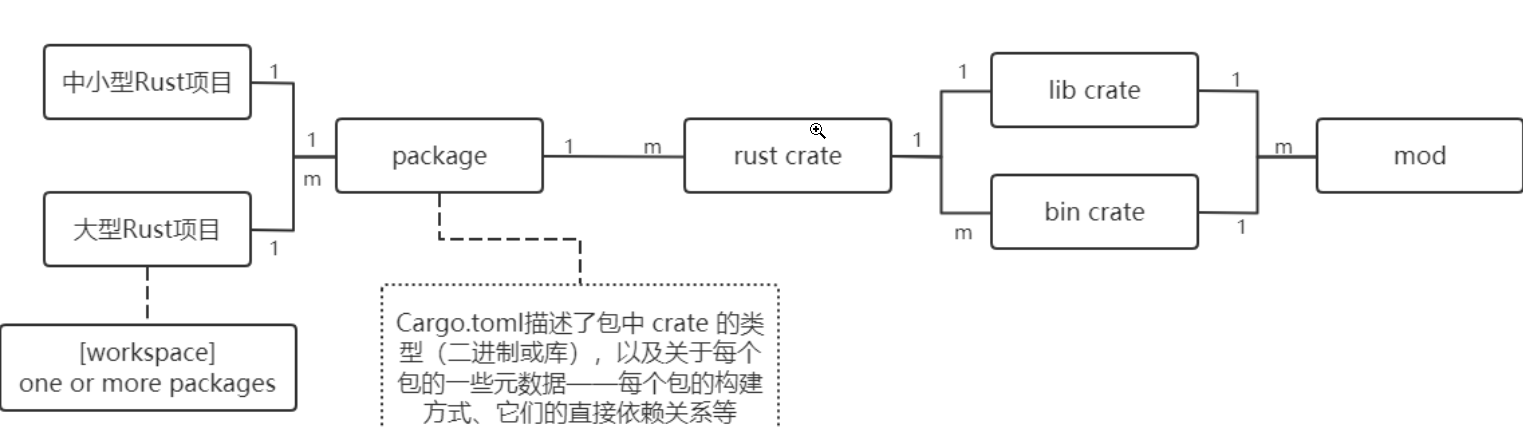
一、项目(pakage)包(crate)和模块(module)
cargo new出来的项目就是一个package,一个package下面可以放多个二进制包crate和一个库包lib,而每个包中又可以含有多个模块。
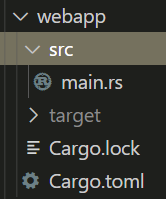
以我们最简单的cargo new webapp为例,默认会创建二进制包的项目,目录结构如下,toml文件类似pom.xml记录了依赖的其他crate,而src/main.rs是二进制crate的入口,里面的main函数是整个项目的入口函数,这也是之前学习基础知识的项目结构。
拆分模块的几种方式
只有一个main.rs显然不行,因为我们需要把功能进行拆分,放到不同的文件或者目录下面,而非全部塞到main中。所以就有了mod。mod本身就是个关键字,我们可以在main函数中就地声明mod,mod中可以像正常一样的去声明结构体,函数等数据,也可以嵌套mod。只不过mod中的数据需要是pub修饰才能被其他文件访问。
// mod名字需要是驼峰
mod a {
fn hi(){println!("hi a");}
pub fn hello(){println!("hello a");}
mod b {
fn hi(){println!("hi b");}
pub fn hello(){println!("hello b");}
}
pub mod c {
fn hi(){println!("hi c");}
pub fn hello(){println!("hello c");}
}
}
fn main() {
// main中只能访问pub的a::hello和a::c::hello,要c和hello都是pub
// a不需要pub,因为他就是当前文件可见的
a::hello();
a::c::hello();
}
1 main.rs中声明mod
将mod移到专门的文件/文件夹中,src/main.rs是二进制包入口文件,同目录下的其他rs文件同样也会参与到编译中来,最简单的分离代码方式就是在main.rs中声明mod,但不写mod内容,直接分号结尾,mod a;,然后在同名的rs文件中写具体的内容,将上面代码进行稍微改动拆分成俩文件,如下。
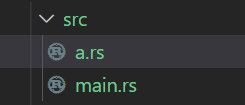
// src/main.rs
mod a;
fn main() {
a::hello();
}
mod a;声明了a.rs里的内容都作为mod a里的内容,同时将a模块引入到当前文件,所以不需要在写一遍use crate::a;而如果想特定的引入a中的某些元素,则可以追加一行use crate::a::hello;。
// src/a.rs
pub fn hello(){println!("hello a");}
2 单独的目录
创建目录可以更好的组织文件,mod也可以放到一个目录下面管理,其实文件和文件夹在rust中都是mod,只不过文件默认就是引入自己,文件夹默认会找文件夹下mod.rs文件。
创建mod1目录,并在main中声明引入mod1:mod mod1;,此时mod1中内容被引入到main,而mod1是个目录,如果是目录的话只能引入该目录下mod.rs,而这个文件是引入当前目录的a.rs和b.rs作为包a和b。于是我们在main中通过mod1::a::hello调用。
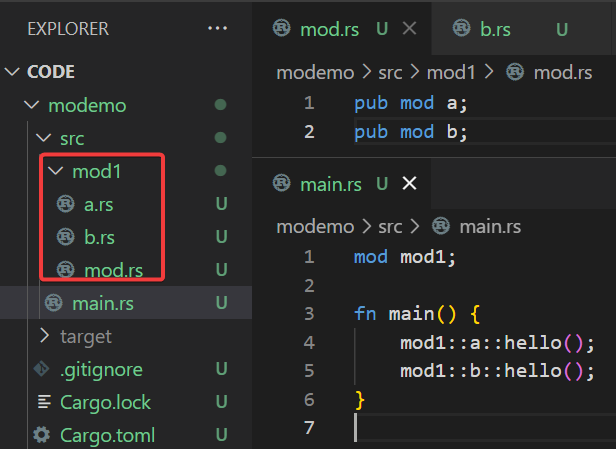
如果我们想在一个mod中调用另一个mod的元素,可以通过use crate::xxxx引入另一个mod的内容,例如上面的b.rs可以引入a.rs中的函数。
// src/mod1/b.rs
use crate::mod1::a;
pub fn hello(){println!("hello b");}
pub fn hello_a(){
a::hello();
}
a.rs与a/mod.rs
上面说了,引入mod mod1;,会找当前目录下mod1.rs或者mod1/mod.rs,我们可以使用mod1.rs和mod1/a.rs来实现上面同样的效果,只不过有点怪。此外如果两者同时存在,并不会报错,我看到的效果是mod1/mod.rs生效。
