scala中的immutable
scala中的容器数据结构非常多且杂,从大类上有有序结构Seq、集合Set、kv结构Map,其中Set基本是Map实现的。而从是否可修改又分为immutable不可修改和mutable可修改两种。并且在Scala中默认的实现都是不可修改的。
immutable.Seq
List---Seq的默认实现,LinearSeq的默认实现
Seq是序列的接口,默认可以这样来创建一个Seq。这里Seq是immutable.Seq,默认的实现是单链表List。
Seq分为能快速索引某一下标的IndexedSeq和线性排列实现的LinearSeq,List是LinearSeq默认实现,也是Seq默认实现。利用List单链表操作head是O(1)复杂度,但是如果要求s(n),那复杂度就是O(n)了。
Seq提供了非常常用的+:在头部添加元素,+:则是尾部,++:在头部添加另一个seq,:++则是尾部,updated更新某一元素.注意immutable.Seq对于写场景都是保持原来变量数据不变,复制一份然后进行写操作,返回新的数据而不改变原来的数据。
var s = Seq(1,2,3)
s = s:+4
s = 0+:s
因而对于单链表List来说,+:头部插入是比较容易的,只需要在原来List头部追加元素,并返回追加后的头部节点,如下图
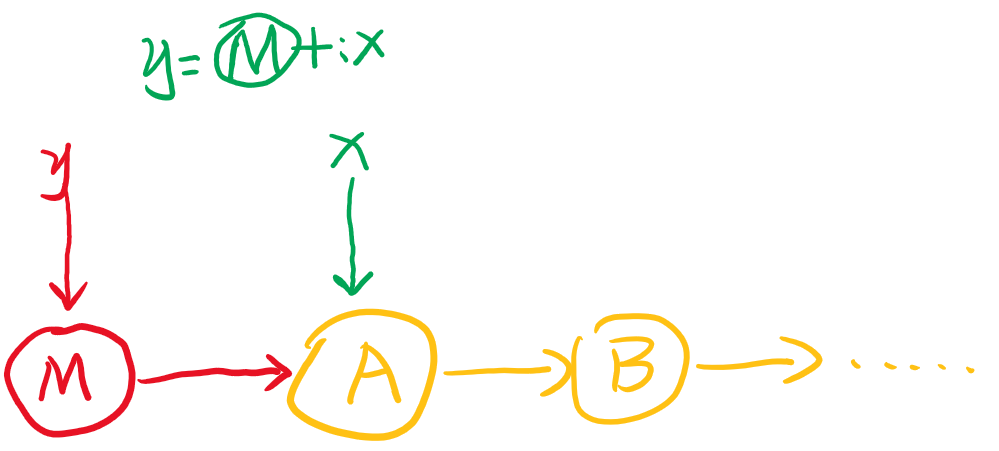
但是对于:+尾部追加,updated(i, m)的操作都相对比较麻烦,需要每个元素都拷贝到一个新的List中,然后对相应元素进行写操作,如下图是:+的过程。
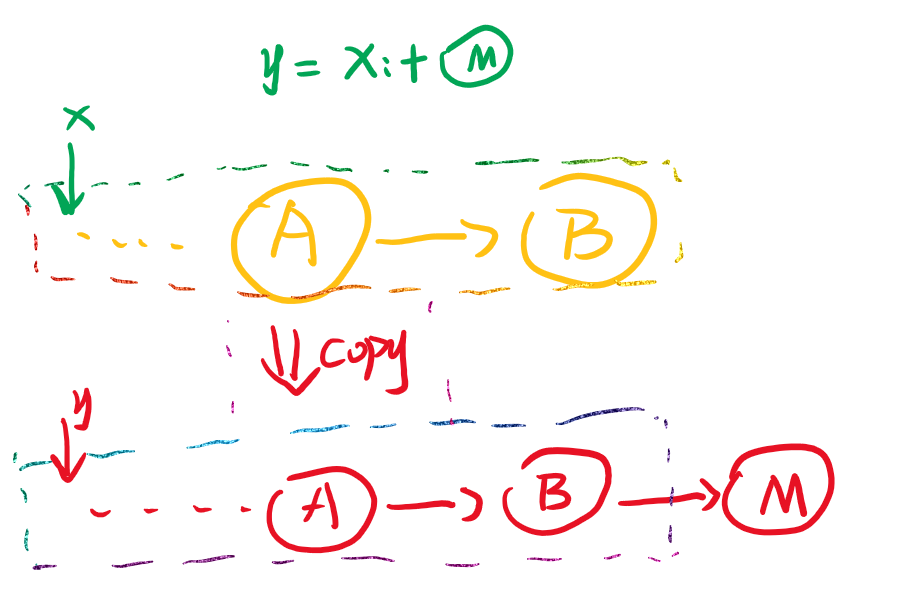
对于长度较小的数据或没有随机访问下标只是顺序访问下标的场景可以使用List,否则不要使用List,可以考虑下面的Vector。
Vector---IndexedSeq的默认实现
Vector相比于默认的Seq的List实现,结构上更复杂,但是写性能上比List好非常多。
Vector有7种子类分别是Vector0到Vector6,我们来看一下往一个空的Vector不断插入元素的过程。
