kafka常见面试题
1 kafka节点是pull还是push
pull,pull的时候consumer可以根据自己的能力按需拉取,如果是push可能导致大量数据推过来,但没有能力消费,打挂consumer。但是pull轮巡也会导致资源的浪费,所以有个配置是尝试pull一段时间,如果没数据就一直等待。
2 kafka如何保证消息不丢失
这个问题从三个重要的角色来阐述:
- producer端:
- ACKS=ALL【保证每个ISR中的节点都写入完成了,才确认】。
- retries>1 【多次重试】。
- broker端:
- replica-factor>=3 【保证每个分区的备份】
- min.insync.replica>1 【至少有这么多个replica写入完成,broker才认为消息已经写入完成
- unclear.leader.election.enable=false【ISR之外的不能竞选leader】
- consumer端:
- 要先消费消息再手动提交offset的方式
3 kafka如何保证消息不重复
消息不重复,要从consumer和producer分别讨论。
- consumer:
- 接上文不丢失的设置,需要消费后提交offset,但是仍旧存在已经消费了,但是机器挂了没能提交上offset的情况。其实没办法避免,只能在业务上进行一些限制,比如保证消息处理的幂等性,如通过db主键来保证,或者kafka是支持同一个集群下消费和发送消息放到同一个事物来保证的。
- producer:
- 开启幂等性,可以保证消息发送的不重复,原理是在msg中加了一些隐藏字段,ProduceId+Epoch(epoch是producer启动时间)。下维护一个自增的seq,如果seq重复就丢弃数据,如果比预期的seq还要大则抛出乱序异常(有个乱序的阈值可以设置)。但是还是不能保证绝对的幂等,尤其是收到ACK前就重启的情况,新启动会发现记录的消息中这一条是没有发送的,新启动会有新的pid这样seq就与原来不是同一个了,而且有可能吧msg发到其他分区了。
幂等只能保证单会话,单partition幂等。 - 开启事务,幂等不能只能保证单消息不重复,无法保证原子性,如果是多个分区或者多个topic就需要事务来保证原子操作。
- 开启幂等性,可以保证消息发送的不重复,原理是在msg中加了一些隐藏字段,ProduceId+Epoch(epoch是producer启动时间)。下维护一个自增的seq,如果seq重复就丢弃数据,如果比预期的seq还要大则抛出乱序异常(有个乱序的阈值可以设置)。但是还是不能保证绝对的幂等,尤其是收到ACK前就重启的情况,新启动会发现记录的消息中这一条是没有发送的,新启动会有新的pid这样seq就与原来不是同一个了,而且有可能吧msg发到其他分区了。
4 AR ISR HW LEO LSO
- AR:分区的所有的副本
- ISR:已经达成一定同步的副本,可作为leader的候选
- LEO:leader节点将要写入的offset
- HW:所有ISR节点都达到的最高的水位
- LSO:最小的未提交事务的msg offset
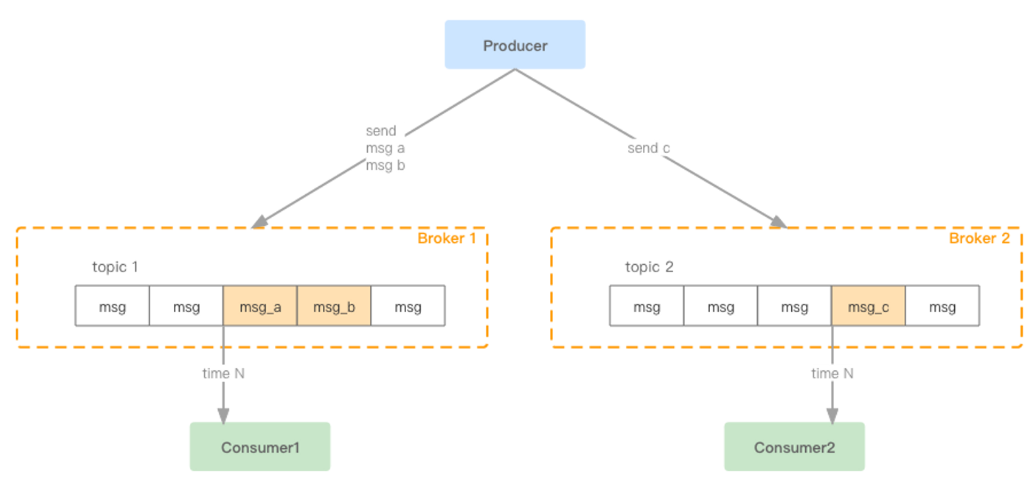
5 kafka数据读写过程
Kafka的数据读写过程如下:
- 生产者将消息发送到Kafka的一个Topic中,该Topic包含了一个或多个分区,每个分区包含了若干个Segment。
- Kafka通过日志的方式存储消息,每个分区维护了一个指针(offset),指向Segment中下一个待写入的位置。
- 消费者通过订阅Topic中的一个或多个分区来消费消息。消费者维护一个指针(offset),指向自己已经消费的消息的下一个位置。
- 消费者向Kafka发送拉取消息的请求,Kafka返回可用的消息,消费者消费完消息后将其提交。