二、常用库的介绍
1 serde与serde_json
serde = { version = "1", features = ["derive"] }
serde_json = "1.0"
序列化的支持库serde提供了序列化的trait,具体的实现则需要自己实现,或者引入其他库,例如json的序列化实现serde_json。
#[macro_use]
extern crate serde; // 这两行代码作用:serde中声明的宏,在当前文件直接使用,不用加前缀
fn main() {
#[derive(Debug, Serialize, Deserialize)]
struct User {
#[serde(rename="uid")]
id: u32,
name: String,
is_male: bool,
}
// 下面是基本的json序列化与反序列化,注意反序列化User类型必须显示写,不然不知道要反成哪个类型。
let u = User{id:1, name: "liming".into(), is_male: false};
let str = serde_json::to_string(&u).unwrap();
println!("{}", str);//{"uid":1,"name":"liming","is_male":false}
let u2: User = serde_json::from_str(&str).unwrap();
println!("{:?}", u2);
}
注意,反序列化可能会遇到json字段值为null的情况,在rust中没有null,对应的策略是,该字段类型需要是Option<xx>类型。有时候json结构负责我们想从中抽出某个值,这时候就有非常方便的Value类型,他有点像fastjson中的JsonObject。
// json!宏可以快速将一个json结构体,转为Value类型。上面的from_str,我们也可以显示的声明为Value类型。
let v: Value = json!({"a": {"b": [{"c":1}, {"c":2}]}}); // 这里面可以用null, null是serde_json中的
// println!("{:#?}", v);
println!("{}", v["a"]["b"][1]["c"]); // 2 // 如果没有,比如b改为dcfdsafdsaf,返回null
r#"xxx"#原生字符串,xxx是不用转义的字符串,例如"等直接写即可,此外该语法可以支持多行文本非常方便。
let v: Value = serde_json::from_str(r#"
{
"txt": "12345"
}
"#);
2 mysql、rbatis
2.1 mysql
mysql是最常用的数据库,虽然国外sqlite和postgresql也很常用,但是目前国内形势还是mysql最常用。下面来看rust访问mysql。rust中的sql相关的库非常多,例如sqlx等也是非常优秀的库,但是这里我们只选了这三个mysql、mysql_async和orm框架rbatis(国人写的文档很友好)。如果windows上使用的话可能需要安装一些支持下载链接。然后我们需要准备一个mysql数据库,这里我使用xampp集成包,用户名root密码没设置,添加了rs库,并添加了一个user表,schema如图。

首先来看mysql的使用,mysql库有一些高级特性的使用因而需要使用nightly版本的rust。
rustup toolchain install nightly
rustup run nightly cargo r # 使用nightly版本来编译运行
虽然mysql依赖最新版本是22.x了,但是22.x中map的闭包中需要每个类型都实现FromRow,而时间类型NativeDateTime并没有实现,所以需要先用String接收,然后map函数中用parse_from_str转一下,所以我选择用20版本。
[dependencies]
mysql = "20"
serde = { version = "1", features = ["derive"] }
chrono = { version="0.4", features= ["serde"] }
首先创建一个User结构体,后面其他数据库连接方式也都用这个结构体
