池化技术
我们在很多工具很多场景中经常看到池化技术,例如连接池、对象池、线程池,这些都是利用了池化技术,而池化技术本身其实是一种资源复用的出发点。
当我们创建某些资源有较高的代价的时候,就可以通过先创建一批这种资源放到池子里,当需要销毁资源的时候,不是真正的销毁而是返回到池子中。等下一次再需要该资源的时候,直接将池子中的该资源返回去。
这样一来,避免了多次创建和销毁资源,而典型的有较高创建代价的资源有
- tcp连接,三次握手代价较高,对应的池化技术就是连接池,当然针对更细的场景有数据库连接池,http连接池等等。
- OS线程,线程的create/destroy需要进入内核态,代价也很高。对应池化技术就是线程池,线程池在java中又有经典线程池模型和ForkedJoin模型。
- 对象,在特定场景下,对象的创建和销毁也成为了一种负担,一般上层场景较少,底层框架会有大量且频繁使用对象的场景,这时候为了减少对象创建和销毁就会使用对象池,本文不对该对象池做讨论,主要对连接池和线程池做展开。
1 数据库连接池
主要以最火的Hikari的源码为例,展开分析。上面我们知道了连接池的目的就是复用tcp连接,说白了就是复用Connection对象,通俗讲就是我们可以事先创建很多个jdbc Connection放到一个池子中,等使用的时候从中拿,用完了再还回来。
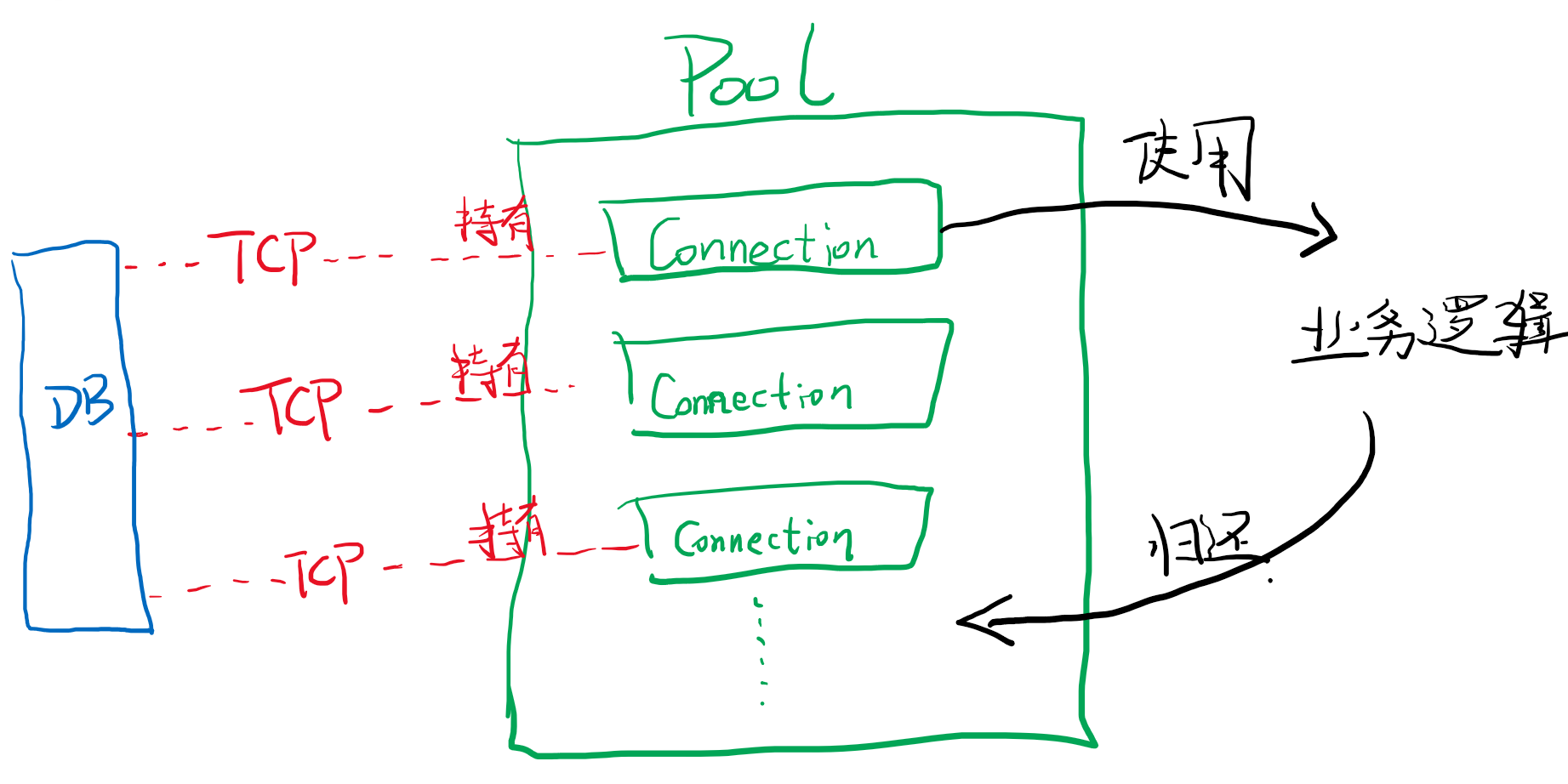
这个过程如上图,好像Pool的实现并不麻烦,只需要一个队列和维护队列push/poll的方法就可以了。然而实际上,数据库连接池还需要一些繁琐的“运维”工作,例如
- 1 维持连接的鲜活的keepLive,可能是每过多少秒看看tcp是否正常。
- 2 如果一个连接失效了,可能是被db断开也可能是超过一定寿命了,需要被清理的操作。
- 3 清理完,得进行补充以达到设定的poolSize。
- 4 等等
“运维”工作是必须做的本分,此外还要考虑并发和性能问题,例如多线程同时想获取连接,怎么避免把同一个conn给了多个线程等。
我们来看一下hikari的设计,下面是Hikari使用方法。
<!-- https://mvnrepository.com/artifact/com.zaxxer/HikariCP -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.h2database/h2 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>2.1.214</version>
</dependency>
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
public class DbConnPool {
private static final DataSource dataSource;
static {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:h2:mem:test;MODE=MySQL;");
config.setUsername("sa");
config.setPassword("");
dataSource = new HikariDataSource(config);
}
public static void main(String[] args) {
try (Connection conn = dataSource.getConnection()) {
