redis的数据结构
1 redis提供的基础类型和底层实现
redis是k-v存储,对于k部分都是string类型,而v则提供了五种基础的数据类型,分别是String,Hash,List,Set和Zset。
String底层可能使用的是int或embstr或raw(sds),当存入整数类型时使用int,当存入小数或者短字符串(小于39)使用embstr,否则使用raw。
Hash底层可能使用的是ziplist或hashtable,当所有键和值字符串都小于64字节,且键和值总数小于512个时,使用ziplist,否则用hashtable。
List底层可能使用的是ziplist或linkedlist,与上类似是所有元素都小于64字节,且总数小于512个时,使用ziplist,否则使用linkedlist。
Set底层可能使用的是intset或hashtable,如果元素都是整数,且不超过512个,则使用intset,否则使用hashtable。
Zset底层可能使用的是ziplist或skiplist,当元素长度均小于64字节,并且总数小于128时,使用ziplist否则使用skiplist。
上面的介绍中我们发现每一种数据类型的底层都可能有至少2种的编码方式,主要是考虑到在小数据的时候应优先考虑空间使用率,而大数据的时候应优先考虑计算复杂度。
2 String
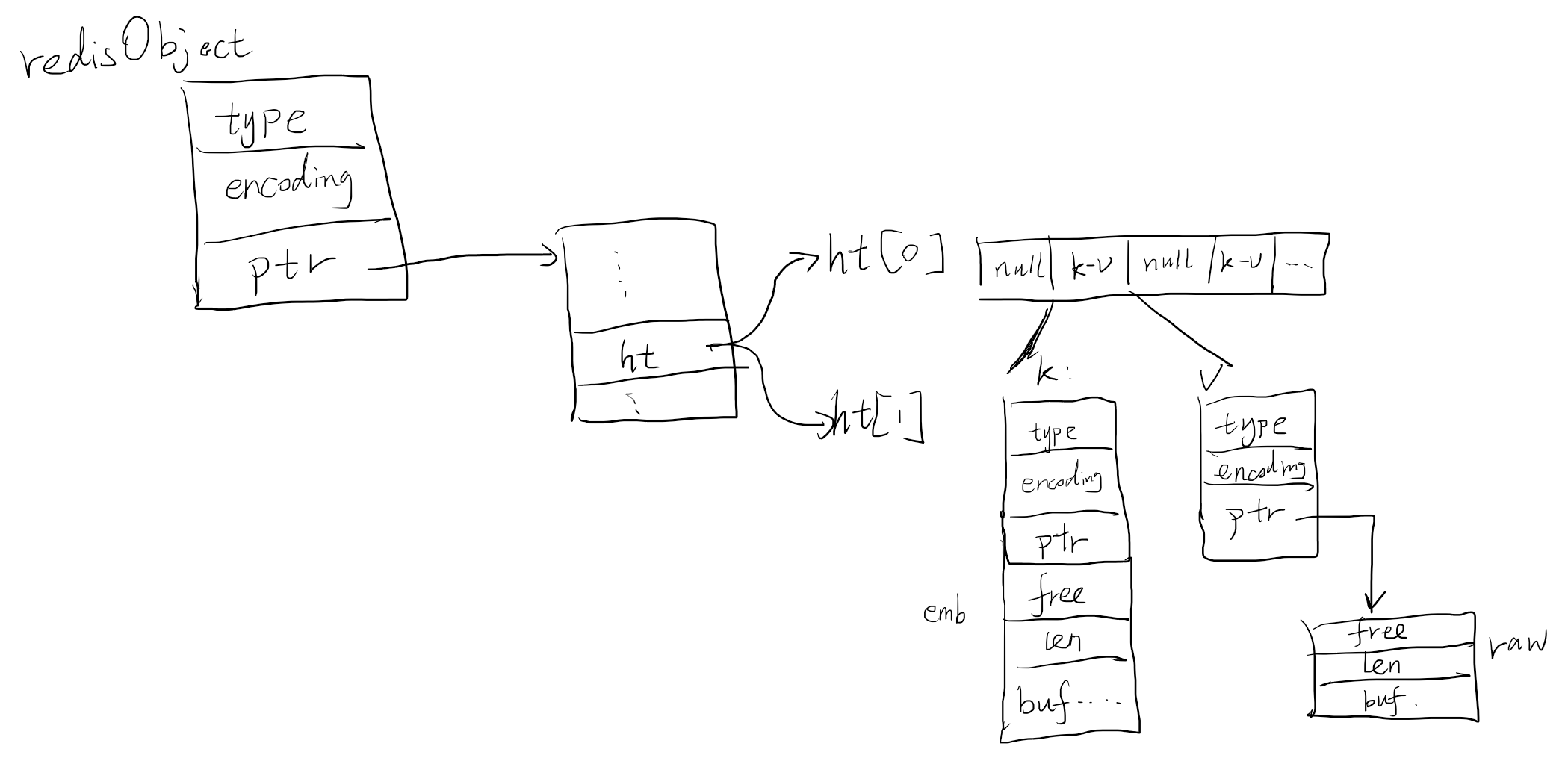
