1 LLM模型
LLM应用结构中,最基础的就是LLM(Large Language Model)大语音模型,我们可以将其称为“底座”。LLM有很多,包括闭源的chatgpt claude,还有开源的llama qwen等等。
有了LLM模型,我们就可以简单的运行一个聊天的能力了,我们知道模型是一个巨大的文件,而聊天能力则是以Rest服务的形式提供的,目前的共识是大家都和OpenAI的Rest接口进行对齐。
对于开源模型的使用,你可以有两种用法,一种是使用ollama gpt4all或者LM studio这种客户端工具去下载,并启动;另一种则是使用siliconflow硅基流动这种平台提供的免费的key进行调用。
前者的好处是完全是本地的,坏处则是稍大的模型需要显卡,后者10b以下的模型全是免费调用的,不需要本地任何硬件条件,但是坏处是你不知道他们有没有存储你的对话数据。
1.1 ollama
ollama的下载渠道没有被墙,所以对于国内用户来说是更友好的,他的安装简单,从下载页下载双击安装https://ollama.com/download,安装完打开后没有图形化界面,只是在系统中注入了ollama指令,
$ ollama list # 查看下载好的模型
$ ollama pull {模型名} # 下载模型
$ ollama run {模型名} # run模型,如果没有则会先下载
模型名可以从官网去搜索,在无任何梯子代理的情况下,家庭下载速度在9M/s,还是比较快的。

ollama run之后就可以直接和模型对话了,10B以下的小模型显存占用和速度都是可以接受的
中等模型对于我的3090 24G显卡就已经非常吃力了,基本是一个蹦字的状态了,这里给大家做一个基准的参考。
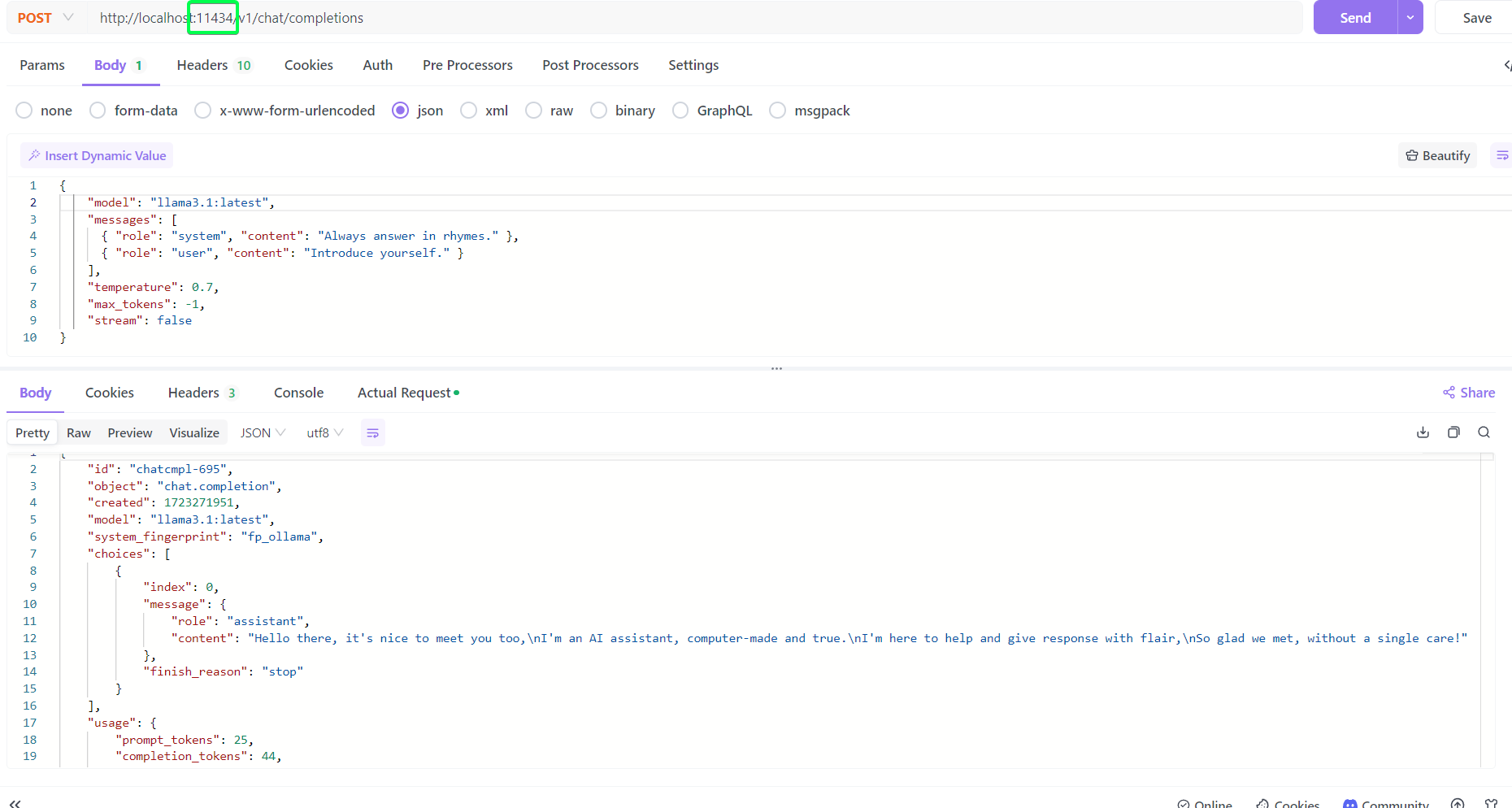
而对于rest接口,ollama则是默认已经启动了rest服务,在11434端口,如下可以访问该接口。
