background
要说最近什么比较火,那肯定是openAI的chatGPT了,当然这一波AI浪潮除了chatGPT还有一些其他的AI产品,例如绘图类的AI,还有new bing的chat等。
一般我们都在浏览器的chat窗口中直接chat,但是想要将其集成到自己的系统中,就需要调用其API。
openAI
openAI其实在chatGPT之前就有多种api,我们就以前端时间最新公开的chat的API和whisperAPI为例。
需要注意的是api国内环境直接调用经常不通,最好是将代码写好之后部署到一些免费的faas平台,比如railway/vercel/netlify等等。
1 chatAPI
根据openAI官网的介绍,只需要在个人中心生成自己的KEY,然后作为httpHeader中的Authorization,进行post请求,传入合适的json格式即可了,curl指令如下。
其中message部分的content就是用户提出的问题,前面的role是user,也就是用户提出的问题。
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "中国四大名著是哪四个"}]
}'
另外介绍几个重要参数
- n:默认是1,返回的回答数
- temperature: 默认是1,取值为0~2,越高则回答越发散越有创造力,越低则越准确和严格
- top_p: 默认是1,取值应该是0~1.作用与temperature类似,官方建议不要同时修改两者,
- max_tokens: 默认INF(无限)当前请求能使用的token数(token是请求的问题和返回的回答都占用token,一个字基本是一两个token)这个可以很好的限制开销(目前gpt3.5的计费是1000token=$0.0002)
- stream: 默认是false,因为是http2的server,可以支持stream形式返回数据,需要用专门的client接收eventStream数据,这样的回答是一个字一个字的返回,如果false,则是全生成完了,再返回,等待时间较长。
当我们获得答案的时候,response可能如下,可以看到返回有个choice的数组,其中只有一个选项,因为n默认值就是1,即返回一个choice,message部分结构与请求类似,只不过role是assistant。usage部分介绍了当前这个请求token的使用量,可以对费用有个数。
{
"id": "xxxxx",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "1 三国演义 2 西游记 3 水浒传 4 红楼梦"
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
如果我们想继续有上下文的去询问,需要把message列表叠加,如下:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "中国四大名著是哪四个"},
{"role": "assistant", "content": "1 三国演义 2 西游记 3 水浒传 4 红楼梦"},
{"role": "user", "content": "他们的作者分别是谁"},
]
}'
不断叠加的message提供了上下文信息,但是也增加了prompt_tokens的数量,也就需要付更多的钱咯。
除了assistant和user两个role还有个system的role,用来规定一些基本的准则。
$ export API_KEY=sk-xxxxxxxxx
$ curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "请都用英文回答我的问题"},
{"role": "user", "content": "中国四大名著是哪四个"}
]
}'
返回
...
"message":{
"role": "assistant",
"content": "The four classic novels of Chinese literature are: \n\n1. \"Journey to the West\" (西游记)\n2. \"Dream of the Red Chamber\" (红楼梦)\n3. \"Romance of the Three Kingdoms\" (三国演义)\n4. \"Water Margin\" (水浒传)"
}
...