Statement stat = conn.createStatement();
stat.execute("create table test (id INTEGER PRIMARY KEY, name VARCHAR(255))");
stat.execute("insert into test (id, name) values (1, 'a')");
stat.execute("insert into test (id, name) values (2, 'b')");
ResultSet resultSet = stat.executeQuery("select * from test");
while (resultSet.next()) {
System.out.println("name: " + resultSet.getString("name"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
这是hikari主要的几个类的uml图,简单说一下几个重要的点
- 1 用户使用的是
HikariDatasource这个类,调用getConnection方法去使用一个连接,这个连接是HikariProxyConnection类型。 - 2
HikariDatasource中的功能主要封在HikariPool这个类中,主要是一些线程池异步的进行池子的“维护”,例如houseKeepTask中有每30s检查连接数并填充的任务。 - 3
ConncurrentBag是HikariPool中的主要成员,是存放连接的池子本身,主要有list来存放,其中ThreadLocal是加速用的。 - 4 池子中存的是
PoolEntry对象,该对象持有要返回的Connection,除此之外还有记录状态标志位,调度线程来keepAlive和endOfLife的清理,当然还有保证不被多个线程同时获取的cas操作。 - 5
HikariProxyConnection是用户最终拿到的Connection,他的close方法是归还到池子中。

2 http连接池
与上面数据库连接池一样都是tcp连接池,我们已经看到连接池其实主要是对池子中现存的连接的一些维护工作,和并发场景下的性能等。http连接池的思路是类似的,所以没有太多的额外的知识点。不过这里想顺便介绍下NIO加持下的Http连接方式,上面介绍的Hikari的连接池是同步的连接,这里我们针对底层是NIO的jdk11之后自带的HttpClient源码进行分析。下面是基础的使用姿势。
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.GET() // 默认就是get可以不写
.uri(URI.create(BASE_URL)) // url
.headers("k1", "v1", "k2", "v2") // 添加header,没有可以不写这行
.timeout(Duration.of(30, ChronoUnit.SECONDS)) // 配置超时,超时后会以HTTPTimeoutException抛出异常
.build();
client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
.whenComplete((response, err) -> {
if (err == null && response.statusCode() == 200) {