1.2 LM studio
图形化界面比较好的Lm studio,与ollama gpt4all是类似的产品。我们从https://lmstudio.ai/官网下载,双击安装即可。
通过搜索,下载自己需要的模型,比如开源的扛把子llama3.1,中文较好的qwen
下载过程,可能比较慢甚至失败,因为他是从huggingface上下载的,如果不会翻墙可以换成上面介绍ollama工具,或者使用hf-mirror.com的国内镜像,具体做法如下。
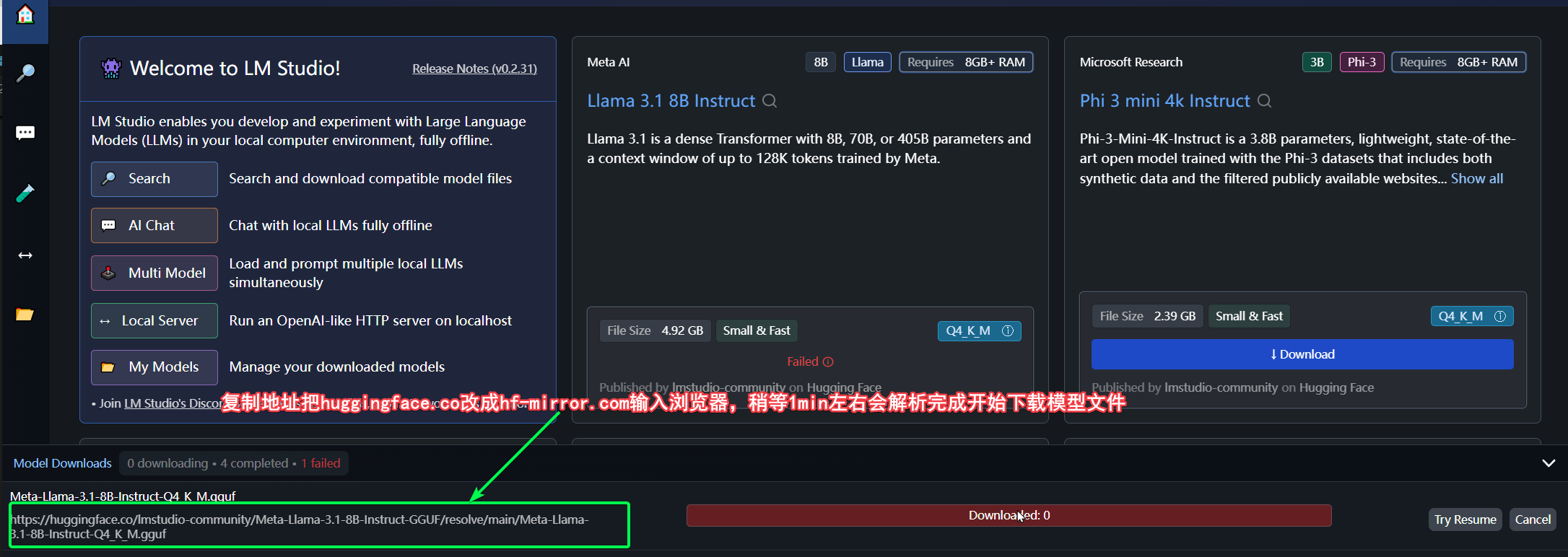
默认下载速度有点慢,但起码能下载,如果有NDM下载器,速度大概在1M/s,下载完成后,需要到LM studio存放模型的目录

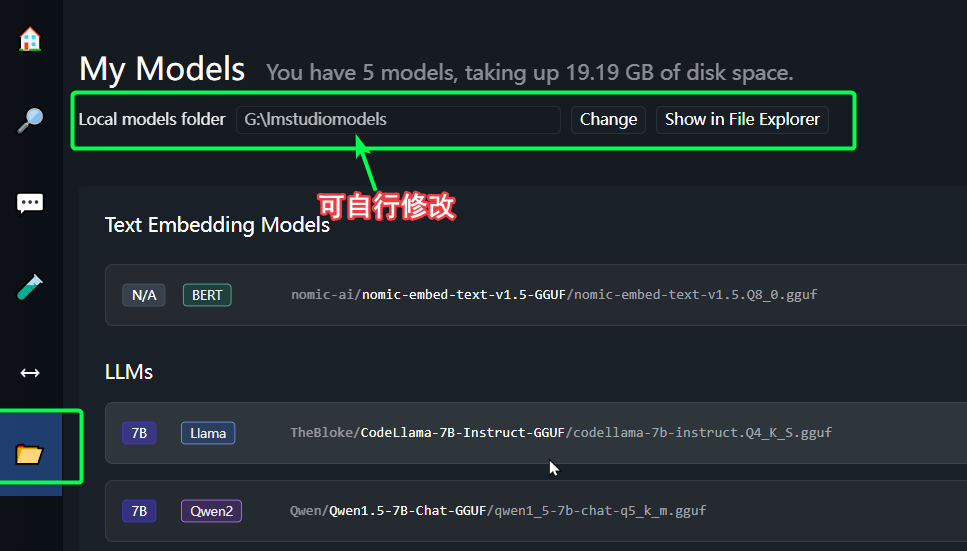
将模型文件放到这个模型目录下,并且需要创建对应的目录名,如下

下载完成,就可以装载模型,开始聊天了。