use chrono::NaiveDateTime;
#[macro_use]
extern crate serde;
// 注意字段可能为null的都用Option来表示,datetime类型就用NaiveDateTime
#[derive(Debug, Serialize, Deserialize)]
struct User {
id: Option<u64>,
name: Option<String>,
create_time: Option<NaiveDateTime>,
}
然后获取连接conn,后续的操作使用conn执行sql即可
use mysql::*;
use mysql::prelude::*;
fn mysql_test() -> std::result::Result<(), Box<dyn std::error::Error>> {
// 通过url创建连接池
let url = "mysql://root:@localhost:3306/rs";
let pool = Pool::new(url)?;
println!("get conn");
// 从连接池中获取连接
let mut conn = pool.get_conn()?;
...
Ok(())
}
conn主要是两类方法来执行sql,query_xxx和exec_xxx主要区别是前者是直接执行sql字符串,后者sql可以用字符串占位符,然后下一个参数指定参数。
query_drop: 写sql,例如,建表语句,因为不需要传入参数,可以直接用query,然后选择query_drop表示不接收返回的结果,insert和update也是一样,写操作不想接收返回值,就用_drop,如果不需要参数用update_drop就可以
conn.query_drop(
r"CREATE TABLE IF NOT EXISTS `user` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`create_time` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4")?;
conn.query_drop(
r"insert user (name, create_time)
values ('test', now())
")?;
query_map:读sql,需要接收返回的值的,可以用query_map来获取返回的数据,通过一个闭包来处理返回的数据。第一个参数是sql语句,第二个是闭包,闭包参数是个tuple,分别对应sql语句中选出来的字段顺序,闭包是对每一行数据的处理,并映射成一个结构体User后返回,最后得到Vec<User>,需要注意的是select返回的数据列数和闭包入参tuple的元素个数一定要匹配,不然会报错,注意这里没有把create_time也选出来,因为create_time是NativeDateTime,不能直接从Bytes("2022-10-..")转过来。
let all: Vec<User> = conn.query_map(
r"select id, name, create_time from user",
|(id, name, create_time)| User{id, name, create_time}
)?;
exec_drop和exec_map: 可传入参数的函数,与query用法类似,只不过可以传入参数。
let users: Vec<User> = conn.query_map(
r"select id, name, create_time from user where name=:name",
param! { "name" => "test" },
|(id, name, create_time)| User{id, name, create_time}
)?;
事务,从conn获取tx,接下来用tx执行sql操作,不要用conn了
```rs
let mut tx = conn.start_transaction(TxOpts::default())?;
tx.query_drop("CREATE TEMPORARY TABLE tmp (TEXT a)")?;
// tx.rollback();
tx.commit();