一开始空的Vector是Vector0,这是个纯空的壳子,当我们插入第一个元素的时候就会变成Vector1,Vector1是一个数组Array,数组长度就是元素长度,也就是1。当我们继续用:+或者+:进行插入的时候,会复制数组,产生一个新的数组。
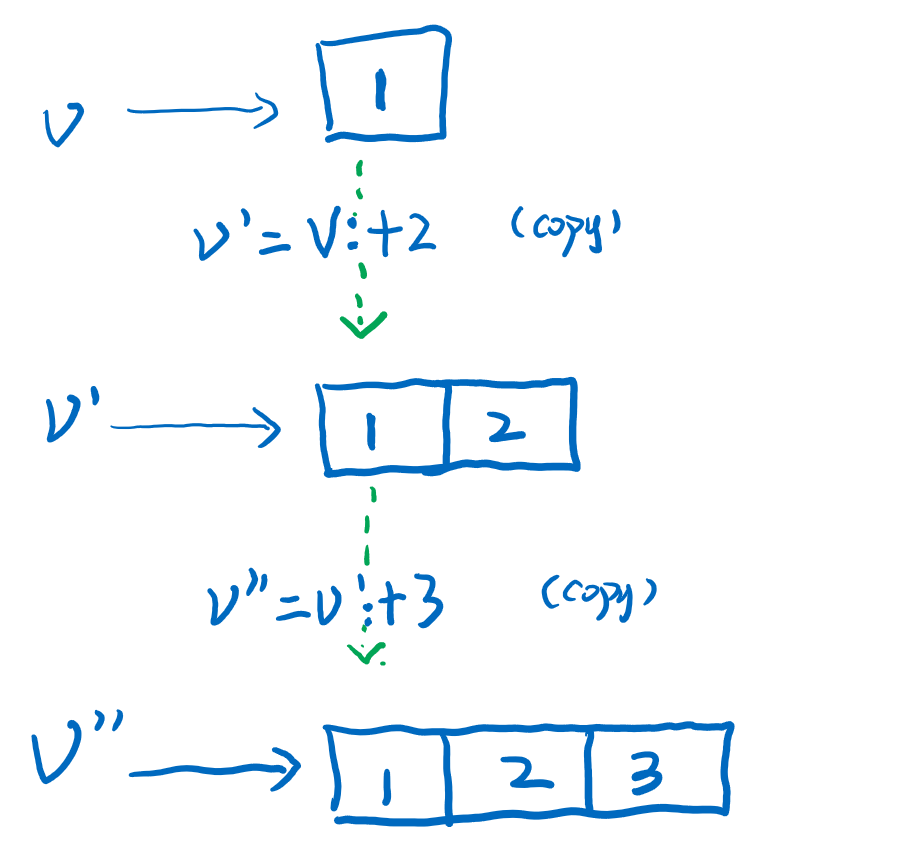
这似乎没什么特殊的也是通过copy的方式实现对immutable.Seq的写操作,并且也是需要有n次copy。Vector最核心的思想在于分块,32个元素是一个块,当Vector1中元素数量超过32的时候,会产生变化,成为Vector2,其数据分布在三个部分,两个个一维数组prefix1,suffix1和一个二维数组data。我们来从图中看当数组变成33长度的时候,Vector1是如何变成Vector2,如下图
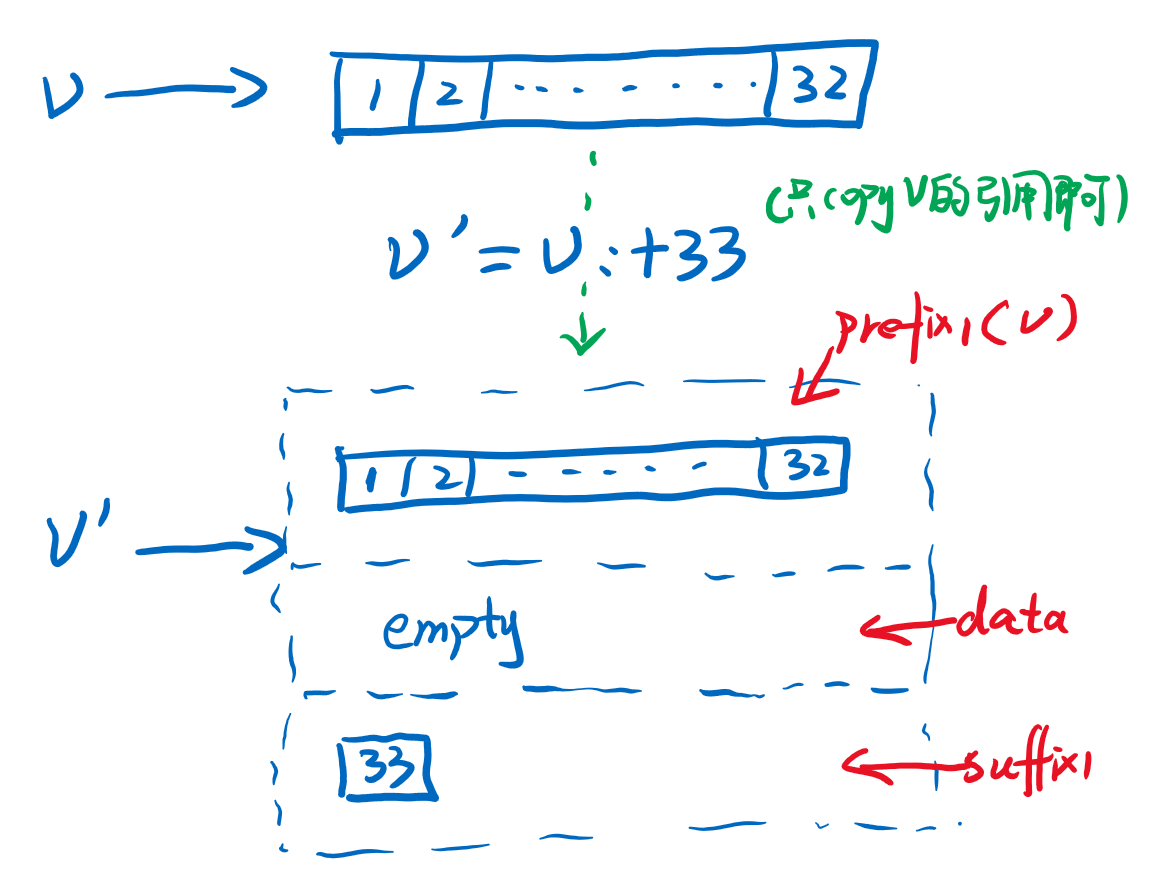