每个元素都有个redisObject来存储,该结构体主要有三个属性:type是哪种类型(上面五种之一),encoding是哪种编码,void* ptr一个指向底层存储的指针。(还有个记录引用计数的refcount和lru相关的这里不太重要不说了)
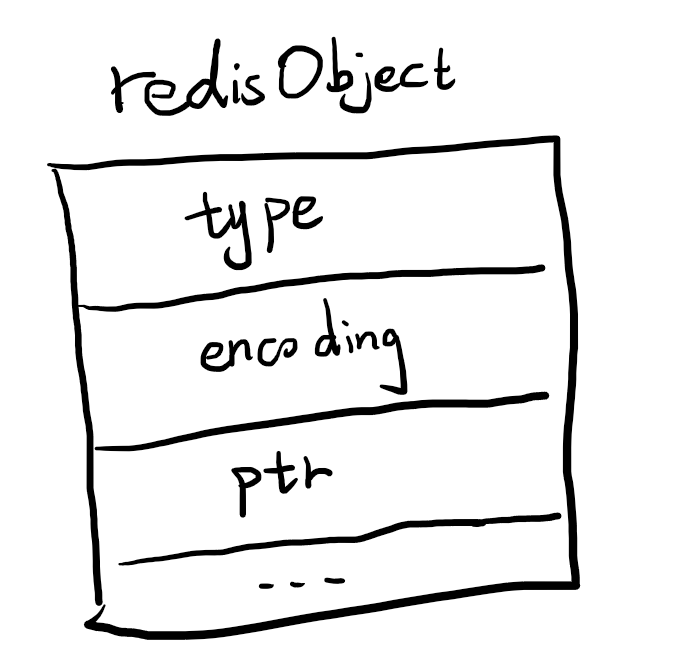
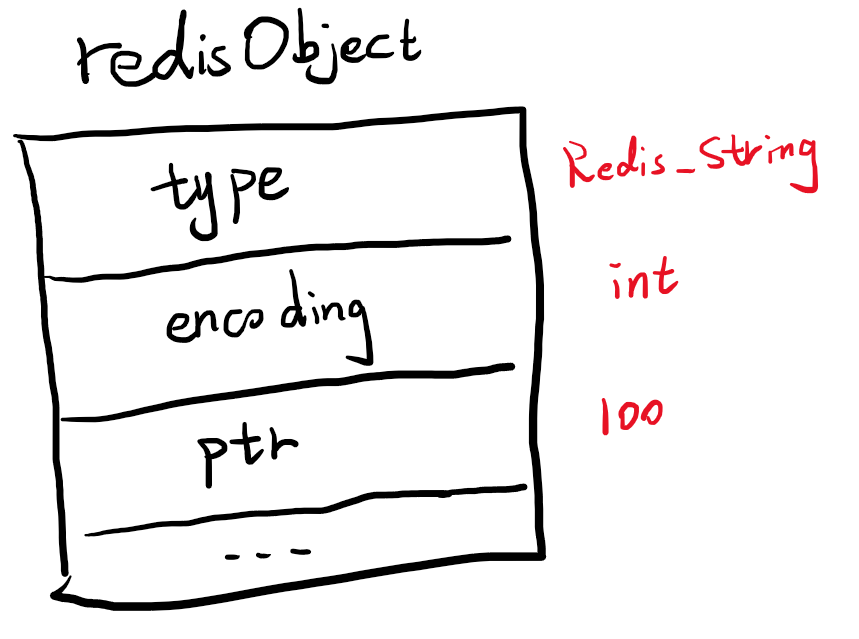
int就是一个整数,在redis底层使用一个long类型来存储,如果是int编码,会将ptr直接作为这个long来存储。这样不需要额外申请内存了。例如set n 100就会用int进行编码,其object结构如下。
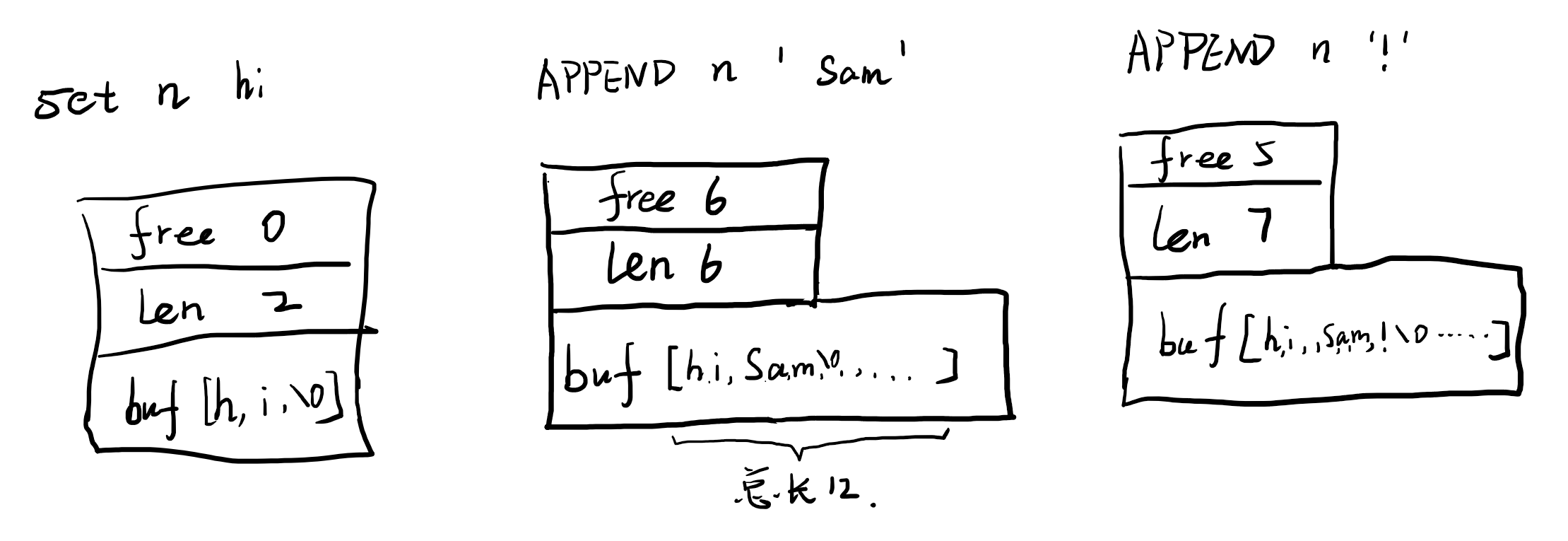
embstr和raw都是采用了sds也就是简单动态字符串作为存储结构,只不过前者是直接在redisObject后面的连续内存创建,而后者则是堆上单独创建。sds是redis自己封的字符串,而没有用cstring,主要是因为c中string是char[]实现的,并且约定\0是结束符,字符串长度需要遍历找到第一个\0,所以redis做了简单的封装,将char[]作为一个成员变量,同时封装了len和free来记录这个数组中前len为有效字符串,后free为空闲的部分。
当初始化的时候,sds中char数组分配长度就是字符串长度+1,即free为0。但是当修改字符串的时候,则会分配2倍的字符串长度的数组长度,即此时free=len,这样如果下次需要对字符串进行追加操作,可以直接使用当前数组而不需要额外开辟空间,提高了效率。
