jackson
1 基本用法
jackson是java中常用的json序列化/反序列化的库。基本用法如下
第一步创建一个ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
序列化
String sam = objectMapper.writeValueAsString(new Person(1, "Sam", null));
反序列化
objectMapper.readValue("{\"id\": 1, \"name\":\"Sam\",\"parent\":null}", Person.class);
哪些字段可以序列化?
public的字段,或者有public getXX方法的字段,例如下面例子中name和parent可以被序列化成json列,id则被忽略。
class Person {
int id;
String name;
public Person parent;
public String getName() {
return this.name;
}
}
而如果将getName进行修改如下,则json的列名会变为"n"
// {"n": "Sam"}
String name;
public String getN() {
return this.name;
}
比较变态的如果列是public,同时又给了public的get方法,但是返回的数据还不一样。会以列优先级更高。
// {"name": "Sam"}
public String name;
public String getName() {
return this.name + "!!!";
}
哪些字段可以反序列化?
与序列化是对称的,public或者有public setXxx方法的字段可以被反序列化。
嵌套类型会递归进行序列化
上面例子中Person类型有个parent字段是复杂类型,该项有值可以递归进行序列化,但是如果出现循环,则会抛出异常。
含有泛型的反序列化
需要借助TypeReference来将泛型类作为该匿名类型的泛型部分,而不能直接用Map<String,String>.class,因为本身的泛型会被擦除,作为对象的参数则可以保留,最后一节展开讲。
Map<String, String> xx = mapper.readValue(s, new TypeReference<Map<String,String>>() {});
2 修改json字段名或者忽略字段
当java类中field名称保持不变,想要修改Json中的字段名,则可以使用@JsonProperty("xxx")注解
// {"myName": "Sam"}
@JsonProperty("myName")
private String name;
而如果java类中必须有get方法,但是不想在反序列化的时候对外暴露,则可以使用@JsonIgnore添加到field上或者get方法上。
// {"age": "11"}
@JsonIgnore
public String name;
public int age
或者也可以在类上添加@JsonIgnoreProperties({ "internalId", "secretKey" }),来将多个字段ignore。
JsonIgnoreProperties还有个作用是忽略未知的json input field。下面进行反序列化的时候会报错,Unrecognized field "id" (class Person), not marked as ignorable
// {"id": 1, "name": "Sam"}
class Person {
public String name;
}
而给Person添加注解后则可以忽略不认识的id属性,下面写法则不报错。
// {"id": 1, "name": "Sam"}
@JsonIgnoreProperties(ignoreUnknown = true)
class Person {
public String name;
}
ignoreUnknown是常用的策略,也可以在objectMapper中全局配置。
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
3 修改Naming策略
默认的名称策略是json与java保持一致,java一般为小写驼峰,因而json也是如此。
// {"firstName": "Sam"}
String firstName;
通过@JsonNaming可以修改某一列或者整个类的映射方式,例如下面代码将该field修改为kebab横线的命名方式。
// {"first-name": "Sam"}
@JsonNaming(
value = PropertyNamingStrategy.KebabCaseStrategy.class)
String firstName;
将该注解加到整个类上,则是对每个字段都生效,也可以直接加到ObjectMapper中,对所有类生效。
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategy.KEBAB_CASE);
4 枚举类型
在反序列化的时候,枚举类型可以识别字符串,也可以识别下标值。
// {"type": 0}
// {"type": "A"}
// 上面两种json都可以反序列化成功
class Person {
public Type type;
}
enum Type {
A,
B
}
但是对于序列化,默认是字符串A,如果想要用下标,可以使用相关策略。
objectMapper.configure(SerializationFeature.WRITE_ENUMS_USING_INDEX, true);
5 时间类型
时间类型也是一种除了基础类型之外常用的类型,例如Date,Timestamp,LocalDateTime,ZonedDateTime,Instant等,都是常用的时间类型。
@Getter
@Setter
class TimeSpec{
java.util.Date utilDate;
Date sqlDate;
Timestamp sqlTimestamp;
Instant instant;