为了方便描述Arr1是一维数组结构Array[T]的别名,以此类推。我们再来回顾一下,Vector1晋升为Vector2的过程。Vector1呢本身就是一个Arr1和记录长度的Int值len组成的,而Vector2是两个Arr1和一个Arr2组成的,当然还有总长度和每一部分的长度的记录。当33插入的时候,原来的Arr1直接作为prefix1部分,而suffix1中申请一个长度为1的Arr1来存储33这个元素。
注意这个过程中有一个好处,那就是对于原始数据v来说,不需要32个元素都copy一遍,而是直接把v的引用放到了v'的成员变量中。而对于index的过程例如查找v'[32],因为每个部分都记录了自己存储的元素长度,所以很容易就能找到位于suffix1部分的第0个位置。当然如果我们插入33不是尾部而是从头部的话,则会成为下面这种形式。
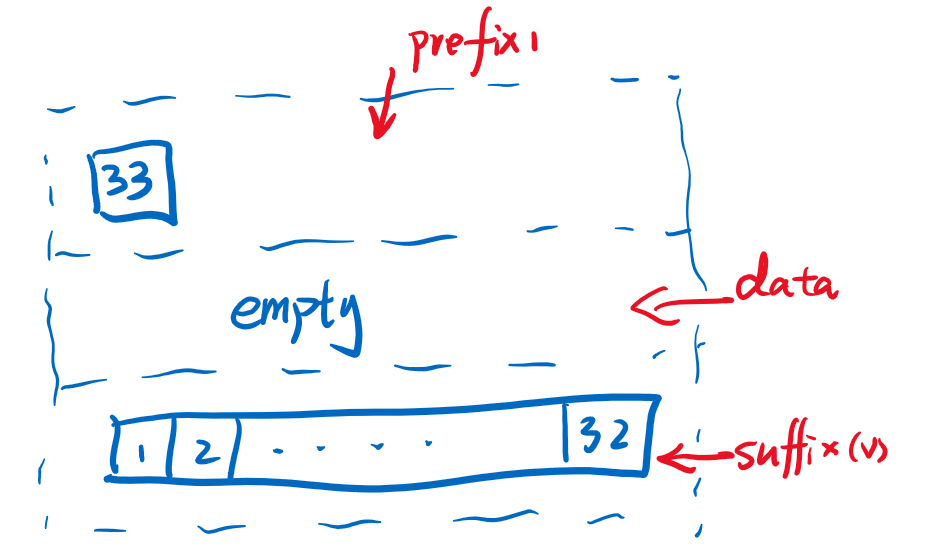
我们继续插入,当从尾部继续插入的时候,只需要对suffix1这个Arr1进行扩容就可以了,其他两部份直接引用过来即可。