String res = response.body();
// do something
System.out.println(Thread.currentThread() + -":" + res); // execution thread is ForkJoinPool.commonPool
}
});
首先HttpClient.newHttpClient创建的是jdk.internal.net.http.HttpClientImpl这个默认的实现,我们简单的来梳理下。
HttpClientImpl中semgr成员是SelectorManager类型继承自Thread,是一个独立运行的单线程,该线程是事件循环,主要处理注册上来的事件,同时作为NIO的主循环也检测IO selectedKey进行事件的回调,这个循环是整个HttpClient的核心代码所在。以建立连接事件为例,在建立连接的函数中,将连接建立的事件进行注册,实际上是SocketChannel注册到NIO的Selector中,此时是非阻塞的,把CompleteableFuture传到事件中,等待连接完成,之后触发这个cf作为回调。而对其他事件,例如请求发送响应接收等等这里不展开讲了,原理类似但是代码更复杂,夹杂很多回调非常难懂。
1

2

3

4

下面我们看一下HttpClient中是如何使用连接池的,以Http1版本的客户端为例,发起请求的一个主要的class是Http1Exchange,成员变量connection就是http连接,在构造方法中,要么以参数直接传进来连接,要么就通过HttpConnection的静态方法getConnection来创建连接。
// Http1Exchange构造方法
Http1Exchange(Exchange<T> exchange, HttpConnection connection) throws IOException
{
super(exchange);
this.request = exchange.request();
this.client = exchange.client();
this.executor = exchange.executor();
this.operations = new LinkedList<>();
operations.add(headersSentCF);
operations.add(bodySentCF);
if (connection != null) {
this.connection = connection;
} else {
InetSocketAddress addr = request.getAddress();
this.connection = HttpConnection.getConnection(addr, client, request, HTTP_1_1);
}
this.requestAction = new Http1Request(request, this);
this.asyncReceiver = new Http1AsyncReceiver(executor, this);
}
静态方法getConnection获取连接的时候,先从入参client中的pool中获取,如果获取失败,则再去创建如果pool中已经有了就会用pool中的。
public static HttpConnection getConnection(InetSocketAddress addr,