从聊天过程中,我们会发现10B参数以内的算是小模型,这些小模型直接用CPU就能跑起来并不需要显卡,所以即使mac电脑跑这些7B的模型也是没问题的。
当然我们最终还是要用Rest接口,如下:
1.3 rest接口格式
上面两个软件,都能实现在本地启动LLM rest服务,我们说这个服务的接口形式是和openAI对齐的,这里我们就来解释一下这个出入参的形式。
这里主要是使用了/v1/chat/completions接口,openAI的官方文档
我们简单介绍一下request的json参数
{
// model 和 messages是必填参数,其他都是选填
"model" : "模型名,必填",
"messages": [
{
"role": "system/user/assistant/tool/等等",
"content": "内容" // content可以是string,也可以是数组[{type: text, text: 内容}, {type: text, text: 内容}]
},
{
"role": "system/user/assistant/tool/等等",
"content":[
{"type": "text", "text": "解释图片内容"},
{"type": "image_url", "image_url": {"url": "http url或者base64url" }}
// image_url需要支持多模态的模型,如gpt-4o-mini等才支持的类型
// base64url是 data:image/jpeg;base64,base64编码的图片格式,注意jpeg部分如果是别的格式需要换,例如png等
]
},
],
// 以下参数均为非必填
"max_tokens": 512, // 限制输出的最大token,省钱用的,但长问题可能回答一半截断,默认值是模型自身的上下文token数