LocalDate localDate;
LocalDateTime localDateTime;
ZonedDateTime zonedDateTime;
}
默认情况下,序列化行为如下,可以看到老的包下的类基本都是序列化为long,而time下的类都是有复杂子结构的,这是因为有这些get方法,这样的格式有很多问题,例如可读性差,长度冗余,因为没有对应的set方法,所以对于time下的类来说,序列化出来的json没有办法直接反序列化回去。为了能更好的支持time包下类的序列化,需要在Jackson中注册JavaTimeModule
{
"utilDate":1679973942379,
"sqlDate":1679973942379,
"sqlTimestamp":1679973942379,
"instant":{
"epochSecond":1679973942,
"nano":379000000
},
"localDate":{
"year":2023,
"month":"MARCH",
"monthValue":3,
"dayOfMonth":28,
"chronology":{
"id":"ISO",
"calendarType":"iso8601"
},
"era":"CE",
"dayOfYear":87,
"dayOfWeek":"TUESDAY",
"leapYear":false
},
"localDateTime":{
"year":2023,
"month":"MARCH",
"nano":379000000,
"monthValue":3,
"dayOfMonth":28,
"hour":3,
"minute":25,
"second":42,
"dayOfYear":87,
"dayOfWeek":"TUESDAY",
"chronology":{
"id":"ISO",
"calendarType":"iso8601"
}
},
"zonedDateTime":{
"offset":{
"totalSeconds":0,
"id":"Z",
"rules":{
"fixedOffset":true,
"transitions":[
],
"transitionRules":[
]
}
},
"zone":{
"id":"UTC",
"rules":{
"fixedOffset":true,
"transitions":[
],
"transitionRules":[
]
}
},
"year":2023,
"month":"MARCH",
"nano":379000000,
"monthValue":3,
"dayOfMonth":28,
"hour":3,
"minute":25,
"second":42,
"dayOfYear":87,
"dayOfWeek":"TUESDAY",
"chronology":{
"id":"ISO",
"calendarType":"iso8601"
}
}
}
5.1 注册module调整time包下的类的行为
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>${jackson-version}</version>
</dependency>
2.12以上的Jackson可以不用手动注入module了。
objectMapper.registerModule(new JavaTimeModule());
此时序列化出来的结果如下,该结果可以直接被注册module后的objectMapper反序列化。
{
"utilDate":1679974795838,
"sqlDate":1679974795838,
"sqlTimestamp":1679974795838,
"instant":1679974795.838000000,
"localDate":[2023,3,28],
"localDateTime":[2023,3,28,3,39,55,838000000],
"zonedDateTime":1679974795.838000000
}
5.2 序列化不用时间戳形式
时间戳可读性还是有点差,通过配置策略,可以展示可读性更好的ISO形式,下面是配置方式和json格式。
objectMapper.registerModule(new JavaTimeModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
{
"utilDate":"2023-03-28T03:44:38.889+0000",
"sqlDate":"2023-03-28",
"sqlTimestamp":"2023-03-28T03:44:38.889+0000",
"instant":"2023-03-28T03:44:38.889Z",
"localDate":"2023-03-28",
"localDateTime":"2023-03-28T03:44:38.889",
"zonedDateTime":"2023-03-28T03:44:38.889Z"
}
在注册JavaTimeModule后反序列化是同时支持时间戳和这种ISO形式的,不需要再配置反序列化feature。
5.3 反序列化支持的形式
下面的time下的类都是注册了JavaTimeModule的情况下来讨论的。
先列出一些序列化之后的格式,下面的代表可以存在也可不存在。
- 1 毫秒时间戳 = 1679974795838
- 2 秒.纳秒时间戳 = 1679974795.838000000
- 3 ISO_LOCAL_DATE = 2023-03-28
- 4 ISO_LOCAL_TIME =
03:44:{38{.9位以内数字}} - 5 ISO_LOCAL_DATE_TIME = ISO_LOCAL_DATE + 'T' + ISO_LOCAL_TIME
- 6 ISO_DATE_TIME = ISO_LOCAL_DATE_TIME +
{offsetId{[zoneRegionId]}} - 7 ISO_ZONED_DATE_TIME = ISO_LOCAL_DATE_TIME + offsetId +