HttpClientImpl client,
HttpRequestImpl request,
Version version) {
InetSocketAddress proxy = Utils.resolveAddress(request.proxy());
HttpConnection c = null;
boolean secure = request.secure();
ConnectionPool pool = client.connectionPool();
if (!secure) {
c = pool.getConnection(false, addr, proxy);
if (c != null && c.isOpen() /* may have been eof/closed when in the pool */) {
final HttpConnection conn = c;
return c;
} else {
return getPlainConnection(addr, proxy, request, client);
}
} else { // secure
if (version != HTTP_2) { // only HTTP/1.1 connections are in the pool
c = pool.getConnection(true, addr, proxy);
}
if (c != null && c.isOpen()) {
final HttpConnection conn = c;
return c;
} else {
String[] alpn = null;
if (version == HTTP_2 && hasRequiredHTTP2TLSVersion(client)) {
alpn = new String[] { "h2", "http/1.1" };
}
return getSSLConnection(addr, proxy, alpn, request, client);
}
}
}
ConnectionPool代码非常简单直接,使用HashMap<CacheKey,LinkedList<HttpConnection>>对同一个proxy+desip作为key,存储多个连接列表,可以看到都没有使用并发的类,而是直接用synchronize来保障同步问题。
池子的填充,则是靠上一次的连接用完了,就会在完成的时候将连接放到池子中。
private void onFinished() {
asyncReceiver.clear();
if (return2Cache) {
connection.closeOrReturnToCache(eof == null ? headers : null);
}
}
需要注意的是jdk的连接池默认没有开启,空池子,可以通过指定属性-Djdk.httpclient.connectionPoolSize=10来指定池子大小。
final class ConnectionPool {
static final long KEEP_ALIVE = Utils.getIntegerNetProperty(
"jdk.httpclient.keepalive.timeout", 1200); // seconds
static final long MAX_POOL_SIZE = Utils.getIntegerNetProperty(
"jdk.httpclient.connectionPoolSize", 0); // unbounded
