service worker
service worker是浏览器内置的功能,是一个单独运行的线程,他不能操作dom,主要的作用是缓存资源和推送通知。
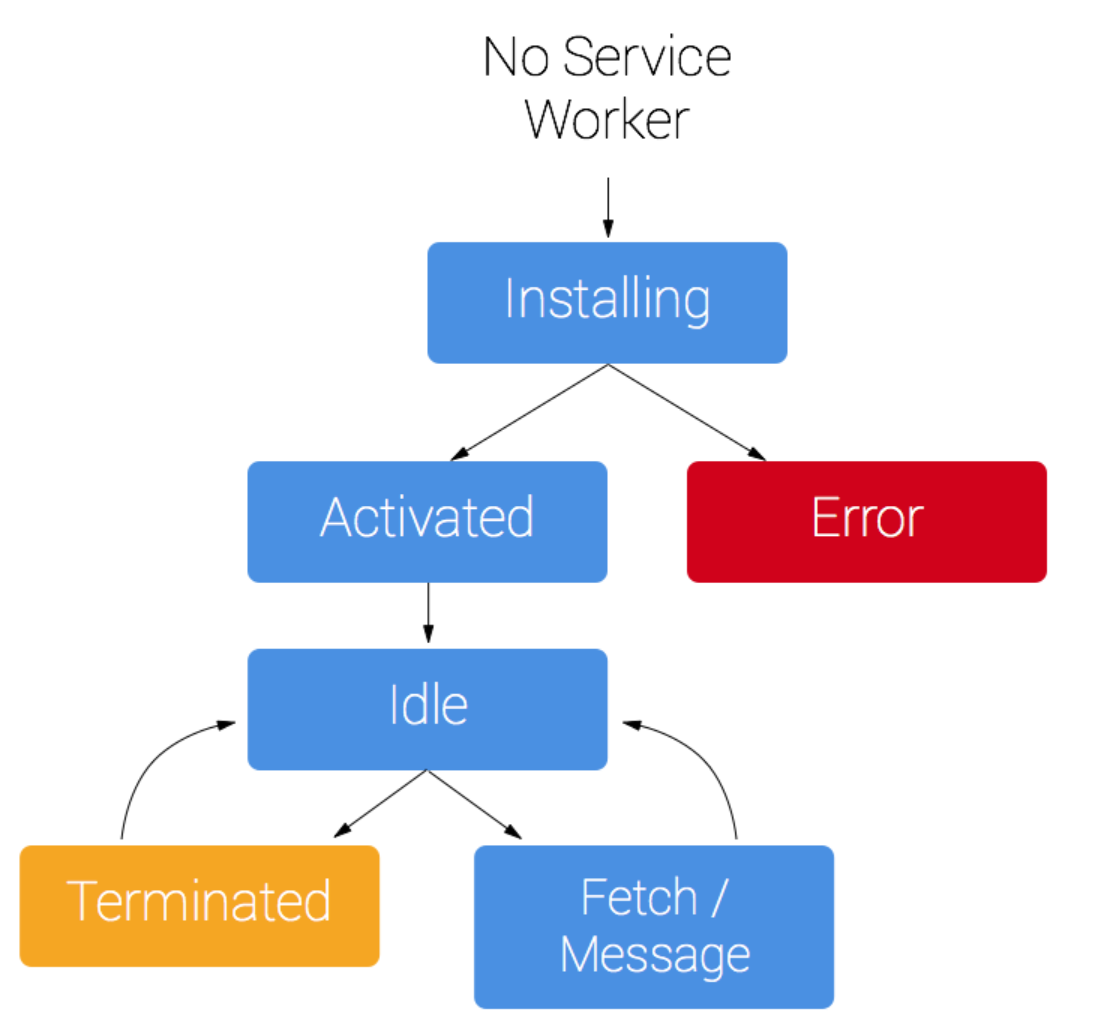
生命周期
service worker创建后与当前页面就没有关系了,而是作用于整个域名+scope范围,一个脚本对应的service worker在整个浏览器中只有一个,他可以作用于多个tab页。下面是生命周期的图。
使用
在主线程中如下,这里展示了三段用法
register方法是将指定的js文件注册为service worker,他会将这个js下载下来并在后台线程运行,register第二个参数可以指定scope范围,默认是当前路径.,scope的作用是当打开其他tab也是这个scope范围内的话,这个service worker也会被激活,此时生效于多个页面。message回调的作用是监听来自service worker的消息,是主线程与worker通信的方式。postMessage方法作用是向worker线程发送数据,注意是深拷贝的,并不是共享内存。
<button id="btn">发送消息</button>
<script>
var t = { id:99 };
// 注册 Service Worker
const registration = await navigator.serviceWorker.register('/23.05/sw/service-worker.js');
console.log('Service worker registered with scope: ', registration.scope);
// 监听从serviceworker线程发送到主线程的message
navigator.serviceWorker.addEventListener('message', function (e) {
console.log('service worker传到主线程的', e.data, e);
console.log(t);
});
// postMessage方法,从主线程发送数据到worker,注意所有的发送数据都是深拷贝,而不是共享内存。避免并发问题
document.getElementById('btn').addEventListener('click', function() {
navigator.serviceWorker.controller.postMessage(t);
});
</script>