{[zoneRegionId]} - 8 ISO_LOCAL_DATE_TIME + offsetId = 7 不含
[zoneRegionId]
这里尤其要注意有些形式例如ISO_ZONED_DATE_TIME他其实有很多种合法的形式,下面都是合法的:
- 2023-03-28T03:44Z
- 2023-03-28T03:44:22+01:00
- 2023-03-28T03:44:22.12+02:30
- 2023-03-28T03:44:22.123456789-03:00
- 2023-03-28T03:44:22.123+03:00[UTC]
- 2023-03-28T03:44:22.123-04:00[America/New_York]
- 2023-03-28T03:44:22.123-04:00[-05:00]
- 2023-03-28T03:44:22.123-04:00[UTC-05:00]
上面例子中offsetId取值Z就是utc时区,取值+01:00则代表的是+1时区,而[UTC]和[America/New_York]以及[-05:00]等代表的则是zoneRegionId,即zoneId或RegionId,Region都有哪些可以参考Time Zone Database (TZDB)。虽然这一部分是选填项,是对offsetId的补充说明,但是如果和offsetId存在冲突的话,实际上是以这部分为准,上面最后2个实际生效的是-5时区。
我们回到JacksonTime的反序列化:
- Date支持1,3,5,8其中135不含时区信息,自动应用机器当前时区,例如:如果当前机器+8,传入的是-8的,那么实际的日期可能会是前一天。
- Timestamp也是1,3,5,8。和Date一样,这些都是老包,即都是基于毫秒时间戳的统一行为。
- LocalDate支持3,5,因为没有时区所以时间戳和带时区的都不支持
- LocalDateTime只支持5,必须有时间部分,所以不支持3
- ZonedDateTime支持2,7,有时区,且是新的time包要用2这种时间戳形式,然后支持7,多种时区的表示方式。
- Instant支持2和8并且时区只能是Z,其他写法如+01:00会报错。
当然也可以不记这些规则,直接用@JsonFormat设置一个pattern即可,注意pattern中的Z,写法是Z +0800等形式,而不是+08:00。
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ssZ")
ZonedDateTime zonedDateTime;
@JsonFormat还可以用于类型的隐式转换,例如一个int值想要用String在json中表示,当然也可以是Float和Int转换,Float转Int会向下取整。
@JsonFormat(shape = JsonFormat.Shape.STRING)
public int Age;
小结:
对于时间的表达,建议使用ZonedDateTime和LocalDateTime来准确的表达时间,ZonedDateTime在反序列化的时候支持的形式比较灵活,最放心的写法是用@JsonFormat来制定时间pattern。
6 子类型
对于继承关系的子类型例如下面三个类,当序列化的时候,按照之前的原则是会序列化具有public和public getXX方法的属性,因而对于一个子类型Woman/Man的age不会被序列化。
class Person {
protected int age;
public String name;
}
class Woman extends Person {
public int realAge;
}
class Man extends Person {
public String realName;
}
而对于反序列化,如果确定具体的类型的话,就和之前一样。
Woman woman = mapper.readValue("{\"name\":\"www\",\"realAge\":12}", Woman.class);
但是如果json字符串只知道是Person类型,需要动态的运行时确定是哪个具体的类型,这里就会失败了,此时最简单的方法就是Person上添加注解。
@JsonTypeInfo(use = JsonTypeInfo.Id.CLASS, property = "class")
class Person {
protected int age;
public String name;
}
// {"class":"com.jackson.Woman","name":"www","realAge":12}
简单解释下这两个重要参数,property是指定某个属性作为区分子类型的依据,该property可以是pub/private/protect的属性或者get方法,有了这个注解修饰后,即使不public的也会作为json字段序列化。这里选择用getClass这个所有Object都有的property,如果有专门的字段,例如自定义的字段,也可以将class改为自己的字段名。然后use则是决定上面的属性是如何区分的,Id.CLASS就是全限定类名进行区分。
不过class这种全限定类名的方式,在json中比较长,不太友好,所以可指定自定义的一个字段来进行区分。配合@JsonSubTypes来使用,例如下面使用Id.NAME形式,并指定sex字段来区分。
// sex = female的会按照Woman类型反序列化, sex = male的会按照Man类型
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, property = "sex")
@JsonSubTypes({
@JsonSubTypes.Type(value = Woman.class, name = "female"),
@JsonSubTypes.Type(value = Man.class, name = "male")})
class Person {
protected String sex;
protected int age;
public String name;
}
class Woman extends Person {
public int realAge;