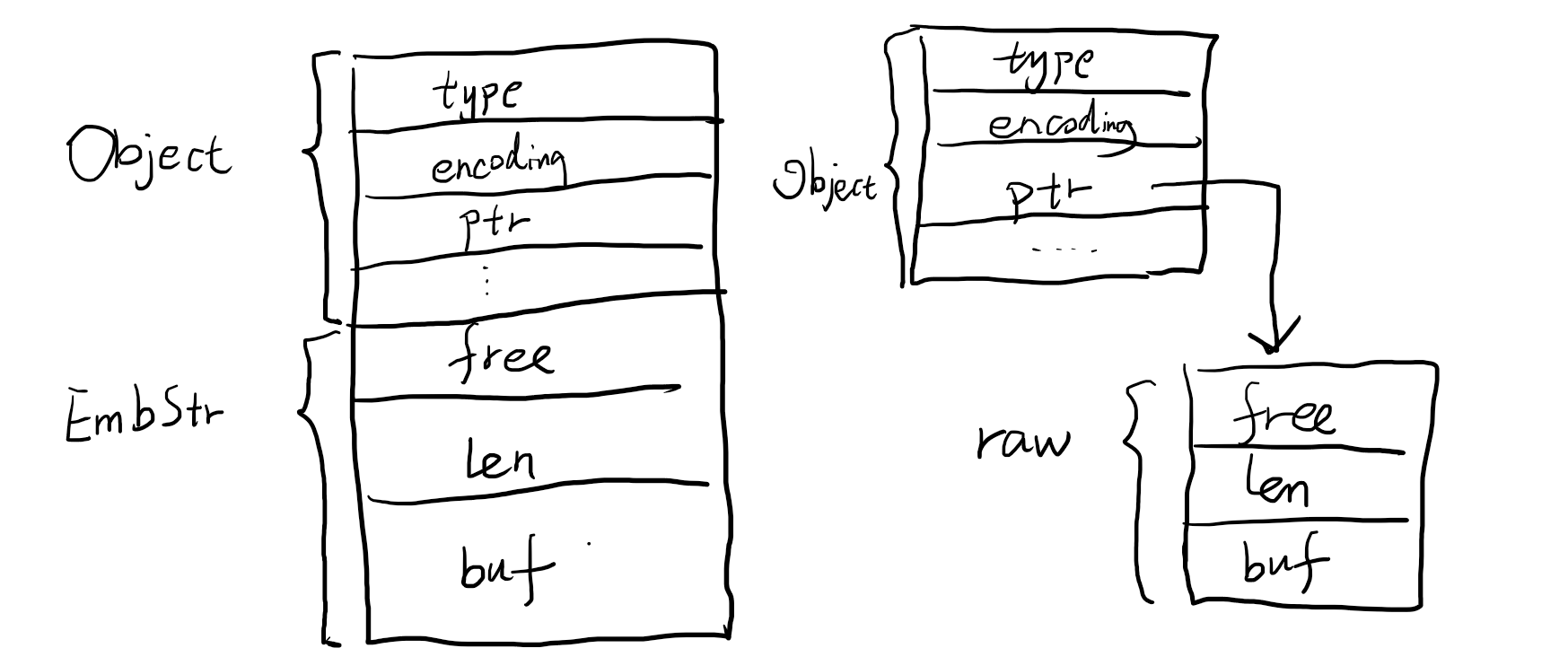
embstr是直接在object后面连续开辟sds空间,这样效率较高,为什么是39呢,因为39个字节加上redisObject和sds其他字段合起来正好是64字节,即embstr默认就会给64个字节,如果超过了,那就去单独申请,用指针的方式指过去,即raw的方式。下面是embstr和raw的区别。
3 Hash
hashtable这种编码和java的HashMap很像,都是数组+链表的结构。区别是hashtable没有红黑树,负载达到1的时候才进行扩容,0.1的时候会进行缩容。另外有个很大的区别是关于扩容的过程,hashtable有个根节点来记录一些元数据信息,即redisObject.ptr是指向根节点,根节点中有个ht[],该数组长度为2,ht[0]是正在提供服务的哈希表,ht[1]是扩容的时候会用的,在查询的时候需要分别查ht[0]和ht[1],因为扩容的时候可能位于任意一边。
那有人就会有疑问,不是说redis是单线程么,那应该是rehash的过程开始后,就无法进行其他操作,然后rehash完成后才会继续读取,那不应该是数据在读取的时候只可能在ht[0]吗。其实考虑到rehash的过程可能较为长,redis采用了渐进式的rehash,也即是将rehash的过程分为了很多步,每次调度一步,然后再执行主线程,然后再调度下一步,直到最终扩容完成。
hashTable的k和v一般是redisStringObject,StringObject也是唯一一种会被嵌套的redisObject。下图是一种可能的内存结构情况。