2.2 rbatis
上面的mysql库有几个问题,第一个是同步的IO,不太适合用在tokio组织的异步项目中,第二个是需要用nightly版本的rust,很多公司prod环境是不会用nightly版本的。所以也经常会看到有的项目使用的是mysql_async的库,这里我们不展开介绍mysql_async了,因为小项目用mysql也能应付,而大项目一般需要使用ORM框架,而rbatis是一个国人开发的ORM框架使用简单方便,文档也很友好。
[dependencies]
serde = { version = "1", features = ["derive"] }
tokio = { version = "1", features = ["full"] }
rbatis = { version = "4.0"} # rbatis
rbs = { version = "0.1"} # rbatis需要用的
rbdc-mysql={version="0.1"} # mysql驱动库
fastdate = "0.1.29" # rb自带的日期处理的话可能要用的库,不做一些转换用不到
rust中间接依赖的mod是没法在当前项目中使用的,比如rbatis依赖了fastdate库,但是如果我们项目只添加rbatis依赖,是不能直接使用fastdate中的内容的。
Rbatis用法如下,需要对声明的结构体User使用crud!这个宏进行增强,这里修改了日期类型直接用rb中建议的FastDateTime
#[macro_use]
extern crate serde;
#[macro_use]
extern crate rbatis;
#[derive(Clone, Debug, Serialize, Deserialize)]
struct User {
id: Option<u64>,
name: Option<String>,
create_time: Option<FastDateTime>,
}
crud!(User{});
#[tokio::main] // main方法上的宏,这个是tokio库对main函数的增强,使main可以加async修饰,并且main可以使用await,调用基于tokio的异步的函数
async fn main() -> std::result::Result<(), Box<dyn std::error::Error>> {
// 创建连接库rb
let mut rb = Rbatis::new();
rb.init(MysqlDriver{},"mysql://root:@localhost:3306/rs").unwrap();
// User结构体有增强方法可以直接使用
let all: Vec<User> = User::select_all(&mut rb).await?;
Ok(())
}
User的增强:
// 查
let all: Vec<User> = User::select_all(&mut rb).await?;
let all: Vec<User> = User::select_by_column(&mut rb, "name", "test").await?;
// 改,第二个参数是要改成的对象,第三个字段是根据第二个的那个列,下面sql:
// update user set create_time=now where name = test
// id可以设置为none 和 name 是数字字符串类型,update时设置为None,是不去修改这一列。
// 但是create_time不可以设置为none,不知道是不是框架的bug
let up_res = User::update_by_column(&mut rb,
&User { id: None, name: Some("test".to_owned()), create_time: Some(FastDateTime::now()) },
"name").await?; // up_res: ExecResult { rows_affected: 2, last_insert_id: U64(0) }
// 同时运行多个update语句
let up_res = User::update_by_column_batch(&mut rb, &[