{
sex = "female";
}
}
class Man extends Person {
public String realName;
{
sex = "male";
}
}
7 自定义序列化和反序列化
最灵活的方式莫过于自定义序列化和反序列化器,例如想要改变X类中Map的默认序列化反序列化行为,给该字段添加注解,指定自定义的序列化器
class X {
@JsonSerialize(using = MyMapSer.class)
@JsonDeserialize(using = MyMapDes.class)
public Map<String, String> m;
}
对于序列化器,如下定义,使map最终呈现成kv数组的形式。其中writeStartArray就是添加[,end就是],而writeStartObject则是{,end是}。
// {"m":[{"key":"k1","value":"v1"},{"key":"k2","value":"v2"},{"key":"k3","value":"v3"}]}
class MyMapSer extends JsonSerializer<Map<String, String>> {
@Override
public void serialize(Map<String, String> value, JsonGenerator gen, SerializerProvider serializers) throws IOException {
gen.writeStartArray();
for (Map.Entry<String, String> entry : value.entrySet()) {
gen.writeStartObject();
gen.writeStringField("key", entry.getKey());
gen.writeStringField("value", entry.getValue());
gen.writeEndObject();
}
gen.writeEndArray();
}
}
对于反序列化器,如下,其中jsonParser可以转为tree的根节点JsonNode,因为这里是数组节点,我们可以直接用ArrayNode这个类型然后对map进行填充并返回。
// {"m":[{"key":"k1","value":"v1"},{"key":"k2","value":"v2"},{"key":"k3","value":"v3"}]}
class MyMapDes extends JsonDeserializer<Map<String, String>> {
@Override
public Map<String, String> deserialize(JsonParser p, DeserializationContext ctxt) throws IOException, JsonProcessingException {
ArrayNode root = p.readValueAsTree();
Map<String, String> res = new LinkedHashMap<>();
for (JsonNode jsonNode : root) {
res.put(jsonNode.get("key").textValue(), jsonNode.get("value").textValue());
}
return res;
}
}
8 其他注解
@JsonAlias("_n","Name","name")别名@JsonInclude设置序列化时,字段在什么情况下被include,例如可以配置null值就不include到json,来减少数据量@JsonInclude(JsonInclude.Include.NON_NULL)- 等等
9 原理
9.1 序列化的原理
序列化的原理较为简单,基本的思路就是通过反射拿到类型中的public的字段或get方法,作为可以然后逐个字段进行json字符串的追加,默认使用的是BeanSerializer,可以去查看里面的代码。而对于Collection的序列化反序列化则是单独的,因为都比较简单,这里不展开。
9.2 反序列化的原理
反序列化稍微复杂,需要重点介绍一下,还是以最基础的Bean为例,反序列化的时候根据传入的class通过反射就知道有哪些属性需要被set,其中最重要的就是上面JsonDeserializer方法中的参数JsonParser是如何工作的。因为JsonParser能将字符串转为JsonNode,这是个树状的节点,通过这个类可以很容易的转换成任意类型,所以我们专门来看一下这个readValueAsTree是如何工作的。
{"name":"Sam", "age":10, "parent": {"name": "Tom"}}以这个字符串为例,parser会逐个字符的处理,indexPtr代表处理到第几个char了。下面是最核心的代码
protected final ObjectNode deserializeObject(JsonParser p, DeserializationContext ctxt,
final JsonNodeFactory nodeFactory) throws IOException
{
final ObjectNode node = nodeFactory.objectNode();// node = {} 一开始 空的壳子
// nextFieldName 需要保证token是FIELD_NAME,然后去获取这个name。ptr向下寻找到",然后找到俩"之间的字符串就是这个key
String key = p.nextFieldName();
for (; key != null; key = p.nextFieldName()) {
JsonNode value;
// next操作都会向后移动,此时token指向VALUE了,根据形态可以判断出是哪一种value
// 例如双引号是字符串有-号或0到9是数字,{是另一个对象,[则是数组等
JsonToken t = p.nextToken();
if (t == null) { // can this ever occur?