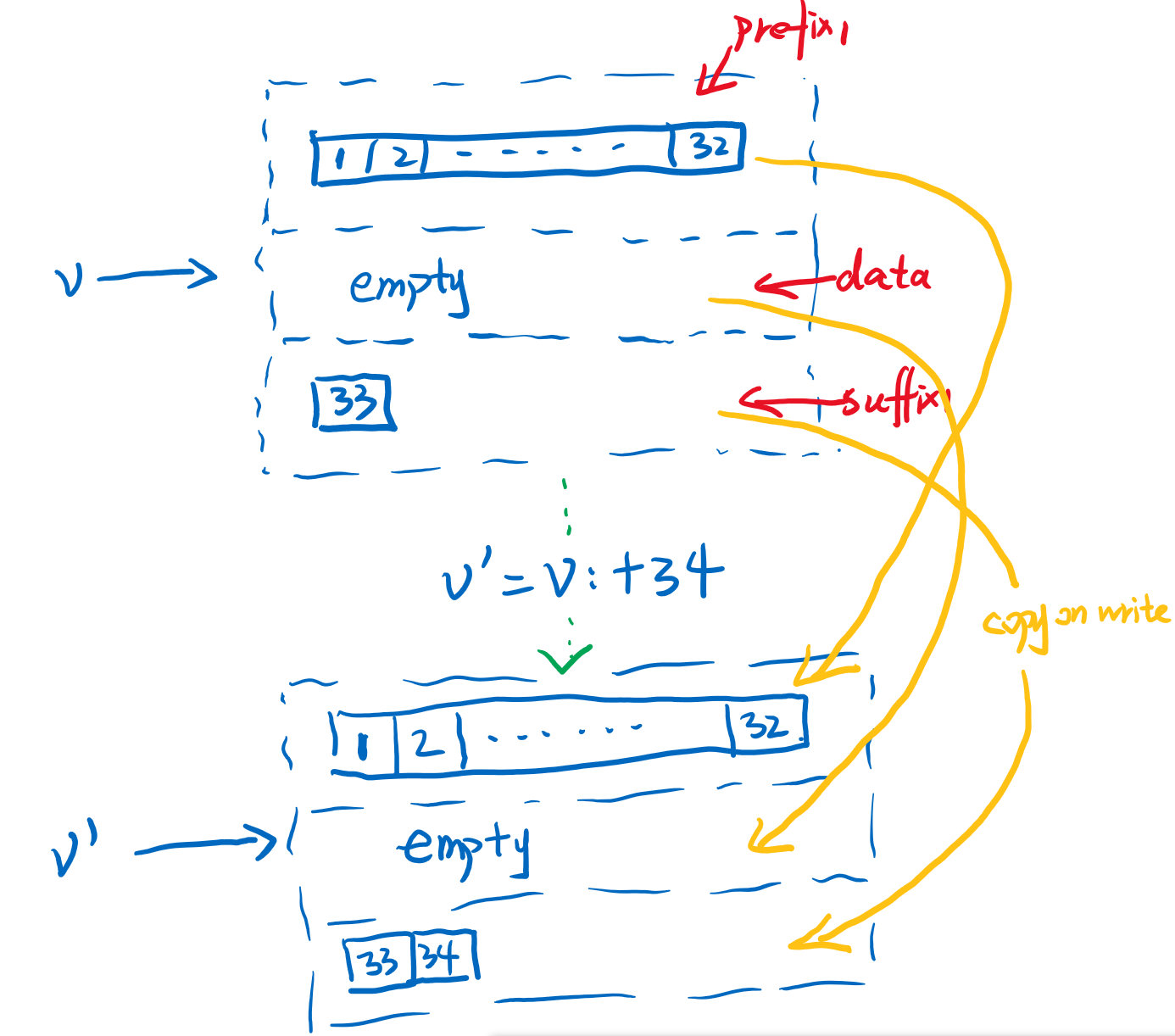
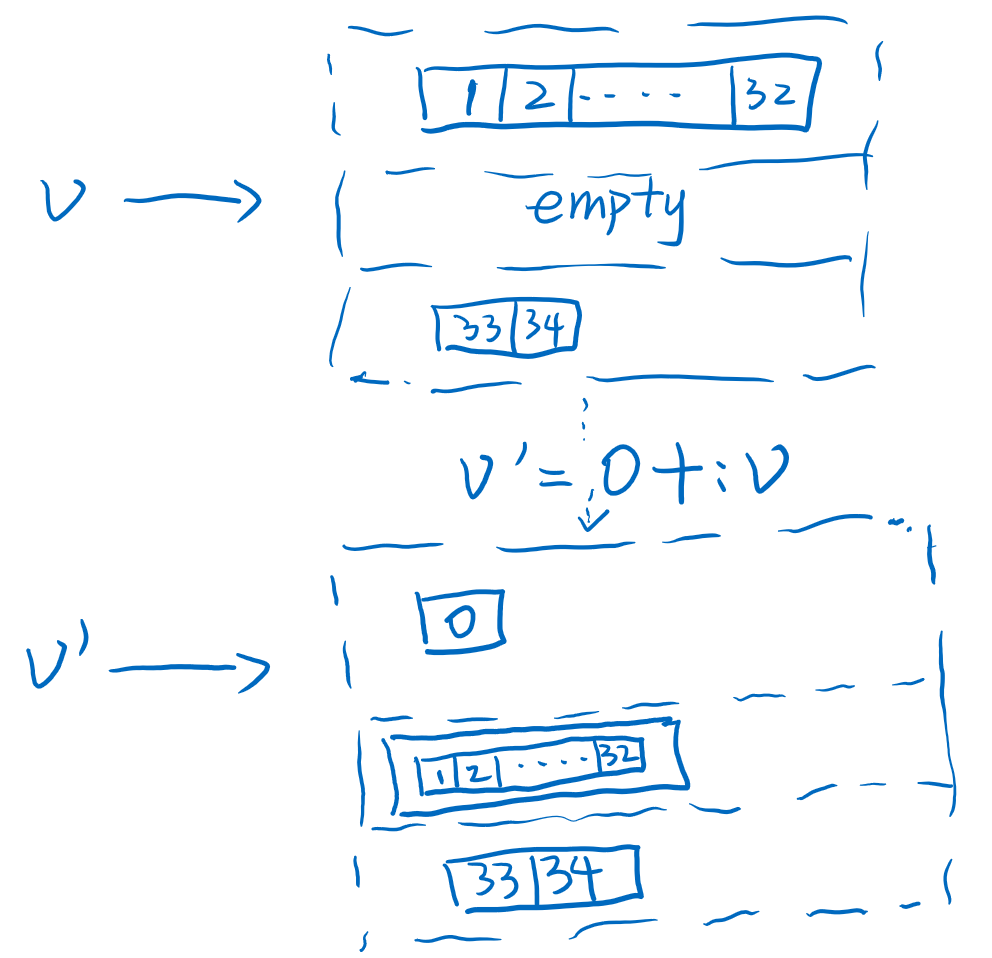
当suffix1满了之后,或者插入完34,又对头部进行插入0的时候,就会出现进位,即Arr1进到data中。以插入0到head为例,如下图。data部分是二维数组Arr2,二维数组长度是1,唯一的一个元素是个Arr1也就是原来的prefix1,这就是进位,即当prefix1或者suffix1在扩容的过程中超过块的最大规定长度32的时候,会把整个Arr1进位到data这个二维数组的头(prefix1)或者尾部(suffix1)。
进位的过程其实就是data部分从长度l扩容为l+1的过程,并且二维数组Arr2最大长度l也是32,所以进位过程中的copy最多也只有32次。对于Arr2的扩容过程中对内部元素Arr1的copy就是引用copy了,不需要再对Arr1中的32个元素再深度拷贝了,因而对于写操作来说Vector最差情况是O(32)的复杂度,他还保证了原始变量确实没有受到改变,是一种将不可变和高效写操作结合的数据结构。
