rust类型
rust的数据类型主要分为基础的数据类型像u8、i8、char等。还有复合数据类型结构体,元祖,枚举等。总体而言相比于java,是没有类,注解,接口的。因为没有接口实现接口化的编程就很难,所以提出了特征trait,特征有点像接口,但是又不太相同,特征本身其实不是一种类型而是一种约束,需要结合泛型来使用。
特征
例如我们想面向接口化编程,有个叫Api的接口,需要实现run方法,那么代码如下,这看上去除了需要把方法写在struct外面单独声明,其他的和java也没啥不一样,对吧。
trait Api {
fn run(&self);
}
struct Api1 {}
struct Api2 {}
impl Api for Api1 {
fn run(&self) {
println!("api 1 running");
}
}
impl Api for Api2 {
fn run(&self) {
println!("api 2 running");
}
}
特征参数
trait和java的interface最本质的不同还是trait不是一种类型,而是一种约束。例如java中参数的类型或者返回值类型可以是一个接口,表示实现了这个接口的任何类都可以。而rust中下面写法不对
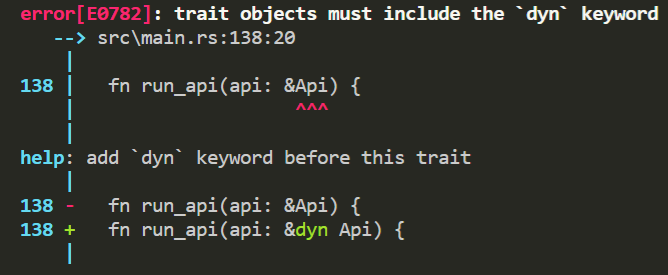
// Api不是一种类型所以下面写法报错
fn run_api(api: &Api) {
api.run();
}
报错信息如下,特征对象必须加dyn关键字,我们后面再说dyn,总之因为Api本质不是一种类型,编译报错,这和java是不同的。
trait是一种约束,他要和泛型配合,我们不断强调这话,来看下合法的写法吧,首先是最具有可读性的where写法,也最好理解,在这种写法中where表示对泛型类型T进行了约束,T必须实现了Api这个trait,where写法可以简化
// 以下三种写法完全等价
fn run_api<T>(api: &T)
where T: Api
{
api.run();
}
// 这种写法简单一些,但是如果有多个约束那么函数声明就会太长。适用于约束较短的情况,方便简单。
fn run_api<T: Api>(api: &T) {
api.run();
}
// 最后一种写法是一种语法糖,因为经常接口化编程的参数是trait约束,所以提供了这种不用写泛型的简单写法。实际等价于上面
fn run_api(api: &impl Api) {
api.run();
}
特征返回值
类似的我们很容易想到用特征约束返回值的写法。
fn gen_api() -> impl Api{
Api1{}
}
下面我们来看一段代码的报错
fn gen_api(num: i32) -> impl Api{
if num > 0 {
Api1{}
} else {
Api2{}
}
}
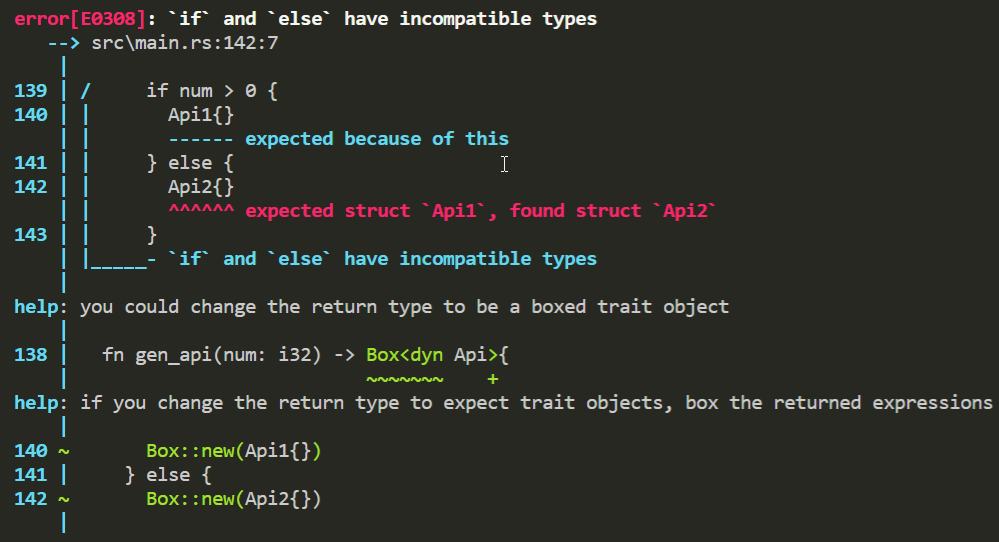
上面代码是我们直觉的写法,因为前面我们说trait不是类型,是约束的写法,但是rust提供了impl xx语法糖,我们好像可以拿来当类型一样使用了。但是作为返回值的时候,如果出现动态的返回又会出问题。也就是我们根据运行时的参数来决定这个函数是返回Api1还是Api2了。这样就会报错。
本质上泛型作为入参或者返回值,假如实现trait的struct有100种,rust编译时是会自己派生100个函数声明,所以运行时是运行了特定的某一个函数。这也叫静态分发。但是上面的情况是动态分发,rust无法派生代码,因为编译期无法判断类型。
我们把上述代码等价的where写法写出来可能更好理解,泛型T需要实现Api,rust可以派生返回类型是Api1和Api2的两个函数,但是任意一个函数都无法满足函数内部的动态类型返回。
fn gen_api<T>(num: i32) -> T
