http
这里以目前最常见的http 1.1协议为例。
http协议是基于tcp协议的上层协议,交互方式是客户端请求服务端,然后服务端响应客户端的方式。
request & response
request和response都是有两部分组成,header和body,也就是说http的所有内容要么存放在header中要么存放在body中。
例如我们在本地搭建了http服务器,并进行抓包,查看http的请求和响应的内容,使用curl请求我们的服务。
首先进行get请求的测试:
curl http://localhost:1880/test?a=1
可以看到http的request实际上是明文的数据包,20是空格,0d 0a是\r\n也就是换行。
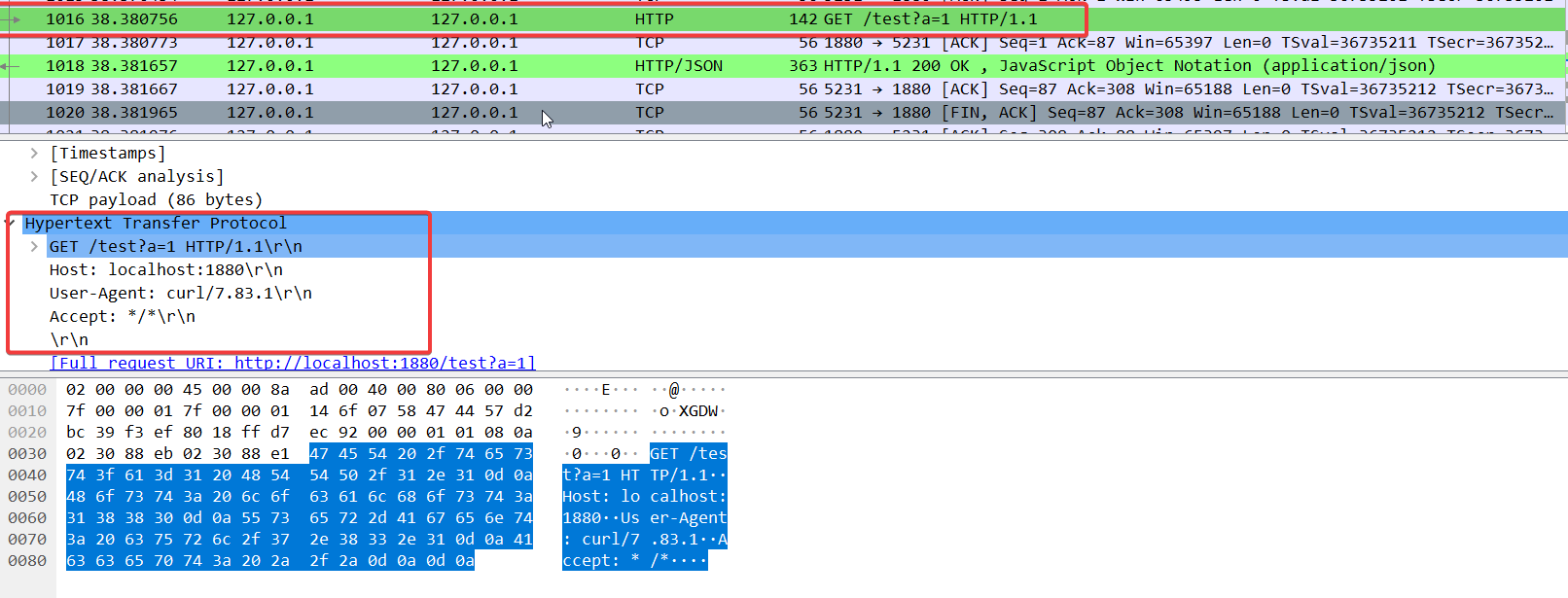 所以其实这个get请求是向1880的tcp端口发送了如下字符串:
所以其实这个get请求是向1880的tcp端口发送了如下字符串:
GET /test?a=1 HTTP/1.1
Host: localhost:1880
User-Agent: curl/7.83.1
Accept: */*
因为我们的get请求中没有body所以看到的都是header部分的内容,header的内容声明了请求的方式是get,路径是/test?a=1,协议是1.1版本的,然后从第二行开始,是header中的k: v列表,默认curl会添加三个header,分别是Host, User-Agent和Accept。最后一个k后面需要跟两个换行符,用于标识接下来的部分是body部分,不过因为我们无body,所以两个换行符后结束。