而ziplist需要拿出来说一下,其结构如下。
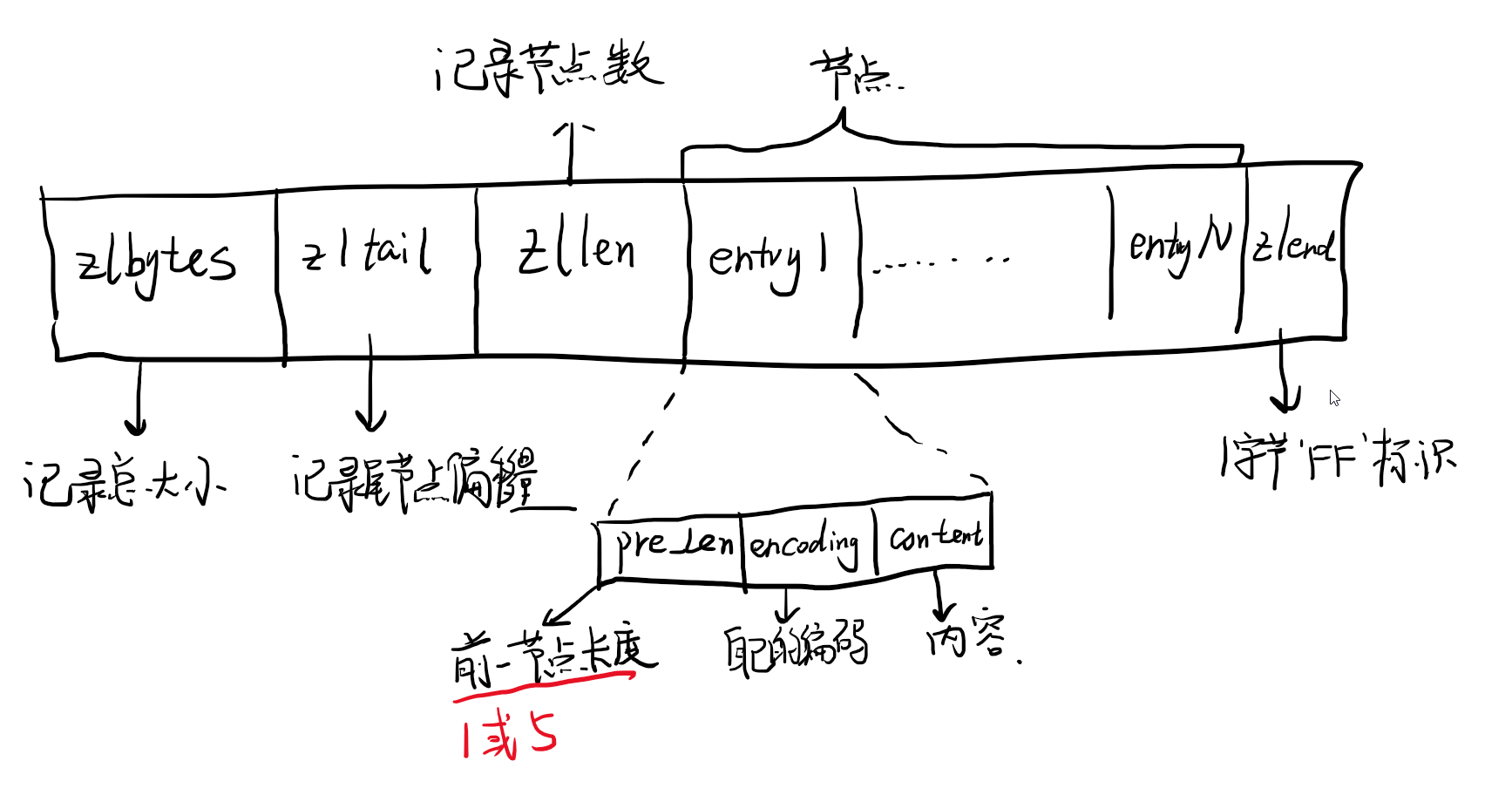
这是一个紧凑结构,对数据进行了压缩,有个需要注意的是前一节点长度是1或5,当前一个节点254字节以内的时候就用1个字节表示其长度,否则用5个字节。这个设计配合上面提到的64字节以内的才会采用ziplist,64字节的时候len都是1字节就能表示的,内存使用率就比较高。当然ziplist作为一种底层数据结构,在redis很多内部场景也会用到,如果出现多个连续的1字节长度,并将第一个元素改为超过255字节后,会引发连锁更新,只不过很少遇到,概率很小。
ziplist如果要存储hash结构,需要每个entry先存k,然后下一个存v,即每个kv的entry是紧邻的。
4 List
上面介绍了ziplist,当元素较少,且每个元素较小的时候,使用ziplist。而其他情况则使用linkedlist,也就是链表。链表可以便于元素从两端进行存取。
在linkedlist中,每个节点是redisStringObject而不是sds,StringObject也是唯一一种会被嵌套的redisObject。
5 Set
hashtable作为set编码的话,value部分是null,只使用key的部分。
intset整数集合,是redis针对全都是整数的集合设计的一种专门的优化方案。他主要有三个字段组成len记录集合大小,encoding记录使用哪种编码例如i8,i16,i32,i64,contents是个int8数组用来记录数据,并且是个有序的,如果encoding是i32那么就是每4个元素组成一个数。