where T: Api
{
if num > 0 {
Api1{}
} else {
Api2{}
}
}
特征对象
这种情况下就需要借助dyn trait关键字,特征对象。特征对象是一种类型,注意他不是一种约束啦,而是一种类型,这种类型必须配合Box或者&来使用,也就是dyn出现必须是以下形式之一
Box<dyn Api>
&dyn Api
特征对象中存放了两部分内容,普通Box中也会存放的指针和vtable地址的指针,前面的指针部分指向内存中的结构体,vtable则指向了该结构体中实现了该trait的方法(并没有其他方法)。因为只存放指针所以大小是固定的。
特征对象作为函数入参,两种形式的用法分别如下。其中第一种写法,也是本文第一个错误提示中建议我们的写法。
fn run_api(api: &dyn Api) {
api.run();
}
run_api(&Api1{});// 调用
fn run_api(api: Box<dyn Api>) {
api.run();
}
run_api(Box::new(Api1{}));// 调用
特征对象作为返回值,返回值不要使用引用,所以只有Box这种写法如下,因为特征对象是有固定大小的类型,所以就可以动态返回api1或api2了。下面两种都是合法的写法。
fn gen_api_dyn(num: i32) -> Box<dyn Api>{
Box::new(Api1{})
}
fn gen_api_dyn(num: i32) -> Box<dyn Api>{
if num > 0 {
Box::new(Api1{})
} else {
Box::new(Api2{})
}
}
特征对象隐式的具有'static生命周期,Box<dyn Trait>就跟Box<dyn Trait + 'static>是等价的
如何选择呢
首先是如果是动态的返回值那就只有Box+dyn这一种合法的写法,不需要考虑别的。而对于静态的分发场景来看的话,trait约束本质是编译器派生多份代码,trait对象则是一个新的类型包含两个指针。前者会产生更多的代码,但是运行时的效率要更高。并且可以通过where条件来应对复杂约束场景,dyn只能指定一个trait。并且dyn有一定限制,必须是安全的对象才能使用,例如trait中有方法是返回Self的就认为是不安全的。
最后我个人想法还是能用impl trait就用,不行再考虑dyn。
泛型
泛型可以在结构体、枚举和方法中使用。java中枚举显然不能使用泛型,这也是一个重要的区别。使用时直接在类型名后面加<T>
// 结构体中使用泛型
struct Point<T,U> {
x: T,
y: U,
}
// 枚举中使用泛型
enum Option<T> {
Some(T),
None,
}
// 普通方法中使用泛型
fn echo<T>(a: T) -> T {
return a;
}
泛型结构体实现方法时有多种情况,例如
struct Point<T>{
x: T,
y: T,
}
impl<T> Point<T> {
// 普通的函数注入
fn hello(&self){
println!("hello");
}
// 使用了T作为参数或者返回值类型,注意函数后面不要再加<T>
fn set_x(&mut self, x: T){
self.x = x;
}
// 与T无关的其他泛型函数
fn echo<U>(&self, v: U) -> U{
v
}
// 既使用了T又新引入了U的函数
fn set_x_and_echo<U>(&mut self, x: T, v: U) -> U{
self.x = x;
v
}
// 用trait约束泛型,既可以对U约束,也可以对T约束
fn set_x_and_echo_with_trait<U>(&mut self, x: T, v: U) -> U