...
}
3 经典线程池ThreadPoolExecutor
- 当线程池创建后,池子内部一开始没有线程,当有
Runnable任务提交上来的时候才开始创建线程,并进行执行。 - 任务执行完成后,线程对象被归还到池子中,后续的任务可以复用该线程去执行。
ThreadPoolExecutor是jdk中经典的线程池,有7个构造参数,并且都非常重要。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize代表核心线程数量,maximumPoolSize代表最大线程数量,前者小于等于后者,workQueue是个同步队列,用于任务排队。这是三个最重要的任务存放或执行的地方。优先级为 先填满corePoolSize个线程,如果还有任务添加,再填充workQueue队列,队列满了,仍有任务添加,则继续创建线程直到最大的maximumPoolSize个正在运行的线程,如果还有任务添加,则拒绝执行,拒绝的方式是传入的handler参数决定。
例如core=10,max=15,queue=10,则前10个任务会分别创建线程执行,第11-20个任务会被放到queue中排队,第21到25会继续创建线程,使总线程达到15个。第26个任务提交后会触发拒绝策略,默认的拒绝策略是抛出异常。
keepAliveTime和unit表示,max超出core的线程闲置后存活的时间,上面例子中21-25执行完成后,线程如果闲置超过设定的存活时间,就会被清理,换句话说coreSize的线程数是一直不需要销毁的,无论闲置多久,只有max-core超出的这部分才会被销毁。threadFactory则是创建线程的工厂,一般用来指定线程名前缀等,用处最小的一个参数。
demo:
ThreadPoolExecutor pool = new ThreadPoolExecutor(10, 15, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
static class Task implements Runnable {
int id;
public Task(int id) {
this.id = id;
}
@Override
public void run() {
System.out.println(new Date() + "task " + id + "running");
try {
Thread.sleep(3 * 1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
当迅速提交25个task,前15个在
for (int i = 1; i <= 25; i++) {
pool.execute(new Task(i));
}
/*
Tue Jan 03 23:31:57 CST 2023task 9running
Tue Jan 03 23:31:57 CST 2023task 2running
Tue Jan 03 23:31:57 CST 2023task 22running
Tue Jan 03 23:31:57 CST 2023task 21running
Tue Jan 03 23:31:57 CST 2023task 5running
Tue Jan 03 23:31:57 CST 2023task 10running
Tue Jan 03 23:31:57 CST 2023task 3running