例如sadd ns 1 3 2创建集合ns,其底层使用intset,encoding是i8,contents数组顺序是[1,2,3]。如果要插入一个新的元素129,那么发现i8编码不够了,需要升级为i16,此时需要对数组进行相应的调整,每2个元素对应一个数,最后数组是[0,1,0,2,0,3,1,2]。另外对于插入到中间的元素需要使用二分查找和插入排序。
5 Zset
有序集合,按理说不算是个集合,因为除了存储元素本身,还需要给元素指定一个分数,这个分数决定了再集合中的顺序。当元素较少的时候,比较过程简单,使用ziplist可以提高内存利用率,ziplist的entry是先存key然后下一个存分数。
zadd zz 1 a 2.1 b 1.2 c
当元素较多时,需要用跳表。我们就来说一下跳表这个数据结构。
当我们在有序结构例如有序数组,二叉搜索树中,进行查找的时候借助有序性,有O(logn)的复杂度,而对于插入元素来说线性结构有序数组是O(n)复杂度,并且需要额外内存,但是二叉搜索树仍是O(logn),因而可以看到java中TreeMap这种有序集合使用了红黑树。同样redis也可以使用红黑树来实现Zset,但是红黑树有一些缺点,比如不支持范围查询,而跳表保持相同的空间和时间复杂度的同时,平衡操作非常简单。