User { id: Some(1), name: Some("111".to_owned()), create_time: Some(FastDateTime::now()) },
User { id: Some(2), name: Some("222".to_owned()), create_time: Some(FastDateTime::now()) },
], "id").await?; // up_res: ExecResult { rows_affected: 2, last_insert_id: Null }
// 插入 也有insert_batch,不做展示了
let in_res = User::insert(&mut rb,
&User { id: None, name: Some("111".to_owned()), create_time: Some(FastDateTime::now()) })
.await?;
// delet类似的不写了
再强调一下None在update的时候不是set成null而是保留原来的

rbatis也支持原生sql的执行
let u: Vec<User> = rb
.fetch_decode("select * from user limit ?",vec![rbs::to_value!(2)])
.await
.unwrap();
let r = rb.exec("delete from user where id > ? and id < ?",
vec![rbs::to_value!(5), rbs::to_value!(7)]).await?;
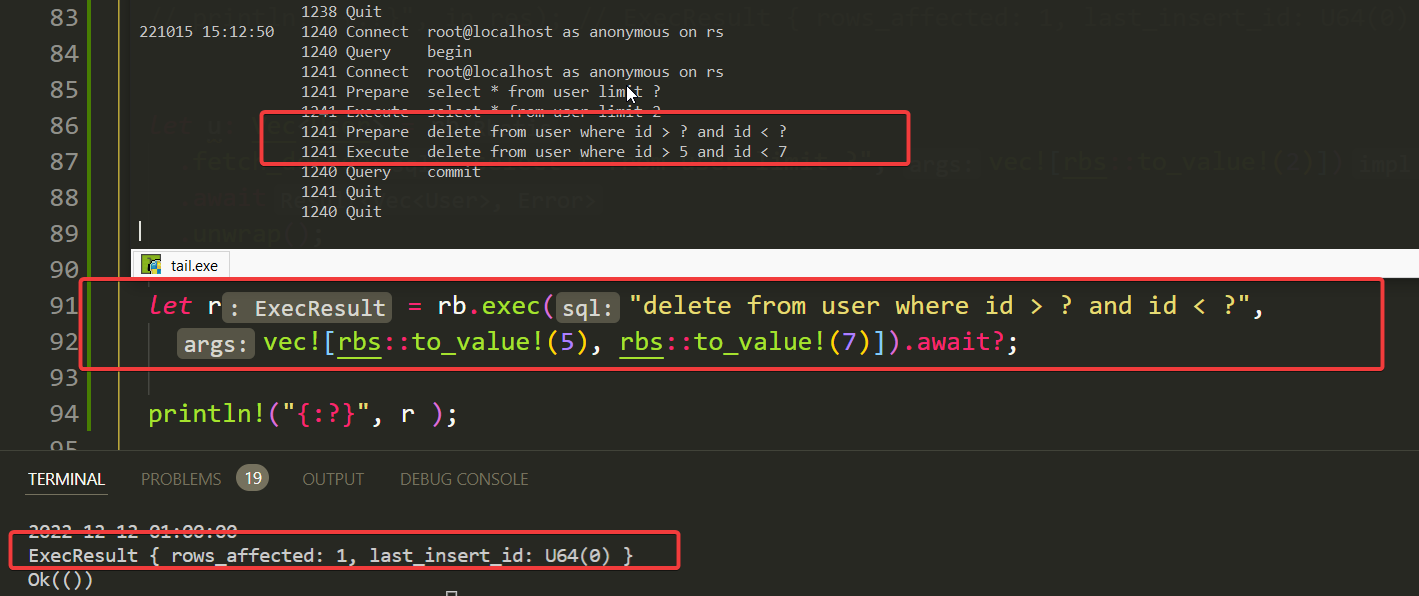
事务的使用
let mut tx = rb.acquire_begin().await?;
// ...接下来rb的操作都是事务中的
// tx.rollback().await?;
tx.commit().await?;
FastDateTime这个结构体的方法比较有限,相比于Chrono库来说,扩展性较差。是rb作者为了更简单的处理日期类型封装的一个结构体。下面列出了一些转换用法,我们可以以字符串为中介,来转换FastDateTime和Chrono
// 字符串 -> FastDateTime
let date = FastDateTime(DateTime::parse("YYYY-MM-DD hh:mm:ss", "2022-12-12 01:00:00")?);
// FastDateTime -> 字符串 (默认字符串格式是YYYY-MM-DD hh:mm:ss)
let s = date2.0.to_string();
// 字符串 -> NaiveDateTime
let cro_date = NaiveDateTime::parse_from_str(&s2, "%Y-%m-%d %H:%M:%S")?;
// NaiveDateTime -> 字符串
let s2 = cro_date.format("%Y-%m-%d %H:%M:%S");
3 reqwest
tokio = { version = "1=", features = ["full"] }
reqwest = { version = "0.11", features = ["json"] }
serde = { version = "1", features = ["derive"] }
serde_json = "1.0"
直接复用同一个client请求,使用的是默认连接池。client有get post等方法。
以send函数为分界,前面的是request的参数调整,如header,query等;send后面的是response的处理,例如最基本的转成text()的函数。
async fn req_test() -> Result<(), Box<dyn std::error::Error>> {
let url = "http://localhost:1880/get";
let client = reqwest::Client::new();
let txt_res = client.get(url)
.header("a", "b")
.query(&[("id", "1")])
.send()
.await?