Tue Jan 03 23:31:57 CST 2023task 8running
Tue Jan 03 23:31:57 CST 2023task 7running
Tue Jan 03 23:31:57 CST 2023task 24running
Tue Jan 03 23:31:57 CST 2023task 23running
Tue Jan 03 23:31:57 CST 2023task 4running
Tue Jan 03 23:31:57 CST 2023task 25running
Tue Jan 03 23:31:57 CST 2023task 1running
Tue Jan 03 23:31:57 CST 2023task 6running
Tue Jan 03 23:32:00 CST 2023task 11running
Tue Jan 03 23:32:00 CST 2023task 12running
Tue Jan 03 23:32:00 CST 2023task 13running
Tue Jan 03 23:32:00 CST 2023task 14running
Tue Jan 03 23:32:00 CST 2023task 18running
Tue Jan 03 23:32:00 CST 2023task 17running
Tue Jan 03 23:32:00 CST 2023task 16running
Tue Jan 03 23:32:00 CST 2023task 15running
Tue Jan 03 23:32:00 CST 2023task 19running
Tue Jan 03 23:32:00 CST 2023task 20running
*/
这个例子能很好的反映,core->queue->max这样的递进关系,其中max和core两个size会使人有点困惑,为什么不是一个size和一个队列。max多出core的部分在queue之后,使得更早提交的10-20号任务反而在21-25任务之后才执行。
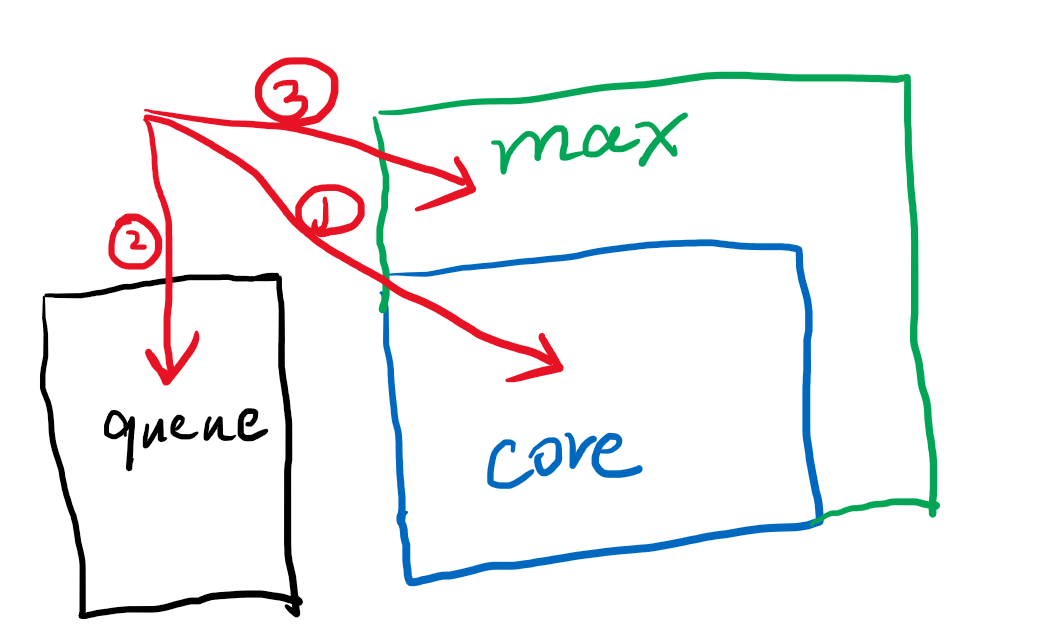
其实max的出发点是,如果任务提交情况超出了设计之初的设想下,即queue也满了的情况下,提供一种buffer机制,例如少量超出的场景,通过max略大于core可以包容这部分溢出,来使系统稳定运行。如果只需要一个池子和一个队列,就可以简单的把core和max的值设置为一样即可。
jdk提供的几个重要的线程池模型
CachedThreadPool没有上限的池子,一直会创建线程,core为0,queue也是0,三级缓存只使用了第三级,并且是无限多个,当闲置1分钟后清理。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
FixedThreadPool固定大小的池子,这个最常用,core=max没有第三级缓存,queue是无现长的队列,即也可以接受无限多的任务,执行不过来就无限排队。SingleThreadExecutor是单线程的版本。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
newScheduledThreadPool是定时调度的线程池,这个比较特殊,这里不展开。