t = JsonToken.NOT_AVAILABLE; // can this ever occur?
}
switch (t.id()) {
// 第三次以parent进来,此时token是对象的start(也就是{),那就递归解析对象
// 这个内部对象解析完成后,ptr指向最后一个大括号了,再次调用next会close,并返回null,循环结束
case JsonTokenId.ID_START_OBJECT:
value = deserializeObject(p, ctxt, nodeFactory);
break;
case JsonTokenId.ID_START_ARRAY:
value = deserializeArray(p, ctxt, nodeFactory);
break;
case JsonTokenId.ID_EMBEDDED_OBJECT:
value = _fromEmbedded(p, ctxt, nodeFactory);
break;
// 例如一开始的Sam是字符串,匹配这个case,getText会找出Sam,并将ptr指向Sam后的逗号
// 然后循环继续,去拿nextFieldName,skip逗号空格,拿到age
case JsonTokenId.ID_STRING:
value = nodeFactory.textNode(p.getText());
break;
// 第二次age进来匹配INT数字,用_fromInt转换,同时移动ptr到10后的逗号
// 然后继续循环找到parent这个key
case JsonTokenId.ID_NUMBER_INT:
value = _fromInt(p, ctxt, nodeFactory);
break;
case JsonTokenId.ID_TRUE:
value = nodeFactory.booleanNode(true);
break;
case JsonTokenId.ID_FALSE:
value = nodeFactory.booleanNode(false);
break;
case JsonTokenId.ID_NULL:
value = nodeFactory.nullNode();
break;
default:
value = deserializeAny(p, ctxt, nodeFactory);
}
JsonNode old = node.replace(key, value);
if (old != null) {
_handleDuplicateField(p, ctxt, nodeFactory,
key, node, old, value);
}
}
return node;
}
下面是一个很重要的,nextToken方法,上面nextXXX基本都会调用该方法,展示了是如何判断当前是那种VALUE,也展示了如果是inObject,是如何获取FieldName的值的。
@Override
public final JsonToken nextToken() throws IOException
{
if (_currToken == JsonToken.FIELD_NAME) {
return _nextAfterName();
}
// But if we didn't already have a name, and (partially?) decode number,
// need to ensure no numeric information is leaked
_numTypesValid = NR_UNKNOWN;
if (_tokenIncomplete) {
_skipString(); // only strings can be partial
}
// 跳过空格等字符后的下一个字符
int i = _skipWSOrEnd();
if (i < 0) { // end-of-input
// Should actually close/release things
// like input source, symbol table and recyclable buffers now.
close();
return (_currToken = null);
}
// clear any data retained so far
_binaryValue = null;
// Closing scope?
if (i == INT_RBRACKET || i == INT_RCURLY) {
_closeScope(i);
return _currToken;
}
// Nope: do we then expect a comma?
if (_parsingContext.expectComma()) {
// 跳过逗号
i = _skipComma(i);
// Was that a trailing comma?
if ((_features & FEAT_MASK_TRAILING_COMMA) != 0) {
if ((i == INT_RBRACKET) || (i == INT_RCURLY)) {
_closeScope(i);
return _currToken;
}
}
}
/* And should we now have a name? Always true for Object contexts, since
* the intermediate 'expect-value' state is never retained.