where U: Clone,
T: Clone + Copy
{
self.x = x;
v
}
}
对于有约束的函数例如上面的set_x_and_echo_with_trait我们对T有Clone和Copy的约束,而如果我们生命的Point中T是String(没有实现Copy),如下面代码,调用set_x_and_echo_with_trait报错,说String没实现Copy,所以不能调这个方法。
fn main(){
let mut p = Point{x: "1".to_string(), y: "2".to_string()};
p.set_x_and_echo_with_trait("3".to_string(), 1);
}
error[E0277]: the trait bound `String: Copy` is not satisfied
--> src\main.rs:153:7
|
153 | p.set_x_and_echo_with_trait("3".to_string(), 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Copy` is not implemented for `String`
|
note: required by a bound in `Point::<T>::set_x_and_echo_with_trait`
--> src\main.rs:141:22
|
139 | fn set_x_and_echo_with_trait<U>(&mut self, x: T, v: U) -> U
| ------------------------- required by a bound in this
140 | where U: Clone,
141 | T: Clone + Copy
| ^^^^ required by this bound in `Point::<T>::set_x_and_echo_with_trait`
如果使用实现了Copy的i32类型则正常运行
fn main(){
let mut p = Point{x: 1, y: 2};
p.set_x_and_echo_with_trait(3, 1);
println!("{}", p.x)
}
泛型的约束也可以加到impl<T: Copy+Clone>,来表示下面的所有方法都只适用于实现了Copy和Clone的类型T。等价于每个函数里约束T。
生命周期
声明周期一般用'a这种形式表示,他和泛型一样,都是表示一个声明,表示现在有个一声明周期假如叫a。
生命周期标注只是对于编译器有用的,实际运行没有实质作用。生命周期标注只对引用类型有用,因为只有引用类型的生命周期可以被标注,普通变量类型的生命周期就是作用域结束。
经常会用于返回引用的函数,因为函数返回引用意味着返回的值是没有数据的所有权的,那可能就会在后续使用时数据被清理,所以通过声明生命周期的方式可以保持和某个入参一样的生命周期,如下,并且提供以下语法糖:
- 1 当入参只有一个引用类型,且返回值要和该引用声明周期相同的时候就不需要加
'a声明。 - 2 如果有&self作为参数,那返回值如果是引用,生命周期与&self保持一致。
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
'a并不改变程序运行逻辑,只是通知编译器两者生命周期相同,让编译器能允许通过该前提下合法的写法。像上面的函数就是最经典的场景,我们还可以把返回值的x改为"1"这样的字面量,因为字面量生命周期是'static肯定是包含'a的,那也可以通过编译。而如果入参xy生命周期不同,那a指最小的。但是如果返回值改为
let str = String::from("xx");
return &str[..]