同样观察response的抓包情况:
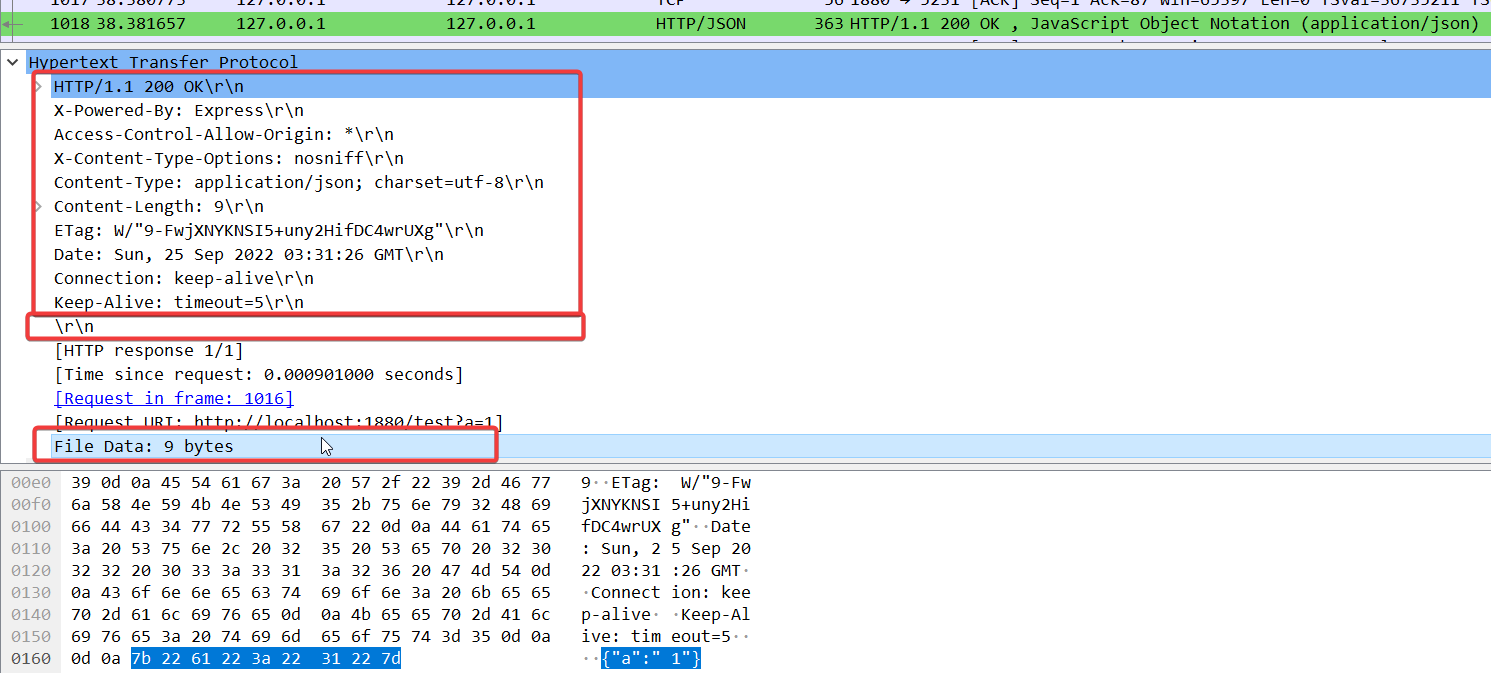
response是像发起请求的客户端端口5231发送了明文数据:
HTTP/1.1 200 OK
X-Powered-By: Express
Access-Control-Allow-Origin: *
X-Content-Type-Options: nosniff
Content-Type: application/json; charset=utf-8
Content-Length: 9
ETag: W/"9-FwjXNYKNSI5+uny2HifDC4wrUXg"
{"a":"1"}
第一行声明协议版本是1.1,状态码和状态描述是200 OK,从第二行开始就是response header中的k: v了,其中有一条重要的Content-Type声明了是json形式,这也就告诉了客户端该用json的反序列化方式处理body中的内容,之后直到出现两个换行符,后面File Data: 9bytes,这个是body部分,点击这行会看到对应的真实数据是字符串 {"a":"1"}(9个字节)。
Content-Type
Content-Type在request和response中都有重要的作用,他标识了body中的数据该如何去解析。
例如我们经常使用的http传参方式有:
- 1 路径传参 /user/1
- 2 查询字符串传参 /user?id=1