然后我们来看service-worker.js怎么写的,主要是以生命周期函数的形式写了四个回调函数:
install在第一次主线程中register的时候触发,如果已经install过了的js,就不会再次触发了activate在第一次激活的时候触发,符合scope的页面第一次打开的时候触发。fetch在主线程调用fetch函数的时候触发,返回值会作为主线程fetch的返回值,所以可以在这里做缓存替换。message和postMessage与主线程中类似,是和主线程通信用的。
// 在worker中如果要使用js文件需要用importScript这种写法 可以是跨域的
importScripts('test.js');
// install事件,在第一次注册的时候会触发
// 这里在install的时候进行了初始化,是将两个资源添加到了cache中
// caches是浏览器内置的缓存对象,addALL会立即请求该资源并进行缓存
self.addEventListener('install', function(event) {
console.log('install事件')
event.waitUntil(
caches.open('v1').then(function(cache) {
return cache.addAll([
'/23.05/sw/index.html',
'/23.05/sw/api.json'
]);
})
);
});
// active事件,在符合scope的页面打开后,就会激活,注意install只有一次,但是激活会有很多个页面激活
// 也可以将一些初始化操作放到active中
self.addEventListener('activate', (event) => {
console.log('activate事件,一般是新打开了页面', event)
});
// fetch事件,拦截fetch方法,当页面调用fetch方法,就会被拦截
// 这里的逻辑是结合install中的缓存设置,来判断fetch的资源是否命中缓存实现加速,否则才真正调用fetch
self.addEventListener('fetch', async (event) => {
console.log("拦截fetch", event);
const res = await caches.match(event.request.url);
if(res) {
return res;
} else {
return fetch(event.request);
}
});
// 接收来自主线程的消息,并往主线程发送消息