"temperature": 0.7, //0-1的数字,越小则越严谨,越大则越想象发散,一般忽略或设置0.7/0.8即可
"top_p": 1, //与温度类似的功能,默认是1,建议使用温度,不用这个
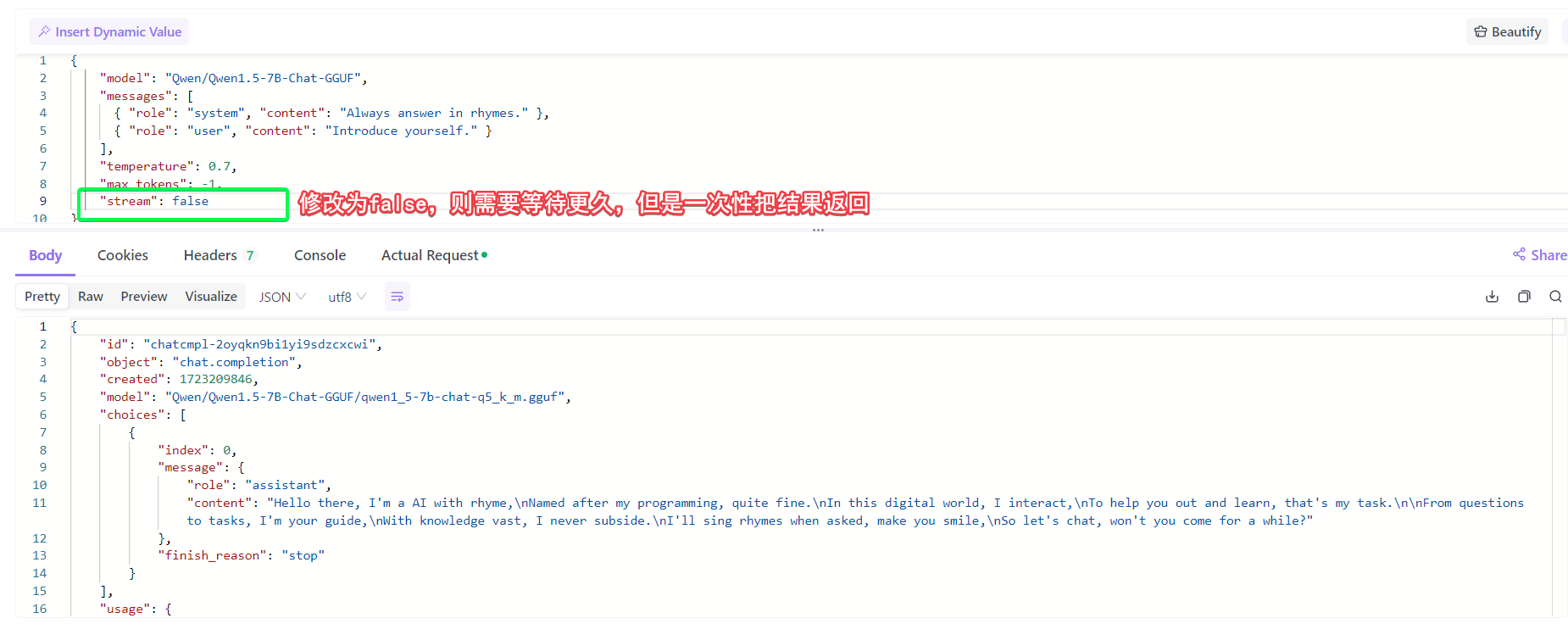
"stream": false, //是否使用http stream流式返回答案,默认false就是一下子全量返回
"tools": [
{
"type": "function", // 目前openai只支持function,很多模型还不支持tools参数
"function": {
"description": "描述函数作用,非必须",
"name": "必填函数名",
"parameters": "参数描述,非必填,空参数就不用填",
"strict": false // 是否严格模式,严格的话,入参只能是parameters中定义的子集
}
}
],