- 3 body传参之 form格式传参
- 4 body传参之 json格式传参
其中1 和 2可以直接解析request header中的路径部分就能解析出传参。而3和4则需要添加body内容。
json形式只需要指定Content-Type是application/json,并将json格式的合法字符串放到body中就可以了。
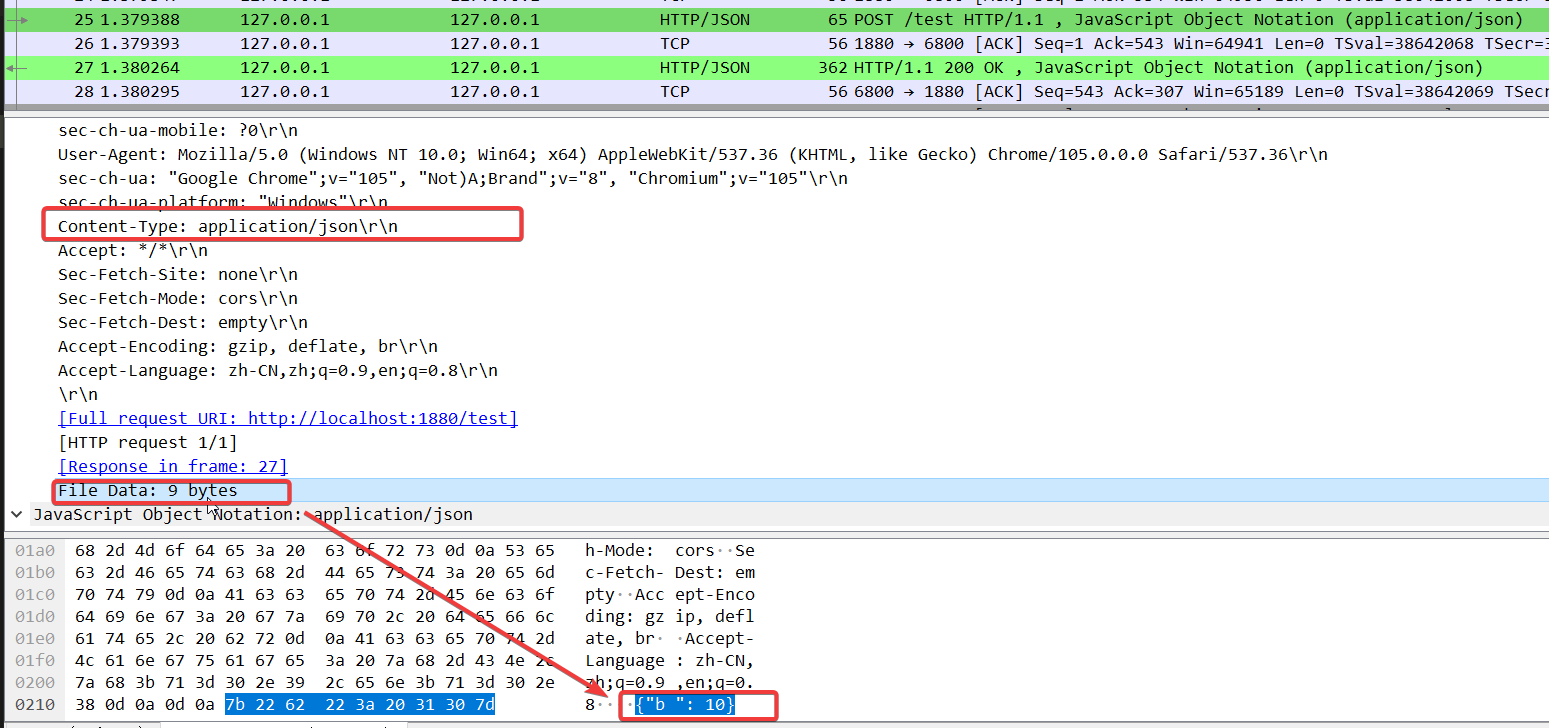
form形式则需要指定Content-Type是``,并且body中的内容需要是查询字符串格式:
web框架
web框架要做的最基本的事情就是解析请求的内容,返回相应的数据。所以一般都会将上面的几种传参方式的解析,封装为一个简单易用的方法。
比如查询字符串、json等形式的反序列化,应该是用户不关心的细节,需要封装在sdk中。再比如cookie是header中的一个常用的key,并且有着自己的序列化方式,最好也封装为方法。
给个例子比如getHeader getBody是最基本的接口,然后提供getQuery getPath getForm getJson getCookie等方法,方便用户使用。
以轻量级web框架warp为例,他主要提供了这些模块:

扩展
很多重量级web框架在上述功能的基础上还进行了很多扩展,例如日志系统,数据库ORM框架,MVC框架,security框架,缓存系统等等。
对于小应用来说基础的轻量级web框架是更合适的,但是组织较大的项目,则需要在这基础上添加额外的中间件,或者直接用重量级的web框架。