那么就会报错returns a value referencing data owned by the current function。
结构体与生命周期
结构体的建议写法是不要写引用类型的成员变量,因为引用类型意味着该变量的所有权不归结构体所有。那么很有可能在使用结构体的时候,变量已经被清理了。
但是有了生命周期标注,就可以使用引用了。结构体的生命周期标注,向编译器声明了这样一件事:使用该标注的字段存活的一定比自己久。如下,name的存活的一定比结构体久。a代表的是Person的生命周期。当然了,如果写出了不符合这个规定的代码,编译也会不通过。
struct Person<'a> {
name: &'a str,
}
// 与泛型类似,如果要实现方法写法如下
impl<'a> Person<'a> {//Person<'a>才是结构体全名,缺少<>是不对的
// 注意返回值类型,应该是&'a str,但是因为语法糖2,与self保持一致,所以就可以省略'a
fn get_name(&self) -> &str {
self.name
}
}
// 生命周期没有trait约束,但也有周期约束,b是a的子集,通俗讲就是a比b活得久
// 如果没有b约束的话(去掉:'b),下面代码就会报错,因为a与b无任何关系,要求返回b,但是返回a自然报错,但是加了约束,说明a活的更久啊,所以就没错了。
// 期望一个3年工作经验的,给了个5年的,莫得问题
impl<'a: 'b> Person<'a> {
fn ff(&self, another_name: &'b str) -> &'b str {
self.name
}
}
因为生命周期标注只是一个辅助编译的声明,不产生实质作用。所以如果代码确认没错,可以用'a: 'static来表示'a是永存的,当然只是告诉编译器这个信息,实际运行还是会被回收的,因为编译器知道是永存的,那么任何&self方法的返回引用,都可以是任意周期的引用了。一路绿灯,但是这样比较危险。
生命周期一直在
在函数的入参和返回值上,但凡是引用类型,他都是有生命周期的,编译器看到的是:
fn f(x: &str, y: &str)->&str
===>
fn f(x: &'a str, y: &'b str)->&'c str
// 当然了这个函数编译不过,因为c和ab无关
如果加了标注约束,那编译器知道c是和ab都一致的,所以就可以编译通过。
fn f<'a>(x: &'a str, y: &'a str)->&'a str
同时使用T和'a
泛型和生命周期同时出现的时候,生命周期需要写在前面。
struct Personss<'a, 'b, T> {
name: &'a str,
age: &'b u32,
v: 'a T,
}
NLL (Non-Lexical Lifetime)是指新的rust(1.31)编译器中,引用的生命周期在最后一次使用之后结束,而不需要到作用域结束。
fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2);
// 新编译器中,r1,r2作用域在这里结束
let r3 = &mut s;
println!("{}", r3);
}
Reborrow 再借用,如下,rr是对r解引用后的引用。rr与r一样都是&i32类型,但是在借用不算借用,也就是说不会影响存在的借用数量。例如rust规定可变引用只能有1个,且不能同时再有不可变引用。但是在借用不算引用。
let r = & 1;
let rr = &*r;
// r是可变引用,rr是不可变引用,但是rr是在借用不算借用,所以不算破坏规则。
let r = &mut 1;
let rr = &*r;
在借用好像可以打破原来的规范,使得一切变得不安全。好在在借用有使用限制,就是在借用从声明到最后一次使用的期间,不能在使用借用r。
NLL,使得先使用&mut,用完再用&,变得合法,即我们可以(--){--}(--)(前括号是声明,后括号是结束使用)的来使用引用。
Reborrow,使得先声明了&mut,然后又声明&,并使用&完之后,再去使用&mut变得合法。{()()},因为在借用严格规定不能出现交叉,即在借用生命周期中不能出现原借用,所以也能保证安全性。
闭包
闭包是一种匿名函数,它可以赋值给变量也可以作为参数传递给其它函数,不同于函数的是,它允许捕获调用者作用域中的值,例如:
fn main() {
let x = 1;
let sum = |y| x + y;
assert_eq!(3, sum(2));
}
闭包的写法是|入参: 类型| -> 返回值类型 {内容}不过闭包有自动的类型推导,所以入参和返回值的类型大多数时候可以不写。闭包是一个实际的变量对象,例如上面的sum。那闭包的类型呢?实际上每一个闭包都有属于自己的类型,即使一模一样的签名。所以闭包没法用类型来约束,只能用trait。
fn run_closure(f: impl Fn(u32) -> u32, x: u32) {
f(x);
}
这里就用到了Fn这个trait,实际上闭包相关的trait有三种:FnOnce、FnMut和Fn。Fn实现了FnMut,FnMut实现了FnOnce。
FnOnce只能调用一次,调用第一次后,闭包的生命周期结束。下面调用两次f报错。
fn run_closure(f: impl FnOnce() -> u32) {
f();
f();
}
FnMut就可以调用多次了,并且FnMut是可以修改上下文中捕获的变量的。例如下面闭包就改变了上下文中x的值,所以change_x不是只实现了FnOnce的,而是实现了FnMut和FnOnce。所以他可以被FnOnce或者FnMut的trait来约束,
// 这两种函数写法都是正确的,但是Fn是不行的,因为change_x没有实现Fn。