*/
boolean inObject = _parsingContext.inObject();
if (inObject) {
// First, field name itself:
_updateNameLocation();
String name = (i == INT_QUOTE) ? _parseName() : _handleOddName(i);
_parsingContext.setCurrentName(name);
_currToken = JsonToken.FIELD_NAME;
i = _skipColon();
}
_updateLocation();
// Ok: we must have a value... what is it?
JsonToken t;
switch (i) {
case '"':
_tokenIncomplete = true;
t = JsonToken.VALUE_STRING;
break;
case '[':
if (!inObject) {
_parsingContext = _parsingContext.createChildArrayContext(_tokenInputRow, _tokenInputCol);
}
t = JsonToken.START_ARRAY;
break;
case '{':
if (!inObject) {
_parsingContext = _parsingContext.createChildObjectContext(_tokenInputRow, _tokenInputCol);
}
t = JsonToken.START_OBJECT;
break;
case '}':
// Error: } is not valid at this point; valid closers have
// been handled earlier
_reportUnexpectedChar(i, "expected a value");
case 't':
_matchTrue();
t = JsonToken.VALUE_TRUE;
break;
case 'f':
_matchFalse();
t = JsonToken.VALUE_FALSE;
break;
case 'n':
_matchNull();
t = JsonToken.VALUE_NULL;