self.addEventListener('message', function (e) {
console.log('主线程传到service worker', e.data);
e.data.id ++;
setTimeout(()=>{
e.source.postMessage(e.data)
}, 5000)
});
消息的深拷贝
上面例子中我们传递一个对象,并在worker线程中进行了id+1的操作,然后返回打印的日志如下。可以看出确实返回的数据是100了,但是打印t之后发现还是99,说明数据是深拷贝,而不是共享内存。

service worker是scope共享的
service worker是一个线程,对于一个js文件是一个单独的线程,多个tab加载的sw的js文件相同不会重复安装,所以只有一个线程。
当我们打开了两个页面的时候,他们是共用一个service worker的,当我们在一个页面中向sw发送消息,sw收到后调用console.log实际上是委托给所有符合条件的tab都进行打印的。而e.source.postMessage的source只是针对发送消息过来的页面,所以有下面现象:
我们在一个页面中发送了消息,另一个页面也打印了接收到了消息。但是返回的消息只有发送的这个页面有打印出来。
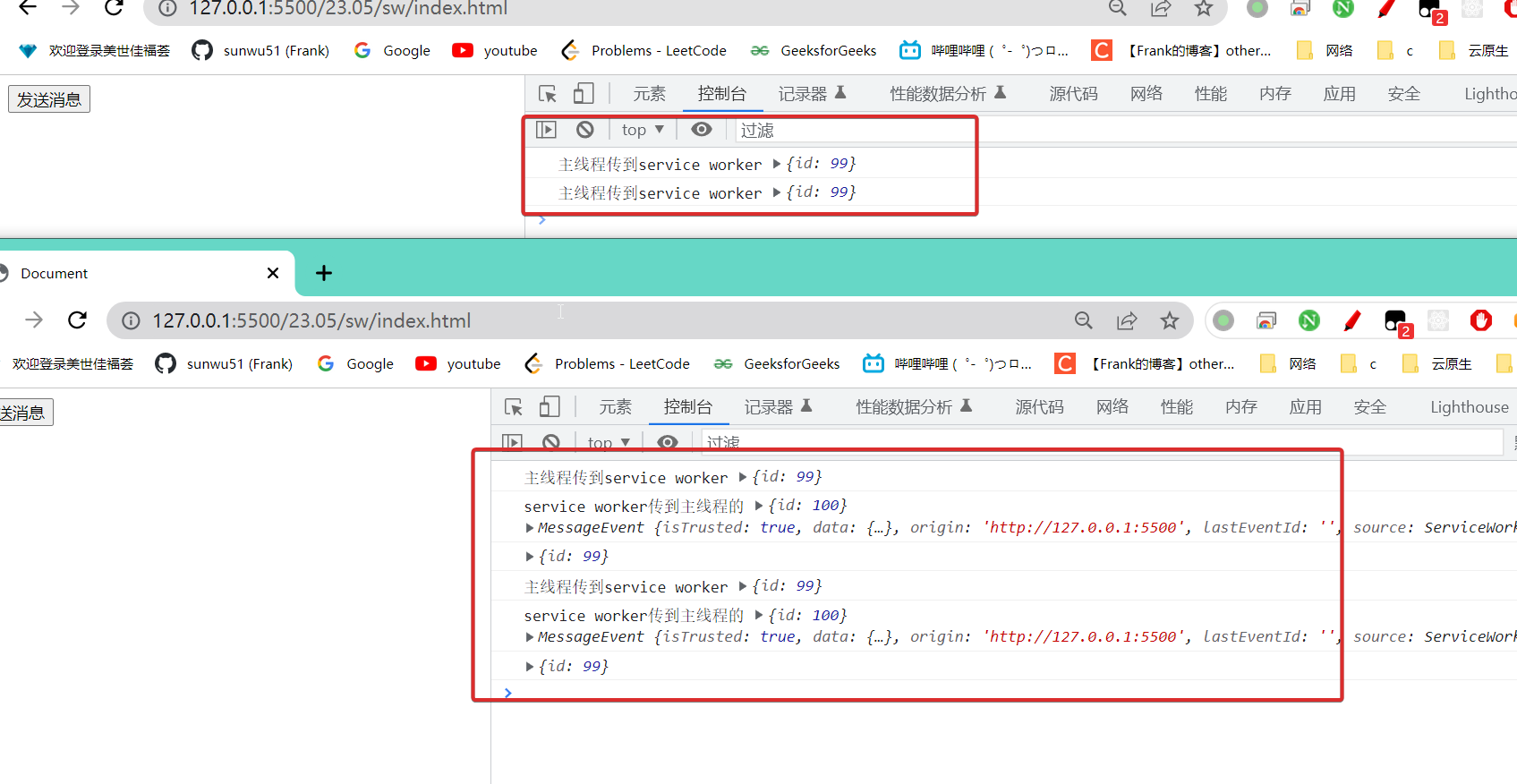
所以我们得慎用console.log方法,因为会在所有的tab中都打印消息。
因为这种共享的机制,也就使得sw是不能也不应该操作dom元素的,因为会有多个页面都用一个sw,操作哪个dom呢?
缓存
目前sw主要作用还是缓存资源,众所周知浏览器对于http资源本来也是可以进行缓存的,这和手动的sw进行缓存的区别是什么呢。浏览器network缓存主要受控于资源的response header: Cache-Control 中。
框架
原生的sw用法如上,其实本质上并不是只用于缓存,也可以用一个scope一个线程的额外线程来做一些事情,在sw中也是可以调用fetch这种函数的,当然也可以自由的进行数学运算,例如加密等。只不过后面这些web worker好像更合适。
对于单纯的缓存来说google有个workbox框架底层用的sw,因为sw没有对缓存有策略的设置,都需要自己写代码处理,所以workbox是sw的一个简单封装,但是更好用了,此外sw需要加载单独的js文件来注册,workbox就不需要了,像webpack有专门的workbox插件,而对于vite也有专门的sw的cache插件,用到的时候可以再去研究。