C语言类似,单纯的求长度也是返回字节数,而不是我们理解的长度,rust没有使用char数组在string中,因为char在rust中是定长4字节的utf8,直接用char[]的空间利用率太低了。最终string是变长utf8编码,底层用u8数组。换句话说rust的string其实和char没啥关系。只是通过chars()可以转为我们熟悉的char的集合来操作,直接用切片则切出u8。