上面我们说有序数组的写操作是O(n)复杂度的,且需要开辟新的数组,但是链表就没有这个问题,我们将有序数组,换为双向有序链表,就可以解决插入元素需要开辟新数组的问题。但是有序链表如果用二分查找,我们没法快速索引到第mid位,这需要从root节点运行mid次next。
所以我们可以记录一个mid节点的位置,即可快速找到中间节点了,而到了下一次二分我们可能又需要(0+mid)/2或(mid+end)/2节点,那就分层记录。第1层记录所有节点,第2层是隔一个节点记录一个,第3层是第2层隔一个节点记录一个。效果如下以1-13这个为例,第一层有13个节点,第二层就只有一半也就是7个了,第三层4个,第四层3个,第5层2个,其中头尾节点是每一层必须要有的,最高层就只有头和尾两节点。prev指针只有第1层有,高层不需要。

我们来分析一下复杂度,开始查找先从最高的一层进行比较,看是不是这个范围的,如果不是就null,是的话,再往下一层,比较和9的大小,然后如果比9小就在往下一层和5去比较。整体比较的次数是5次也就是层数,即O(logn),这是时间复杂度,空间复杂度,是多创建的2-5层的节点数,其实是多创建了n个节点,可以用等比数列算出,n + n/2 + n/4 .... 2 = 2n(1-(1/2)^depth) = 2n。
而对于插入元素,其实就是先查找元素的位置,然后在第1层插入该元素,至于第2-x层是否插入,运行一个random函数以50%的概率在第2层插入,然后在第2层插入的前提下,第三层也是50%的概率插入,这样算下来操作的次数数学期望是2次,也就是O(1)的插入复杂度,算上查询O(logn)。