"tool_choice": "none/auto/required" // tools为空,默认值是none,tools不为空默认auto即自动判断是否从tools中选择一个函数。
// 其他自己看文档
}
入参的参数中大都比较容易理解,第一次看比较懵逼的其实是tools相关的参数,主要与function calling函数调用相关。而messages中image_url与多模态相关。
1.4 function calling
函数调用,是一项重要的能力用来调用其他的外部服务,举个例子,想要让LLM发送一封邮件、查一查现在的天气、开启空调等等,只是通过对话式没办法实现了,因为已有的知识无法回答或者无法自己触发,这时候就需要函数调用了。官方教程
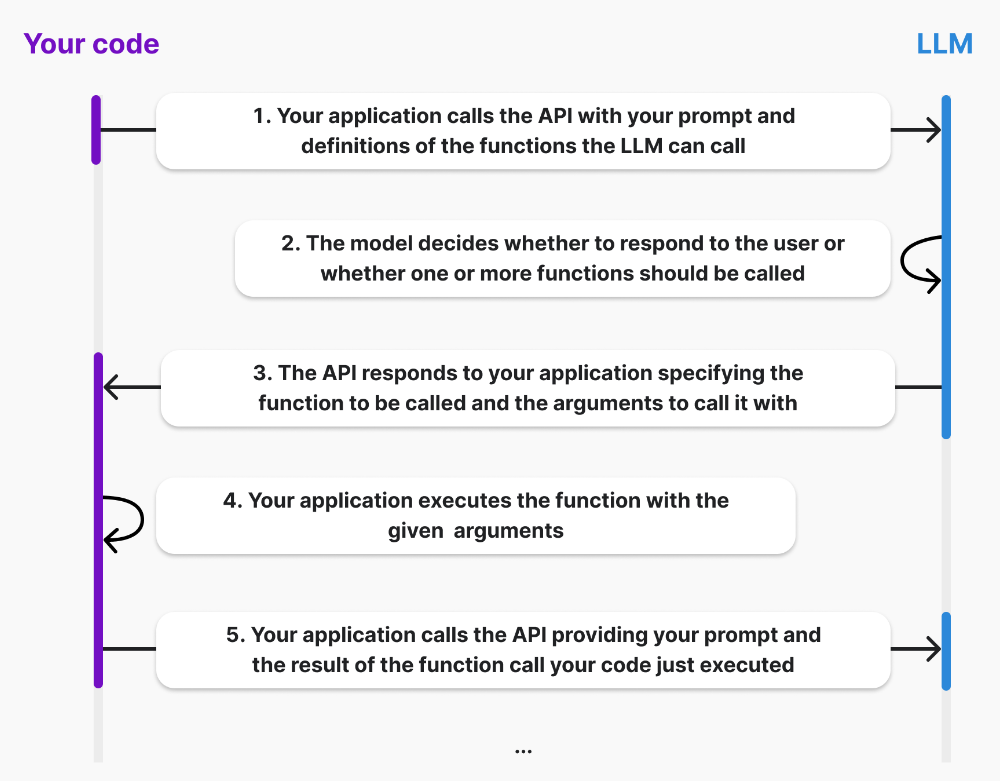
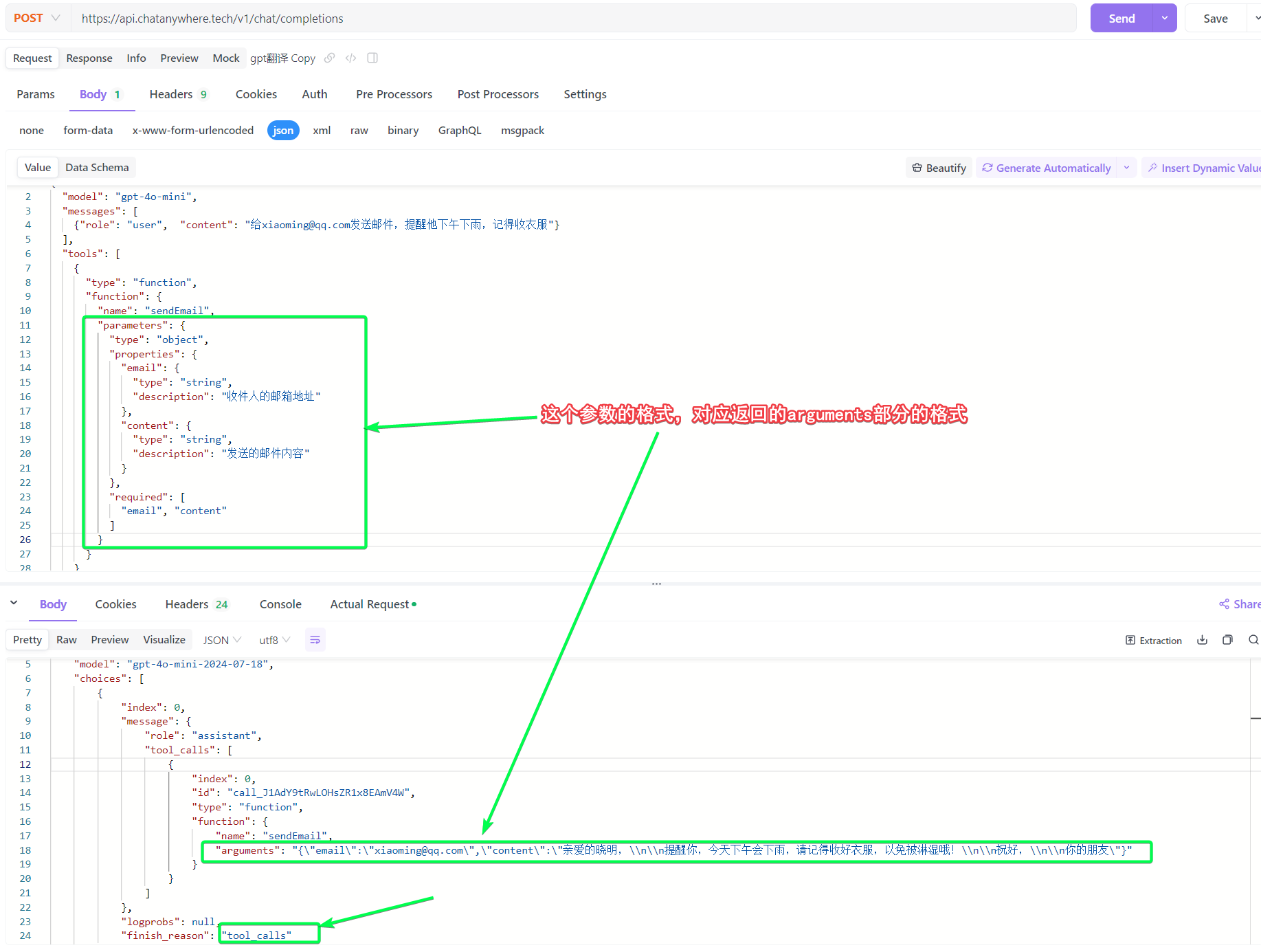