关于stream模式返回,可以用一些http2的客户端库,当然openai官方提供了nodejs和Python的库,参考当前目录下./ai/chat.js的代码。
2 whisper API
$ export API_KEY=sk-xxxxxxxxx
$ curl https://api.openai.com/v1/audio/transcriptions \
> -H "Authorization: Bearer $API_KEY" \
> -H "Content-Type: multipart/form-data" \
> -F file="@测试.m4a" \
> -F model="whisper-1"
要想体验whisper的功能也还有其他办法,因为whisper代码开源,github连接,安装与运行的方式也在git中详细的介绍了。
- 1 安装whisper
pip install openai-whisper - 2 安装ffmpeg,这个之前刚好介绍过,安装很简单
- 3 安装rust
因为whisper是基于pytorch这一套框架的所以第一步pip安装的时候会顺带安装pytorch等工具链,但是安装的可能是cpu版本的,如果显卡是NVIDIA的,那么可以考虑更新cuda驱动,并重新安装为cuda显卡版本的。方法如下:
- 1 到nv-cuda下载适合自己的cuda版本,并用管理员身份安装好,我这里选11.7版本。
- 2 安装torch,torchvision,torchaudio三个库,对应cuda117版本的对应版本如下,cu117就是11.7的意思,如果安装的不是117可以到torch版本列表下找对应库的对应的cuda版本。
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1+cu117 -f https://download.pytorch.org/whl/torch_stable.html
上述安装完成后,通过whisper -h可以看到默认的device是cuda而不是cpu了。
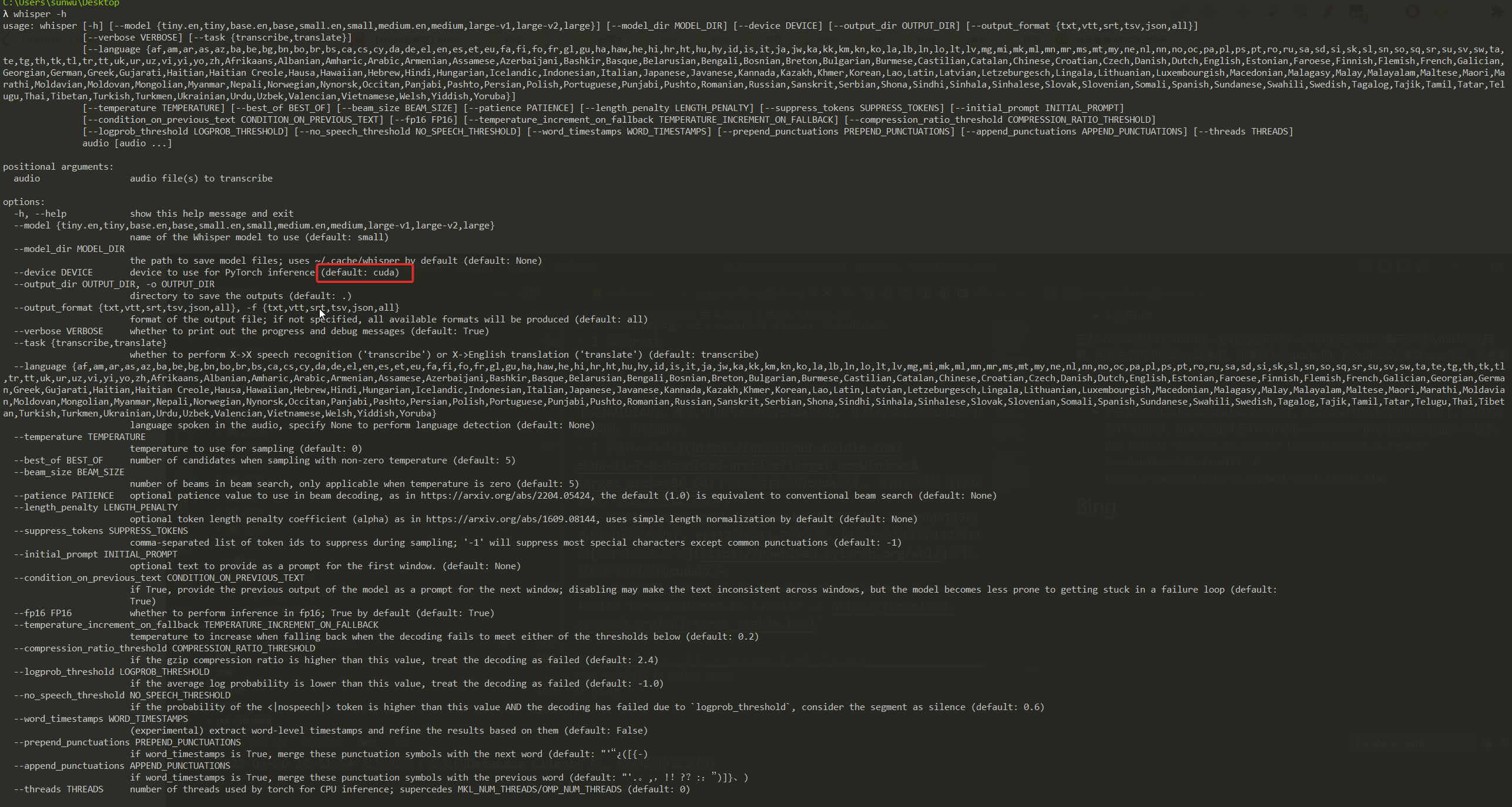
然后可以开始使用了
$ whisper xx.mp3 --language Chinese