此外需注意,跳表虽然是按照分数进行排序,但是内部节点并没有存储分数,而是只存储了key的值,key-分数的键值对是存到了另外的hashtable中了。是为了能够快速的(O(1))根据key查询他的分值。
既然跳表能很好的支持有序数据的索引查询,并且还支持range查询,那为什么mysql不用跳表而是B+Tree呢。原因是redis是内存数据库,mysql要将数据存储到磁盘上,所以减少跨扇区的查询才是主要矛盾。B+树单个节点存储多条数据,进而减少了tree的高度,减少了跨扇区的磁盘读取,此外数据节点都存放在索引节点中,且作为b+数的叶子节点是连续存储的。
6 Bitmap
底层是用sds也就是字符串实现的,SETBIT mybitmap 10 1例如该指令设置第10个bit为1,会先创建合适长度的字符串,然后把对应的bit设置为1。
bitmap有很多应用场景:
- 实现布隆过滤器(redis官方虽然也有bf的插件)
- 统计在线用户数(每个bit是一个用户id)
7 HyperLogLog
HyperLogLog(简称HLL)是一种基数算法,可以用来对一个数据集的基数进行估算,而不需要对数据集进行完全的遍历或者存储所有的元素。
说人话就是这个也是个类似集合的东西通过PFADD添加元素,PFCOUNT统计非重复元素个数,但是相比于Set,他并不是真正存储所有的元素,而是用了一些算法,存储更少的元素,但是能以很高的精度返回集合的count。所以核心用途是在大数据量级的情况下能够在很小的空间中进行元素去重统计,并且结果不需要完全准确,例如统计UV之类的。