以上两种线程池,cached不建议使用,因为每个任务来都会无脑new Thread,不受控制的线程创建可能导致线程数超过OS限制,引发崩溃。fixed在生产环境下也不太建议使用,因为fixed在任务疯狂提交的场景下,会一直塞到队列中,且linkedBlockingQueue其实是有size上限的就是Int.max,如果真的塞满这么多任务,这两个池子也会触发拒绝策略。
一种比较好的线程池参数如下,core=max数,这里以100为例,配合空队列,这样超过100的任务,会被拒绝,拒绝策略使用CallerRun,也就是提交第101个任务的线程自己去执行第101个任务,这样形成负反馈,让生产者也有事情去做,阻塞了生产者的盲目生产。而至于线程的数量100这个值,如何去定夺还要根据场景,如果是纯计算的任务那么线程数与cpu核数基本一致即可,如果是IO密集的则可以提高线程数,但是尽量不要超过1000。
new ThreadPoolExecutor(100, 100, 0, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
4 特定场景使用的ForkJoinPool
举个例子,如果使用ThreadPoolExecutor,core=max=3,然后queue无限大。起初1,2,3号任务提交,三个线程分别运行,而1运行中发现需要依赖4,5任务的结果,所以就提交了4,5任务。同理2也提交了6,7任务。3提交了8,9任务。
因为123都有依赖的资源没有完成所以在阻塞,而他们的依赖任务都排到了队列中,无法执行,因为123占满了线程池,于是形成死锁。
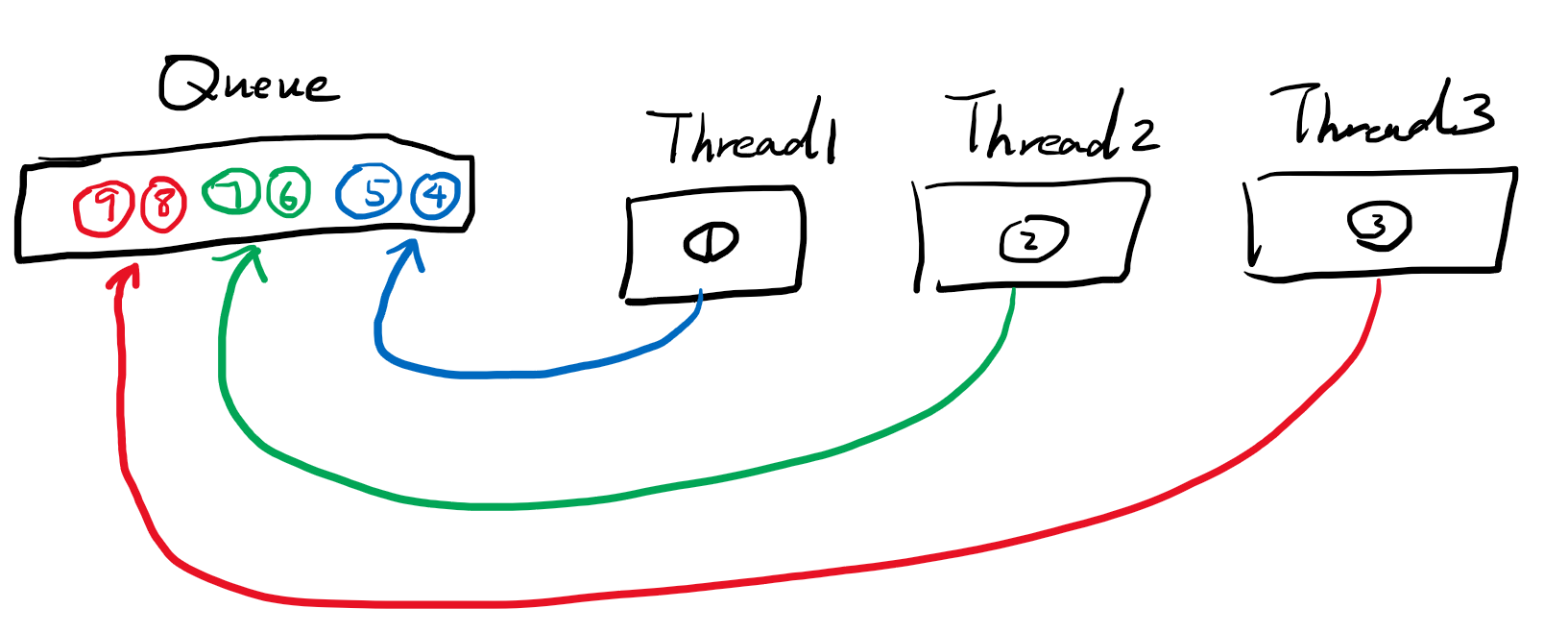
ThreadPoolExecutor pool = new ThreadPoolExecutor(3, 3, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
pool.execute(()->{
System.out.println("t1");
CountDownLatch finished = new CountDownLatch(2);
pool.execute(()->{
System.out.println("t4");
finished.countDown();
});
pool.execute(()->{
System.out.println("t5");
finished.countDown();
});
System.out.println("t1 finish");
try {
finished.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
pool.execute(()->{
System.out.println("t2");
CountDownLatch finished = new CountDownLatch(2);
pool.execute(()->{
System.out.println("t6");
finished.countDown();
});
pool.execute(()->{
System.out.println("t7");
finished.countDown();
});
try {
finished.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t2 finish");
});
pool.execute(()->{
System.out.println("t3");
CountDownLatch finished = new CountDownLatch(2);