默认是small的模型,可以更换为medium或者large但是large占用的显存很大,我的显卡较老GTX1060 6G显存溢出报错了,所以large的目前只能用cpu
$ whisper xx.mp3 --language Chinese --model medium
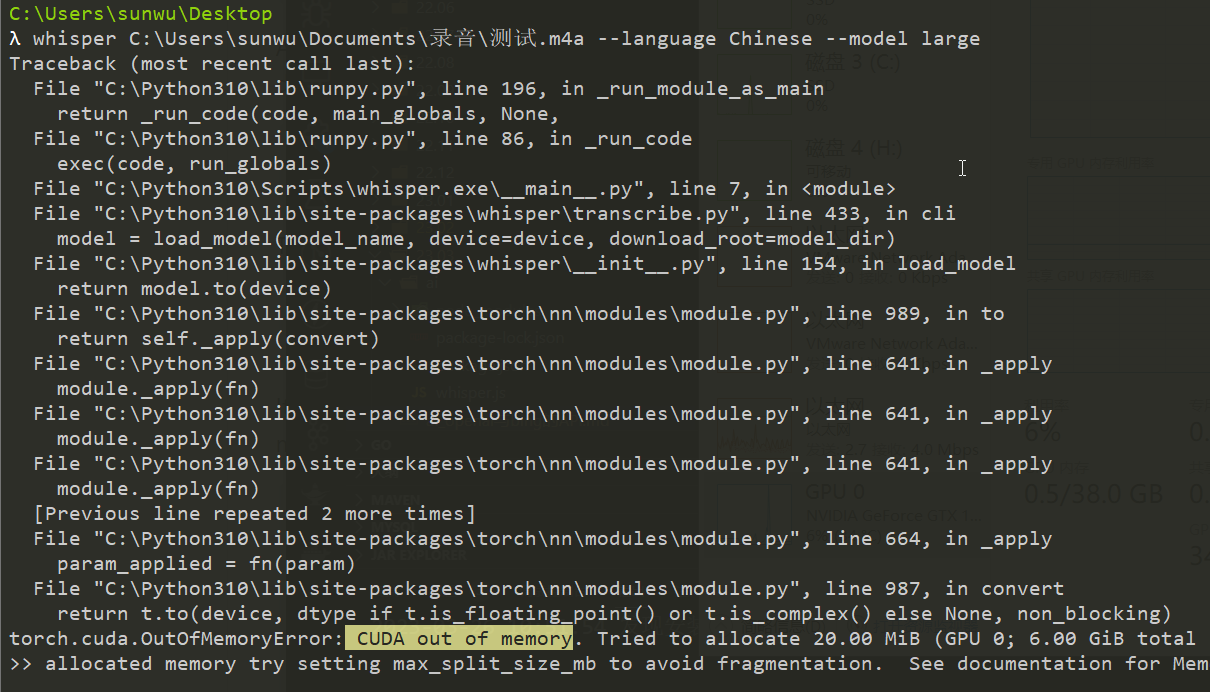
注意使用cpu,占用的会是内存而不是显存,此时内存占用在7G以上。
$ whisper xx.mp3 --language Chinese --model large --device cpu

模型越大越准确,但是需要的资源和计算时间会越长。openai的api用的是whisper large-v2模型,但是几秒就能返回,服务器计算力较强的原因。
Bing
Bing没有公开官方的API但是可以使用cookie来进行访问,有对应的一些库进行了封装。首先需要在edge浏览器登录new bing,因为国内网络环境一直会跳转cn版本的bing是不行的,所以需要用vpn,然后在bing首页右上角的设置中将国家改为美国,此时就可以使用new bing了。