- Kafka会维护一个High Water Mark(HWM),表示已经被所有ISR(in-sync replica)副本写入的最高的消息位置。当消费者提交了一个offset后,Kafka会将该offset与HWM进行比较,如果offset小于HWM,则认为该消息已经被消费,否则认为该消息还未被消费。
- 当Kafka的ISR列表发生变化(副本加入/退出),或分区的leader发生变化时,会发生数据重平衡(rebalance)。Kafka会将分区重新分配给不同的消费者,确保每个消费者消费的分区数大致相同。
- 当Kafka的ISR列表中的副本数量不足时,Kafka会将该分区的ISR列表中的所有副本都视为不可用,等待副本恢复或重新分配分区。
6 kafka事务的原理
事务中需要acks必须设置为ALL,事务是producer端开启的,而不是consumer,后者只管正常消费。
事务过程可能如下,对多个topic分别写了一些数据,需要保证3条消息写入的原子性。
事务执行时,需要先选出一个broker作为协调器,并像协调器发送自己的pid(生产者id)和epoch,这两个标识了这一次事务,后续所有的消息需要带这俩参数;然后会在__transaction_state 这个topic记录一些kv信息,k就是transactionId,v就是这个事务的一些元数据信息,注意trx_id是在producer中手动配置的,当下一次启动的时候还会继续用原来的trx_id。
下面说一下正常的msg的格式有v0v1v2三个版本,v0就是基础的消息的key value 校验 offset等,v1增加了Timestamp,v2则是大变样改成了RecordBatch形式了,也就是一个消息体内部可以放多条records了,当然不同事务的records是不能放到一个batch的。
事务开始后,就需要发送消息阶段了,协调器期间作用是维护__transaction_state中的数据,例如涉及到的topic和对应的partition列表分别有哪些等。broker收到发送的消息,需要维护一个LSO,类似mysql mvcc的min_trx_id,LSO记录的是最小的没提交的消息的offset。RC隔离级别下consumer不应该读取到LSO之后的数据(即使有些可能已经提交了,但为了更高的性能还是不允许读取)。consumer如果是RC级别的就会从LSO前面拉取消息,而不是HW拉取消息了。(HW是能被消费的消息高水位,指ISR中都达到这个水位了,即使leader挂了,ISR中任意节点都可以顶替上来)
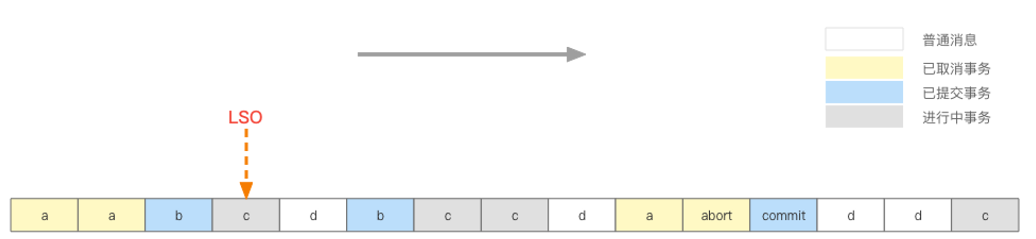
最后提交阶段,根据元数据中涉及到的partition去发送control mark消息,这个消息标识了当前事务的结束。这个阶段的流程是协调器收到commit指令,把元数据改为prepare,然后给producer返回提交成功,最后才发送控制消息,收到ack后改为commited。至于为啥不是先发控制,应该是性能考虑。至于发送给一个partition的写入成功了,另一个marker消息网络抖动没写入,但会一直重试,在这段时间内最后是前一个能被RC读到,后一个并不能读到,但是毕竟CAP不可兼得,弱一致性换高可用性。
事务如果是abort过程类似,只是控制消息记录的是abort状态,还有个特殊的就是超时abort,协调器内有个定时器,定时扫描超时任务。
7 消息语意
- At Least Once: 默认消费类型,消费了就标识一下,业务方自己做好去重。
- At Most Once:先提交offset再处理,重启后从最新的offset开始,最多就消费一次。
- Exactly Once:精确一次,但是是有局限的,kafka实现了以下场景:
- 1 幂等性保证producer单会话单分区消息的投递精准一次;
- 2 事务保证跨多分区的写入是原子的;
- 3 stream任务(从一个topic消费map到另一个topic)使用read-process-write写法,确保精准一次(由producer对象,来提交consumer的offset)。