当Vector2的data部分达到了32长度的时候,又会进化为Vector3,他的结构是5部分组成prefix1 + prefix2 + data + suffix2 + suffix1,其中1后缀的是Arr1,2后缀的是Arr2类型,data则是Arr3三维数组了。
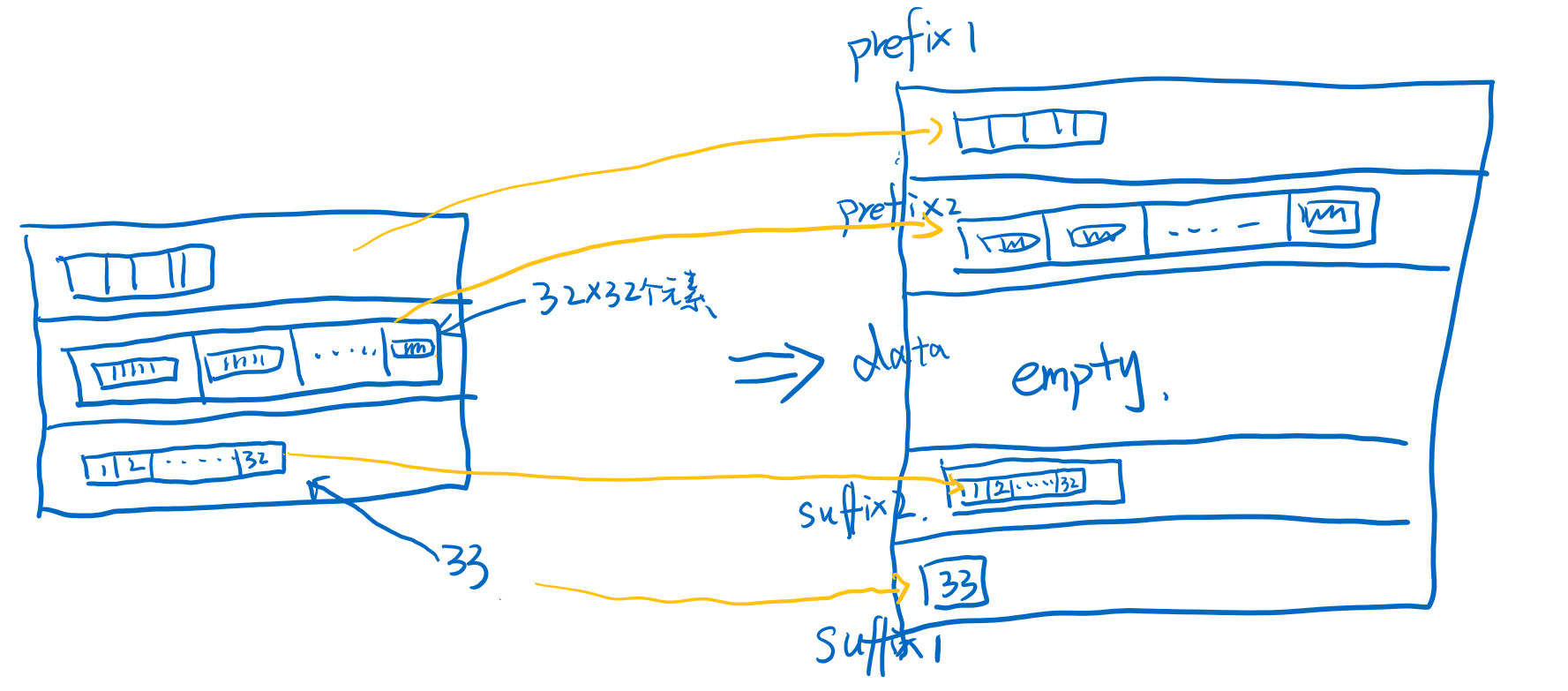
后续就的形式Vector4-6不展开了,类似的。结论就是Vector通过对每32个元素进行封块,对32^n也进行封块,对于一个块的copy是整体引用的copy,而对于两头的append和pre-append都是对一维数组的操作,如果发生进位则是对二维数组的操作,对于元素的拷贝最多都是32次。
而对于update操作,也只需要拷贝所在的这一层,最差也是个O(32*6层)也算是个常数级别的复杂度。
整体看下来,Vector是非常强大的数据结构,读O(1)写O(1)的复杂度并且保持了原始数据immutable,在大多数场景都表现就好。
vectors strike a good balance between fast random selections and fast random functional updates,
mutable.Seq
scala的mutableSeq例如
- 默认实现,
ListBuffer类似java的LinkedList,因为记录了head和tail元素,所以尾部插入也是O(1)。用+=或append/prepend写入。 ArrayBuffer类似java的ArrayList,底层也是数组,稍有不同的是,数组长度与数据长度保持一致,每次插入都需要扩容。
immutable.Map
这个在java_Map一节中讲过,使用了trie tree的底层结构,也是保持了不错的写入性能的同时,对只读特性进行了支持,达到了一种很好的时间复杂度和空间复杂度的平衡。
mutable.Map
与java的HashMap实现基本一致,小区别是没有红黑树部分