从cookie中找到一个_U的cookie,并复制他的值。
$ npm i bing-chat
创建index.mjs文件,mjs可以使用import语法。
import { BingChat } from 'bing-chat'
import fs from 'fs'
var msg = ""
for(var i = 2; i<process.argv.length; i++){
msg += ' ' + process.argv[i]
}
const api = new BingChat({
cookie: process.env.BING_COOKIE
})
async function example() {
const res = await api.sendMessage(msg, {
variant: 'Creative',
// print the partial response as the AI is "typing"
onProgress: (partialResponse) => {
console.clear()
console.log(partialResponse.text)
// fs.writeFileSync('answer.md', partialResponse.text)
}
})
// print the full text at the end
// console.log(res.text)
}
example()
requirements:
nodejs >= 18- bing cookie from bing.com, the cookie name is _U
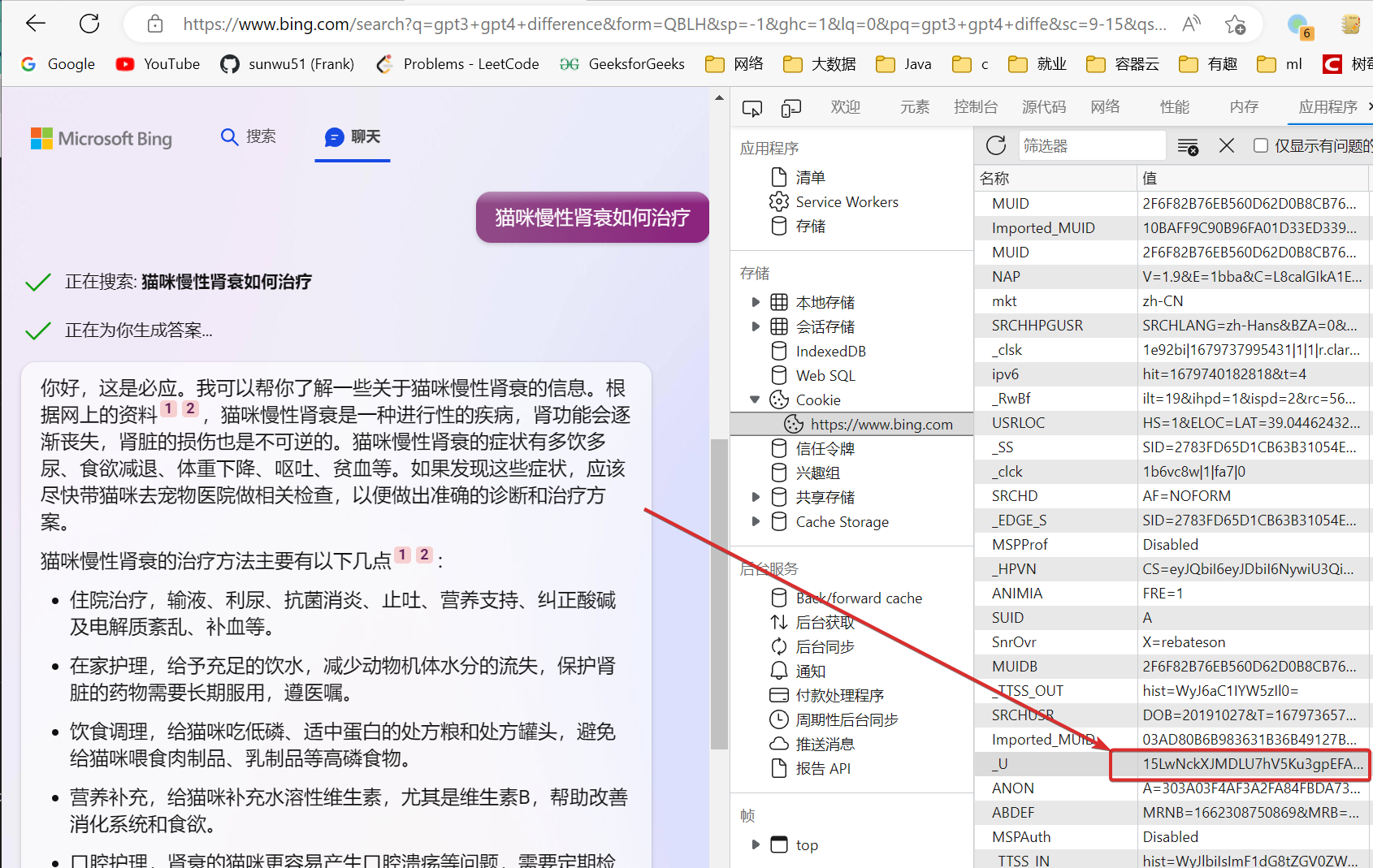
$ export BING_COOKIE=<your bing cookie>
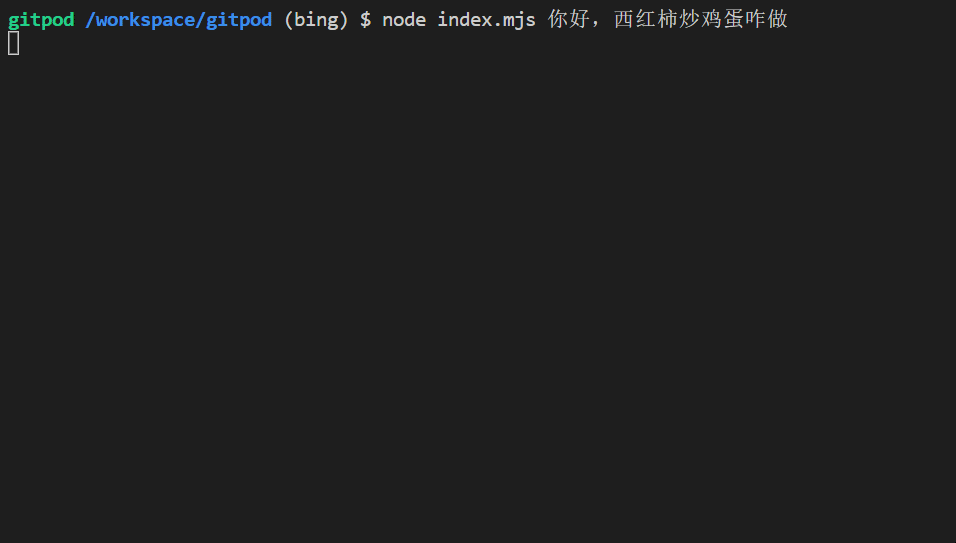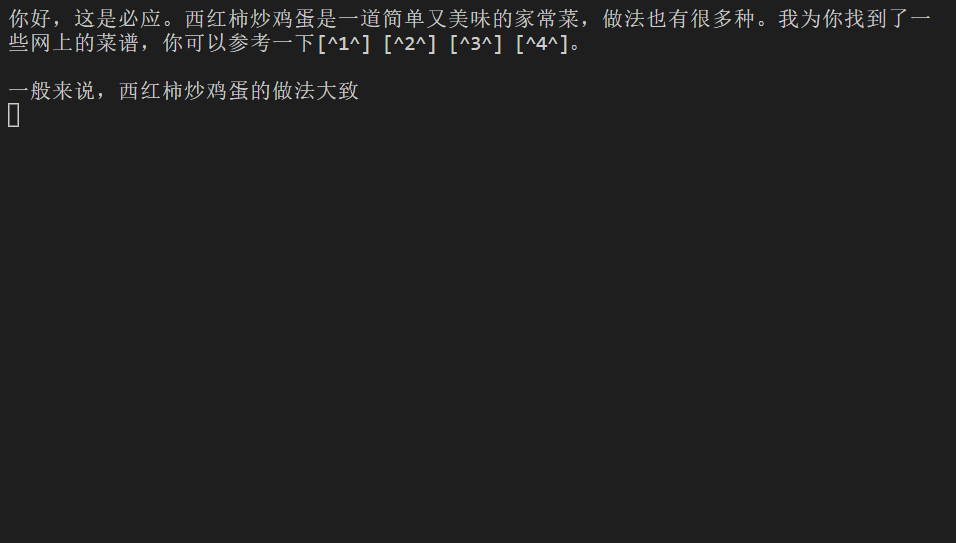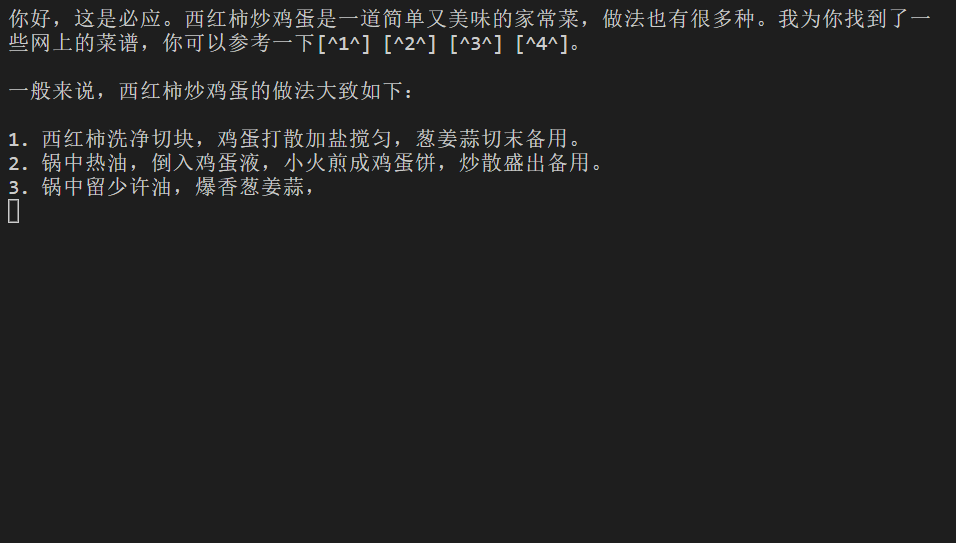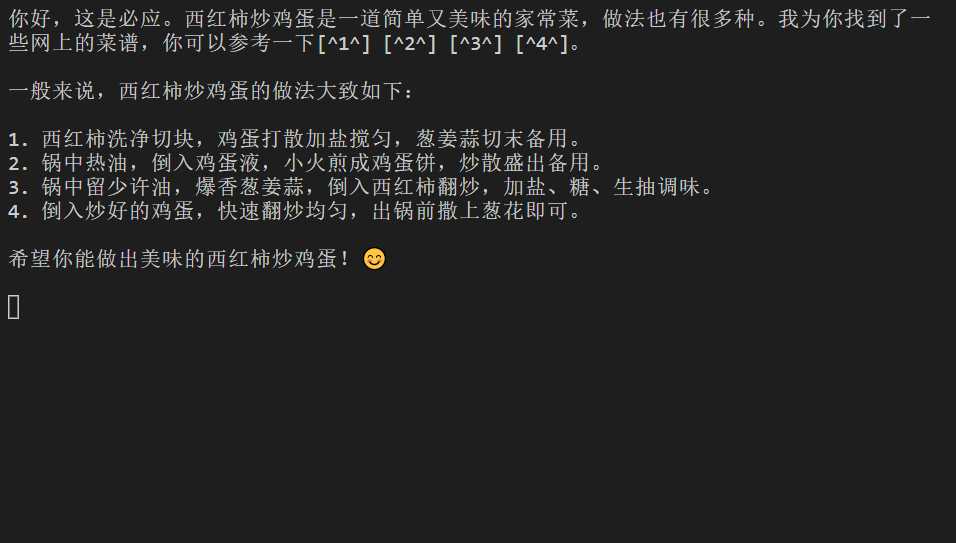
$ node index.mjs 你好,西红柿炒鸡蛋咋做