break;
case '-':
/* Should we have separate handling for plus? Although
* it is not allowed per se, it may be erroneously used,
* and could be indicate by a more specific error message.
*/
t = _parseNegNumber();
break;
case '.': // [core#61]]
t = _parseFloatThatStartsWithPeriod();
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
t = _parsePosNumber(i);
break;
default:
t = _handleOddValue(i);
break;
}
if (inObject) {
_nextToken = t;
return _currToken;
}
_currToken = t;
return t;
}
9.3 反序列化中的泛型擦除
Java的泛型是会在运行时擦除的,例如在运行时ArrayList<String>内部的存储结构是Object[]而不是String[],所以泛型更多是为了在写代码的时候提供一个校验,实际运行时会伴随着擦除。而当反序列化的类型中含有泛型参数的时候就会有点复杂。
例如最常见的集合类型Map,我们可以这样写代码,但是会有一个警告,因为readValue中传入的是Map所以返回的也是Map类型,相当于我们把Map强制转成了Map<String, String>,因为泛型擦除的原因,其实这俩是一个类型即Map,这一行并不报错,当运行到下一行get("a")的时候就会报错,因为get出来的对象本质上是Int类型,这里强制转为String就会报错
java.lang.Integer cannot be cast to java.lang.String,这种后知后觉其实是有很大隐患的,我们需要的是在json反序列化的时候就提前发现问题来抛出异常。
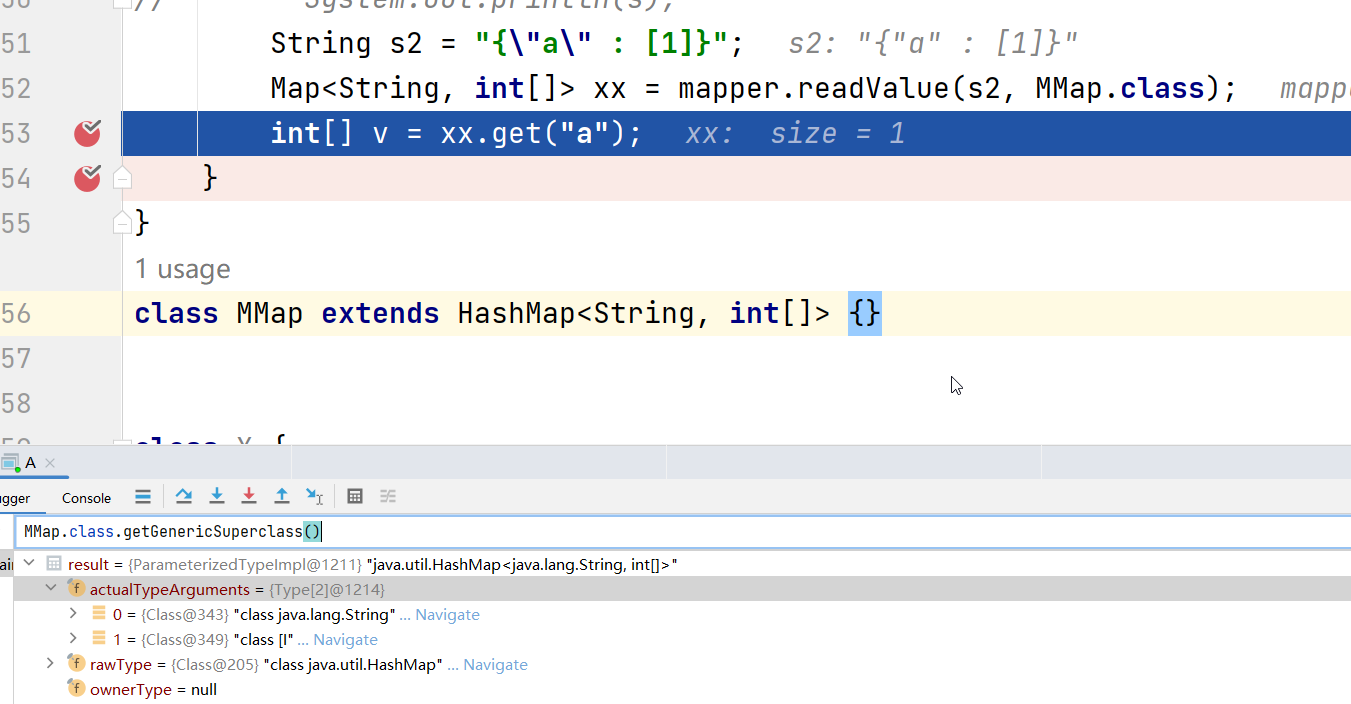
String s2 = "{\"a\" : 1}";