.text()
.await?;
println!("{:?}", txt_res);
Ok(())
}
post的示例,将方法改成post,如果要传表单的话,添加form函数,参数与query一致。json参数则使用json函数,并且接一个结构体对象的引用即可,因为我们添加了json的支持,所以会自动将结构体序列化成json(结构体要加序列化反序列化的派生宏),例如下面是form和json的使用方式,json使用了前面数据库用的User结构体。
let txt_res = client.post(url)
.header("a", "b")
.query(&[("id", "1")])
.form(&[("f1", 1), ("f2", 2)])
.send()
.await?
.text()
.await?;
let txt_res = client.post(url)
.header("a", "b")
.query(&[("id", "1")])
// json会变成:{"id":1,"name":"li","create_time":null}}
.json(&User{id: Some(1), name: Some("li".to_string()), create_time: None})
.send()
.await?
.text()
.await?;
当然有时候我们不想单独声明一个结构体也可以用HashMap或者serde_json中自带的宏json!
let mut map = HashMap::new();
map.insert("k", "v");
...
.json(&map);
// -----------------------------
...
.json(&json!({ "kk": "vv" }))
返回数据的处理,上面都是用的text()转为文本,也可以直接序列化成对象(如果是json格式)
let res = client.get(url)
.header("a", "b")
.query(&[("id", "1")])
.send()
.await?
.json::<User>() // 如果返回的类型就是User,那res就是User类型
.await?;
但是有时候返回值是个很复杂的结构,我们只想并不想专门定义一个结构体。对于单层结构的可以使用HashMap<String,Stirng>,但是这个map仍然不灵活,比如如果有json的value是数字,反序列化就会失败,或者json不是单层而是多层嵌套,也会比较麻烦。比较好的解决方案可以使用serde_json的加持,比如我们可以用text()来拿到整个文本,然后使用serde_json::from_str将str转为非常灵活的Value类型。更简单的我们直接当做Value类型来接收:
...
.json::<Value>()
...
// 求 data.body.kk
// let kk = res["body"]["kk"]; body和body.kk任意一个没有直接panic,或者如下用get去慢慢处理。
let empty_value = json!({});
let kk = res.get("body").unwrap_or(&empty_value)
.get("kk").unwrap_or(&empty_value)
.as_str().unwrap_or("default"));
4 warp
与reqwest同一个作者写的web框架,非常轻量级,与rocket等不同。warp核心概念就是过滤器Filter。每一个请求来了就像进了一层层过滤器筛选,最后把符合条件的请求处理,然后结果返回。引入如下依赖
tokio = { version = "1", features = ["full"] }
warp = "0.3"