pool.execute(()->{
System.out.println("t8");
finished.countDown();
});
pool.execute(()->{
System.out.println("t9");
finished.countDown();
});
try {
finished.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t3 finish");
});
/**
t1
t2
t3
// 然后卡死了4-9无法执行
*/
去掉Queue+引入CallerRun策略可以解决该问题,如果没有queue,那么456789任务提交的时候,都会触发拒绝策略,并且由当前运行提交的线程来阻塞执行这个任务。也就是说4在提交的时候,被拒绝,于是由提交4的thread1来执行。callerRun最大的特点就是一直会有任务在执行,即使没有线程资源了,那就提交者线程来执行,所以一定能保证不会出现死锁。
线程池改为如下,则可以t1-t9都执行完成。
ThreadPoolExecutor pool = new ThreadPoolExecutor(3, 3, 0, TimeUnit.SECONDS, new SynchronousQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
仍有不足!如果上述场景1236789任务的执行时间都是10ms,而45任务执行时间是1hour,那么当t4任务提交的时候发现需要由thread1来执行,此时thread1被阻塞1小时候,thread1提交t5任务,此时thread2/3也都闲置了,任意一个thread执行完t5,总耗时长达2小时。其实问题出在t4执行的时候,t5是没有办法提交的。
ForkJoinPool的设计是n个线程组成的池子 + 队列,和传统的有点像,只不过这里的队列不再是一个队列,而是每个线程会有一个专属队列。当线程中正在执行的任务提交新的任务的时候,会直接提交到自己的队列。
123任务运行时,提交新的任务会到自己线程专享的队列,并且注意队列插入的方向。当45插入到队列后,运行t4.join t5.join等待t4 t5完成,这里t4.join会先运行t5,因为插入和运行是先入后出的栈模型,所以t5先去执行,t5直接由thread1阻塞执行。(join方法就是把这个任务和排在他前面的任务都用所在的线程阻塞执行完成)
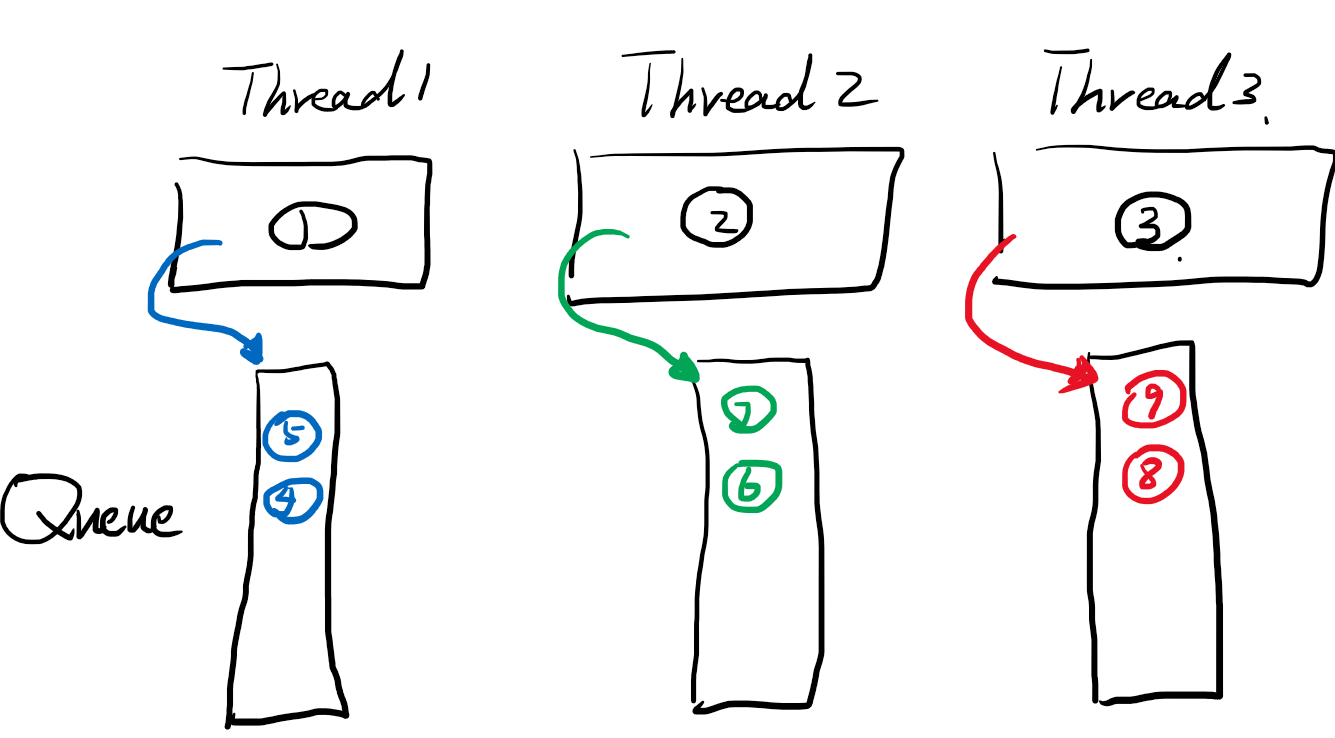
同理t7,t9也在同时被阻塞执行.
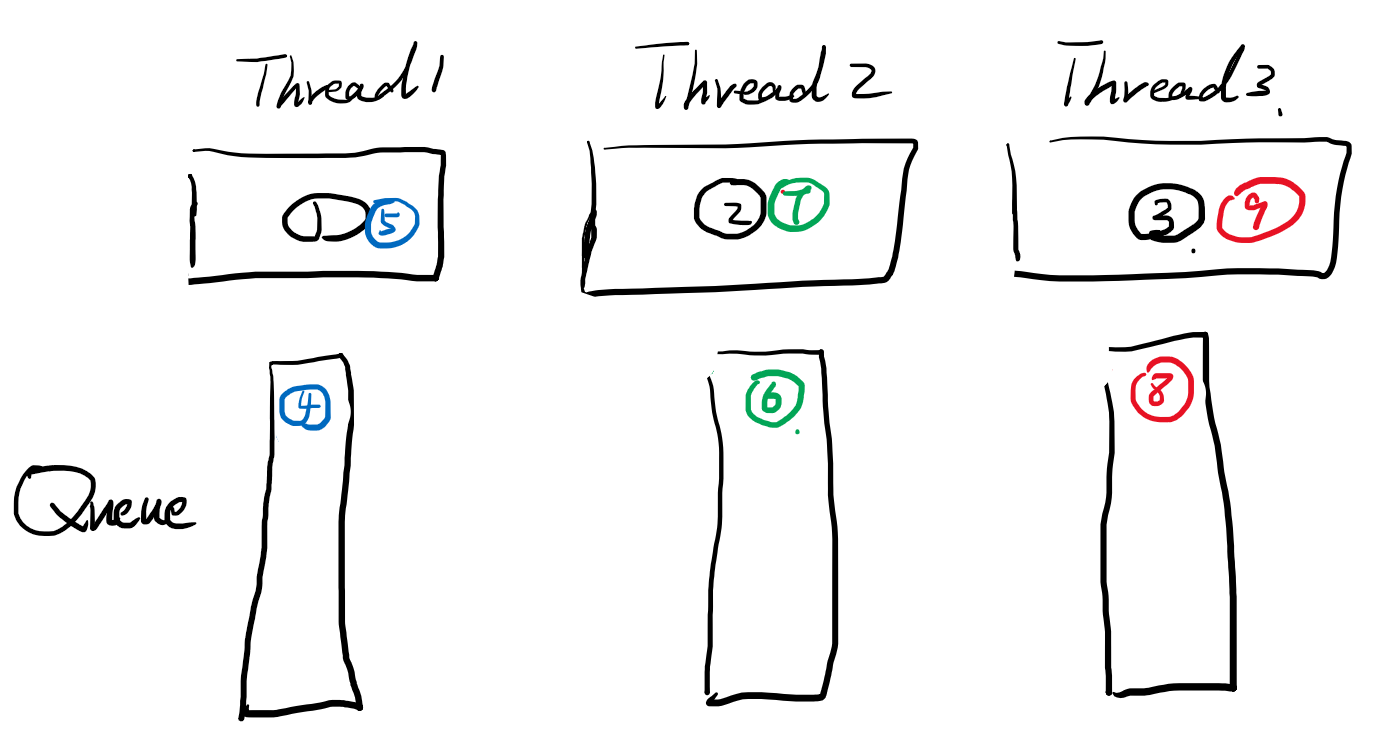
考虑到t4、5是1hour的任务,所以thread2/3队列中的任务很快就执行完成了。此时,就要介绍forkjoinPool的偷取策略,就是当thread2、3的队列空了,没任务的时候,就会看看其他兄弟thread的队列,有没有需要帮忙执行的任务,就给他偷过来。帮忙执行。
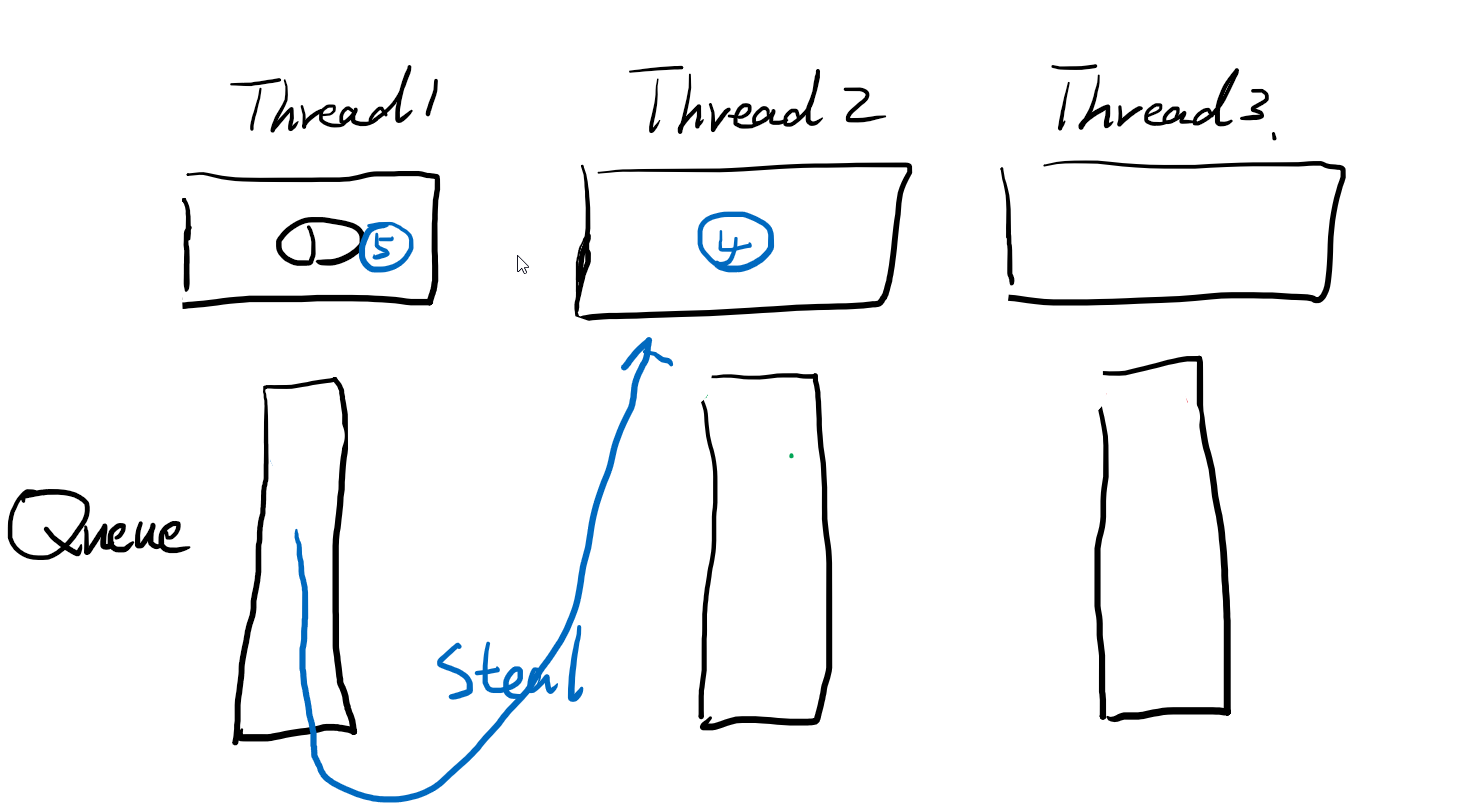
注意偷取的方向,是先入先出的方向。和join时执行的方向相反。因为join是递归的dfs行为,所以上方的节点深度比较深,而下方的比较浅,子树节点一般就更多,偷取这样的节点,更好的分担thread1的负担。两者方向不同好理解,但为什么自己执行是先入后出,别人偷取是先入先出呢,为什么不是反过来呢。这是因为插入队列的时候,一边插入,别的线程就可以一边偷取了,此时肯定是从先插入的偷取。