Map<String, String> xx = mapper.readValue(s2, Map.class); // Map<String,String>.class 没有这种写法,且就算有,因为擦除的原因也等于没写。
String v = xx.get("a");
首先解决方法是有两种,一种是传入指定泛型具体类型的对象.getClass,如下
String s2 = "{\"a\" : [1]}";
Map<String, int[]> xx = mapper.readValue(s2, new HashMap<String, int[]>(){}.getClass());
int[] v = xx.get("a");
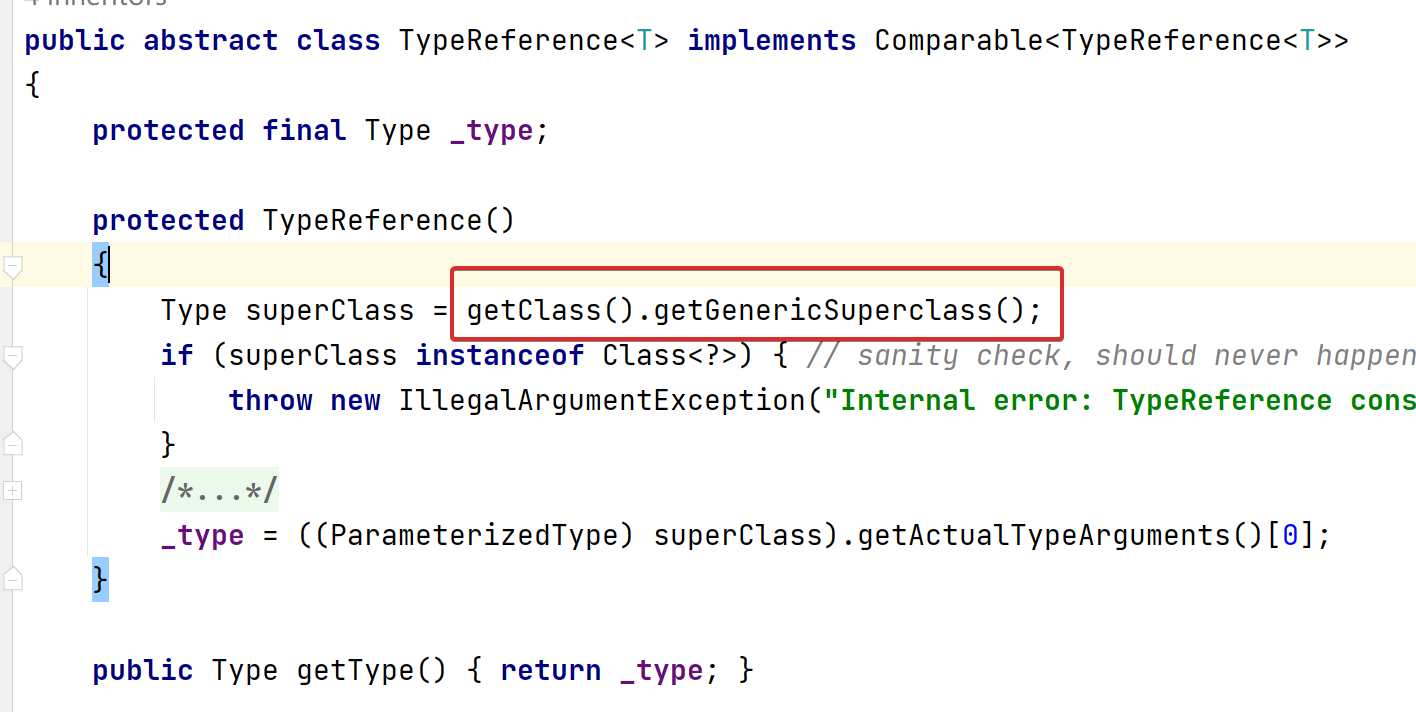
另一种方法则是使用jackson提供的TypeReference.
String s2 = "{\"a\" : [1]}";
Map<String, int[]> xx = mapper.readValue(s2, new TypeReference<Map<String, int[]>>(){});
int[] v = xx.get("a");
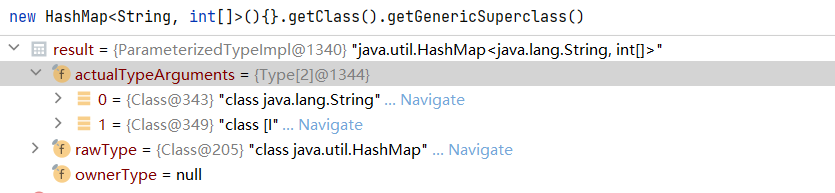
这两种方式底层原理一致,都是借助了object.getClass().getGenericSuperclass(),注意这个getGenericSuperclass方法返回的类型是Type而不是Class,Class是Type接口的一种实现而已,如果父类型是有泛型参数则返回的是ParameterizedType这个类型是含有泛型的信息的,如下图。下面两个方法都是通过一个实例化的对象,而不能直接用类,因为Map这个Class上是类型擦除的。
除了使用这种匿名类型的对象的getClass.getGenericSuperclass的方法也可以直接使用一个自定义的类,他们原理都是一样的。这个例子下我们就更好理解为什么java中需要有getGenericSuperclass方法,来获取父类中的泛型参数了,因为当前类的父类如果是Map,那么K和V的泛型可以指定死,如下,也可以依旧使用泛型,这个父类的泛型参数信息是需要记录在当前类中的(注意不是记录在父类Map中的),是当前类的字节码中的Signature中,通过反射可以获取到。到这里我们也能更好的理解java的类型擦除,其实是运行时对象中是的泛型类型约束不存在,但是类的元数据信息中是可以找到泛型信息的。