serde = { version = "1", features = ["derive"] }
serde_json = "1.0"
下面代码就可以启动一个监听9090端口的web服务器,并且get p1返回hello。我们主要做两件事,1声明一个过滤器,2将该过滤器作为服务启动。过滤器的各种规则是warp的核心,比如path!按照路径过滤,不符合p1路径的请求就被扔掉了,而warp::get是get请求的才留下,两个过滤规则用and方法连接表示同时满足p1路径和get请求的才会到最后的处理map函数中,返回hello。
use warp::Filter;
#[tokio::main]
async fn main() -> std::result::Result<(), Box<dyn std::error::Error>> {
let filter1 = warp::path!("p1")
.and(warp::get())
.map(|| "hello");
warp::serve(filter1)
.run(([0,0,0,0], 9090))
.await;
Ok(())
}
filter的接收参数
let filter2 = warp::post()
// 1 path!宏中使用 / type 可以接收路径参数,后续map中用string来接收。
.and(warp::path!("p2" / String))
// 2 query string中拿参数,map中可以用HashMap来简单的处理所有情况,或者Value或者结构体
.and(warp::query("a"))
// 3 post form的数据,也可以用HashMap来简单的处理,或者Value或者自定结构体反序列化
.and(warp::body::form())
// 4 post json的话,换成这个函数
// .and(warp::body::json())
// 5 header中获取指定的值
.and(warp::header("user-agent"))
// post /p2/abc?a=10 form: b=11 => xx:abc, query:{a:10} form:{b:11}
.map(|xx: String, query: HashMap<String, String>, form: Value, agent: String| {
return serde_json::to_string(&query).unwrap() + "\n"
+ &serde_json::to_string(&form).unwrap() + "\n"
+ &xx+ "\n"
+ &agent;
});
.map(|xx: String, query: HashMap<String, String>, form: Value| {
return serde_json::to_string(&query).unwrap() + "\n"
+ &serde_json::to_string(&form).unwrap() + "\n"
+ &xx;
});
filter的返回,上面见到的map函数,参数是过滤器中取到的一些参数的值,而返回值,上面的例子都是返回了一个String,其实返回的类型肯定也不能全是String类型,其实需要该闭包的返回值实现warp中的Reply trait。String实现了该trait,String的header中的contenttype是text/plain。
use warp::reply::*;
use warp::{http::Uri, Filter};
warp::path!("r")
.map(||{
// 1 json方法返回json数据 application/json
json(&my_obj)