fn run_closure(f: impl FnOnce()) {
f();
}
fn run_closure(mut f: impl FnMut()) {
f();
}
fn main() {
let x = 1;
let change_x = || x = x + 1;
run_closure(change_x);
println!("{}", x)
}
所有闭包都实现了FnOnce,改上下文变量的自动实现FnMut + FnOnce,不改的自动实现Fn + FnMut + FnOnce。有人对于Fn包含FnMut表示不解,不应该是反过来吗,怎么只读的还包含读写呢?这是因为这样的包含关系才能使只读的Fn范畴更严格,不会把可写的FnMut作为参数,传入了Fn约束里了。反之只读的Fn可以作为FnMut类型的参数传入。
move关键字,写在闭包的|参数|前面,可以实现把当前上下文的变量以转移所有权到闭包中。经常用于线程/异步的场景,因为无法知道闭包执行的时候变量是否还能正常的存活到这个时候,干脆直接把所有权扔给闭包里面了。
fn main() {
let mut x = String::from("1");
let mut change_x = || x = String::from("222"); // 注意FnMut一般需要mut声明变量。
change_x();
println!("{}", x);// 打印222
}
如果添加了move关键字:let mut change_x = move || x = String::from("222");则上述代码报错,因为x所有权已经进到闭包里面了,当前作用域已经无法再使用x了。
180 | println!("{}", x)
| ^ value borrowed here after move
FnOnce FnMut Fn小结
如何快速判断一个闭包是哪种trait,
- 1 如果没用捕获变量那就是fn(fn > Fn)
- 2 捕获变量,按照优先级 将闭包中的变量当做 【copy->引用->可变引用->所有权本体】 来适配闭包,使得功能正常工作。如果全都是引用就万事大吉,那就是Fn,例如下面的c1 c2和c22。如果至少需要一个可变引用才能畅通,那就是FnMut,例如c3 c4和c6。而如果是必须本尊所有权持有者,亲自出马才能解决问题,那么就是FnOnce,例如c5.
经常遇到例如Vec的iterator操作
|| for elem in v.iter() {println!("{:?}",elem)};iter的入参是&self,所以按照上面规则引用即可,是Fn|| for elem in v.into_iter() {println!("{:?}",elem)};into_iter如参数self,所以需要本尊来才行,是FnOnce,如果传入Fn约束的函数中作为参数会报错this closure implements FnOnce, not Fn.closure is FnOnce because it moves the variable v out of its environment
move关键字是可以帮助Fn和FnMut也实现拿到变量所有权,但是不改变闭包实现的trait。
fn main() {
let k = 10;
fn f1(i: i32) -> i32 { i }
fn_test(f1);
// 闭包没有捕捉上下文变量,退化成函数fn
let f2 = |i: i32|->i32 { i };
fn_test(f2);
// 闭包捕捉上下文中变量,无法退化成fn
let f3 = |i: i32|->i32 { i + k };
clo_test(f3);
// Fn 拿引用即可实现函数的功能,那就只拿引用,trait就是Fn
let s = "1".to_string();
let f4 = move ||->String { println!("s: {}", s); return "2".to_string(); };
Fn_test(f4);
println!("s: {}", s);
FnOnce_test(f4);
// FnMut 拿可变引用即可实现函数的功能,那就只拿可变引用,trait就是FnMut
let mut s = "1".to_string();
let f5 = ||->String { s.push_str("1"); println!("s: {}", s); return "2".to_string(); };
FnMut_test(f5);
// FnOnce_test(f5);
// FnOnce 拿所有权才能实现函数功能,trait就是FnOnce
let s = "1".to_string();
let f6 = ||->String { println!("s: {}", s); return s; };
FnOnce_test(f6);
// fn Fn FnMut FnOnce move
}
// FnOnce FnMut Fn
fn Fn_test<F: Fn()->String>(f: F) {
println!("Fn test {}", f());
}
fn FnMut_test<F: FnMut()->String>(mut f: F) {
println!("FnMut test {}", f());
}
fn FnOnce_test<F: FnOnce()->String>(f: F) {
println!("FnMut test {}", f());
f();
}
fn fn_test(f: fn(i32)->i32) {
println!("{}", f(11));
}
fn clo_test<F: FnOnce(i32)->i32>(f: F) {
println!("{}", f(11));
}