// 2 html方法返回html数据 text/html (1和2 是最主要的两个返回reply的方法)
html(r"<h1>hi</h1>")
// 3 StatusCode结构体和String一样也是实现了Reply所以可以直接返回code
StatusCode::BAD_REQUEST
// 4 with_status方法 将code和reply拼起来(默认的reply是200)
with_status(html(r"<h1>hi</h1>"), StatusCode::BAD_REQUEST)
// 5 with_header方法 则是添加或替换response header内容
with_header(
with_status(html(r"<h1>hi</h1>"), StatusCode::BAD_REQUEST),
"my-h", "my-v")
// 6 跳转
warp::redirect(Uri::from_static("/v2"))
})
warp的serve函数只能接一个root filter,如果我们有多个路径需要被监听和处理,那可以将多个filter用or拼出一个root filter。
跨域:在filter最后加.with(warp::cors())
文件:let filter3 = warp::fs::dir("example"); 映射该文件夹,文件夹相对路径是项目根目录
到这里基本的用法已经了解差不多了,然而实际上我们一个web服务可能需要进行外部io,例如我们可能用前面的mysql或者reqwest进行其他的io请求。因为warp用了tokio框架所以最好其他的io我们也基于tokio,例如在warp中使用reqwest。
上面的请求处理都是在map的闭包中进行,而且都是同步的快速处理,如果map闭包中直接使用异步的reqwest肯定是无法使用的,因为最基本的await关键字就无法在非async函数中使用。then与and_then,then一听就是之后再怎么样,是异步的,map的函数我们也可以用then来代替
warp::path!("p3" / u32)
.map(|id|{
format!("{}", id)
});
// 替换成
warp::path!("p3" / u32)
.then(|id| async move {
format!("{}", id)
});
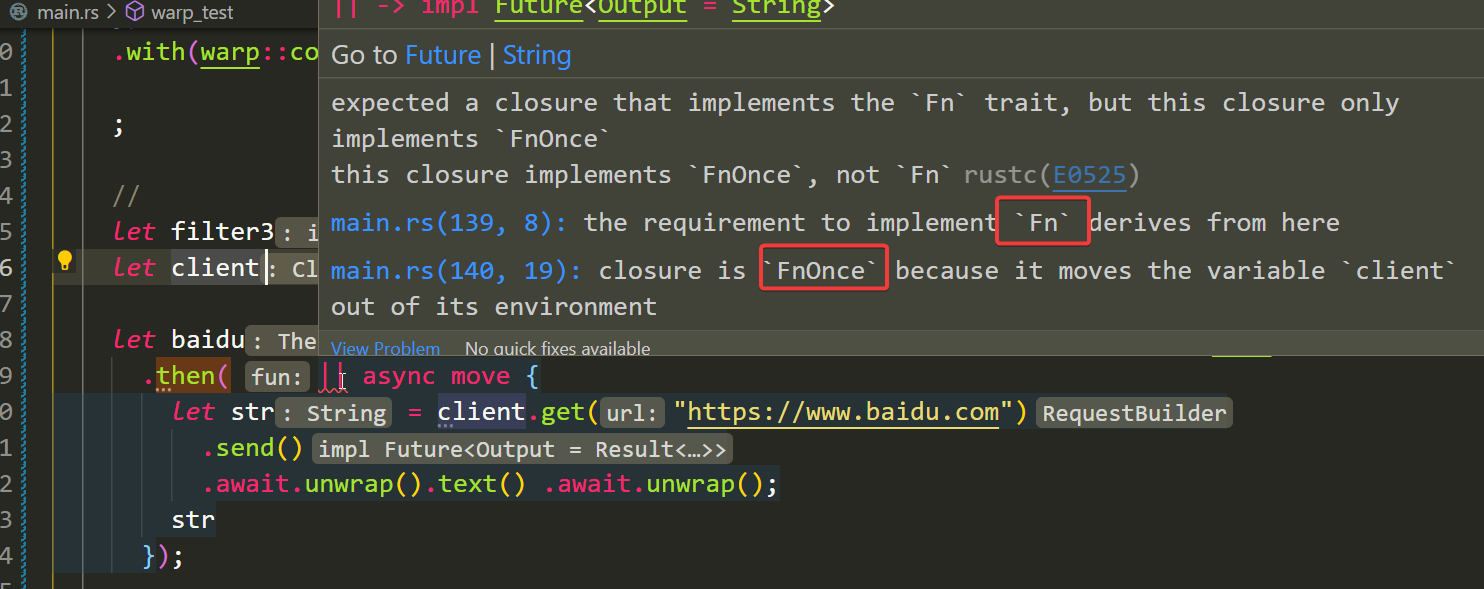
上面代码有个async move这俩是干啥的呢,而且我们发现他在闭包参数的后面,并不是修饰整个闭包是异步的函数。其实要分开说async{}是异步代码块,代码块是有返回值的,异步代码块返回值是Future。而then的参数定义中闭包需要返回Future,如下图。而move就比较简单了,他其实是获取id的所有权,因为是异步执行,可能传id的上下文已经结束了,所以想要使用id,必须move进来,如此一来我们就有了async了,那就可以在里面使用reqwest了
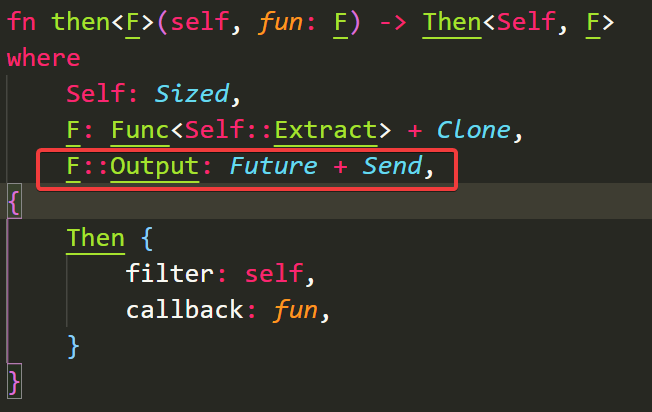
例如用reqwest请求其他服务
let baidu = warp::path!("baidu")
.then(|| async move {
let client = reqwest::Client::new();
let str = client.get("https://www.baidu.com")
.send()
.await.unwrap().text() .await.unwrap();
str
});
但是这么写还是有点问题,client在每次请求的时候都临时创建。直接把client移动到外面就会报错,因为从上下文中在直接拿到了client所有权,这个和参数约束不同,当然了我们拿到所有权也会导致client只能用一次了。也是不行的。