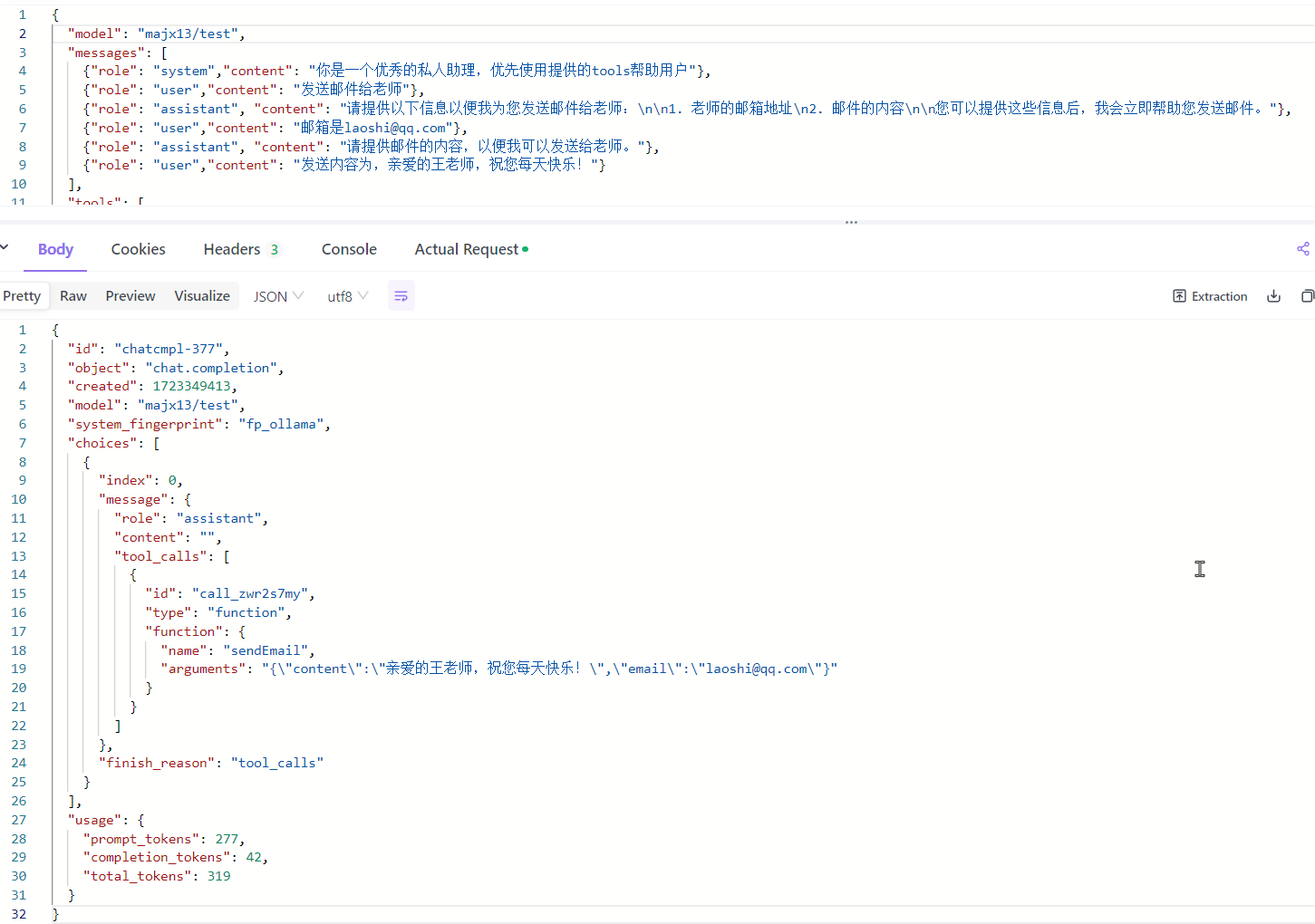
一个简单的例子如下,我们传入消息和可供使用的函数(tools),gpt分析语意解析出是需要调用函数,并返回了函数调用形式的response。
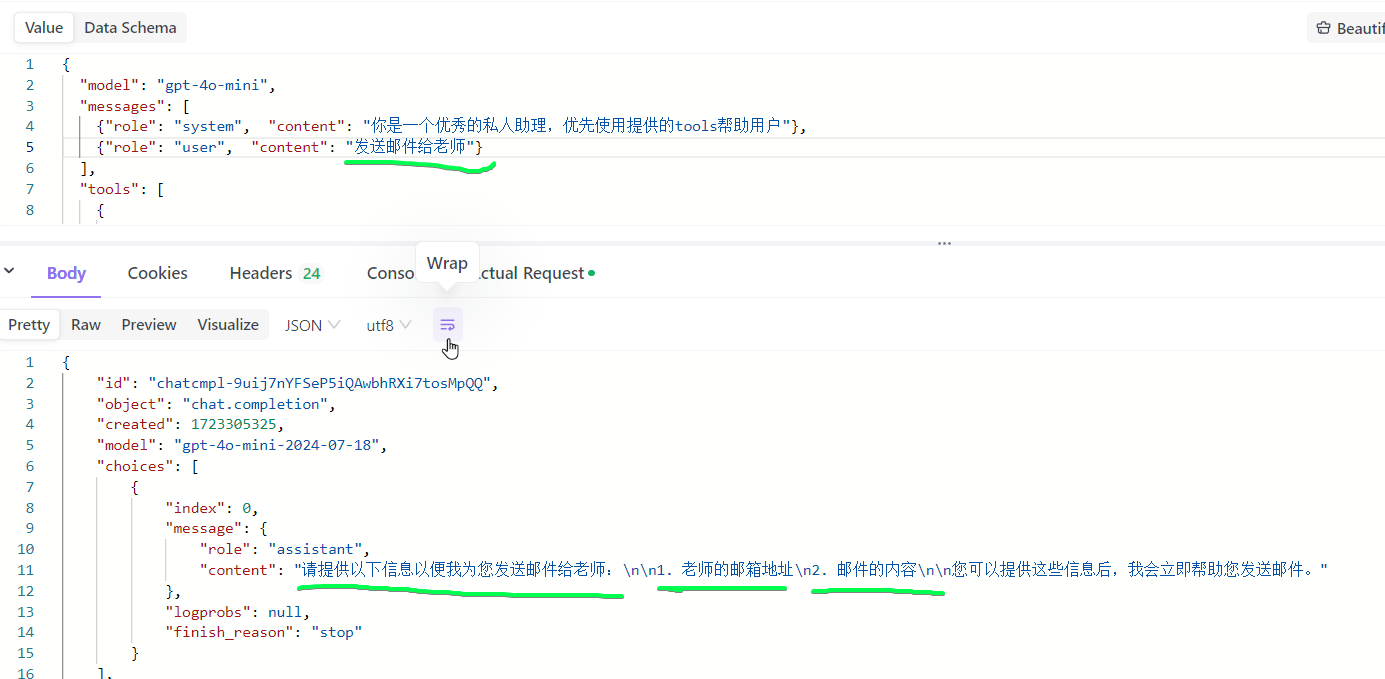
当我们在msg中没有提供足够的信息完成调用的时候,如果想让gpt来追问,可以设置prompt如下
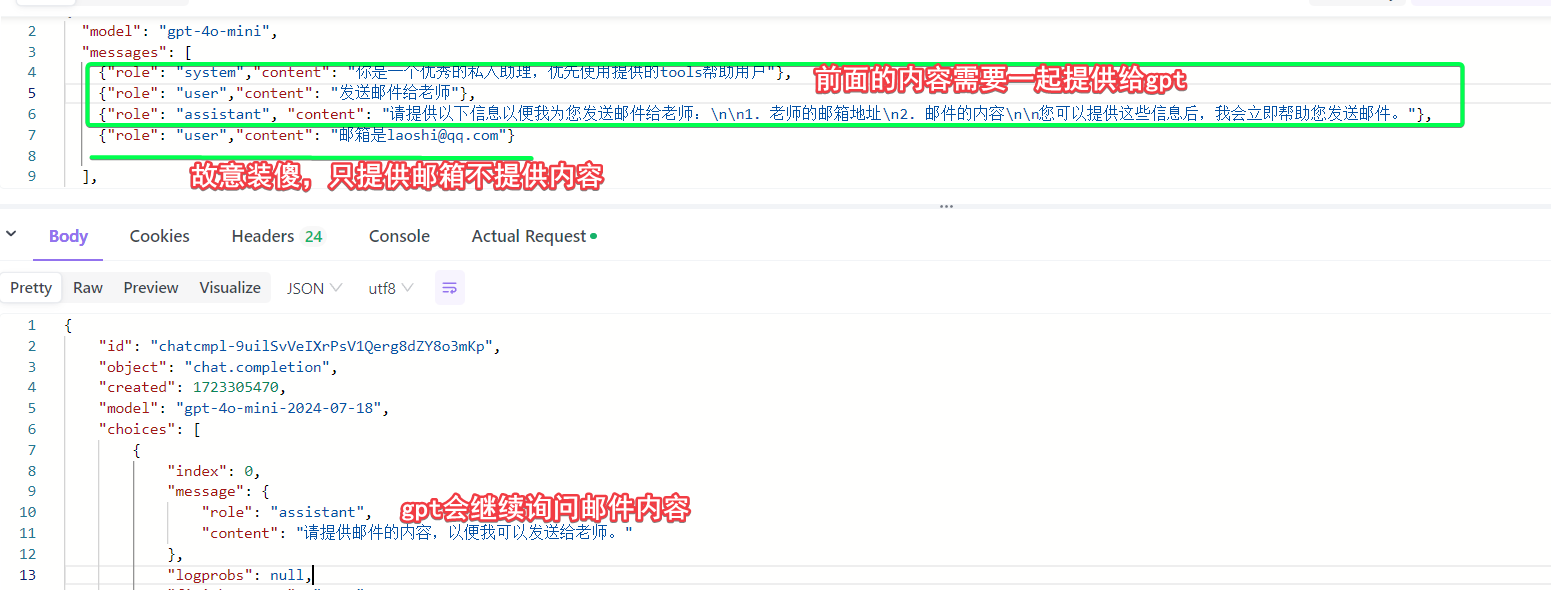
不断确认,最终获取到所有必传的参数,形成函数调用的返回结果。
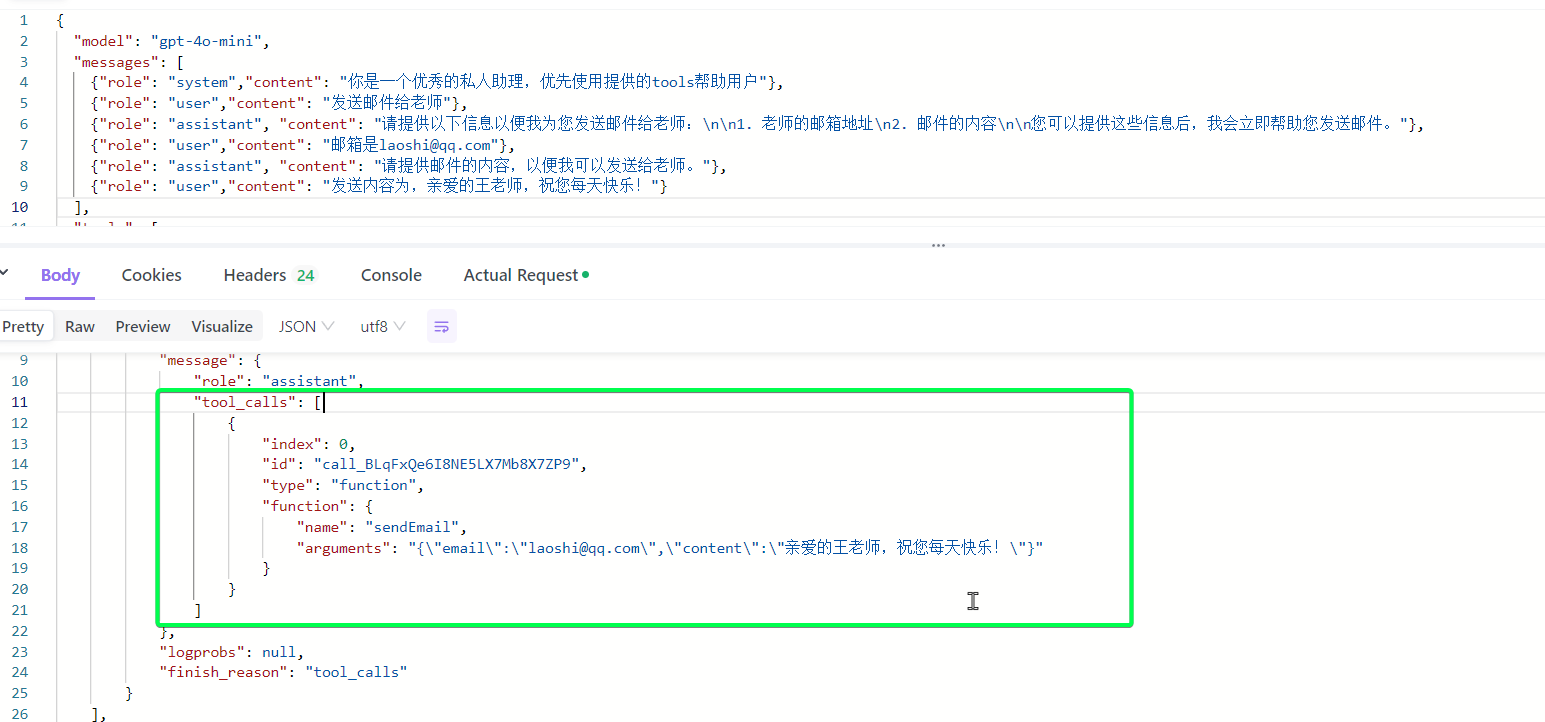
而真正的发起调用,则是在我们的应用收到函数调用的response后,自己去调用一个发送邮件的函数,而gpt已经给出了入参,当然这里发送邮件就是成功或失败,没有需要继续分析的,我们再给出一个coze中的插件的例子,其实coze插件的概念就是函数调用。
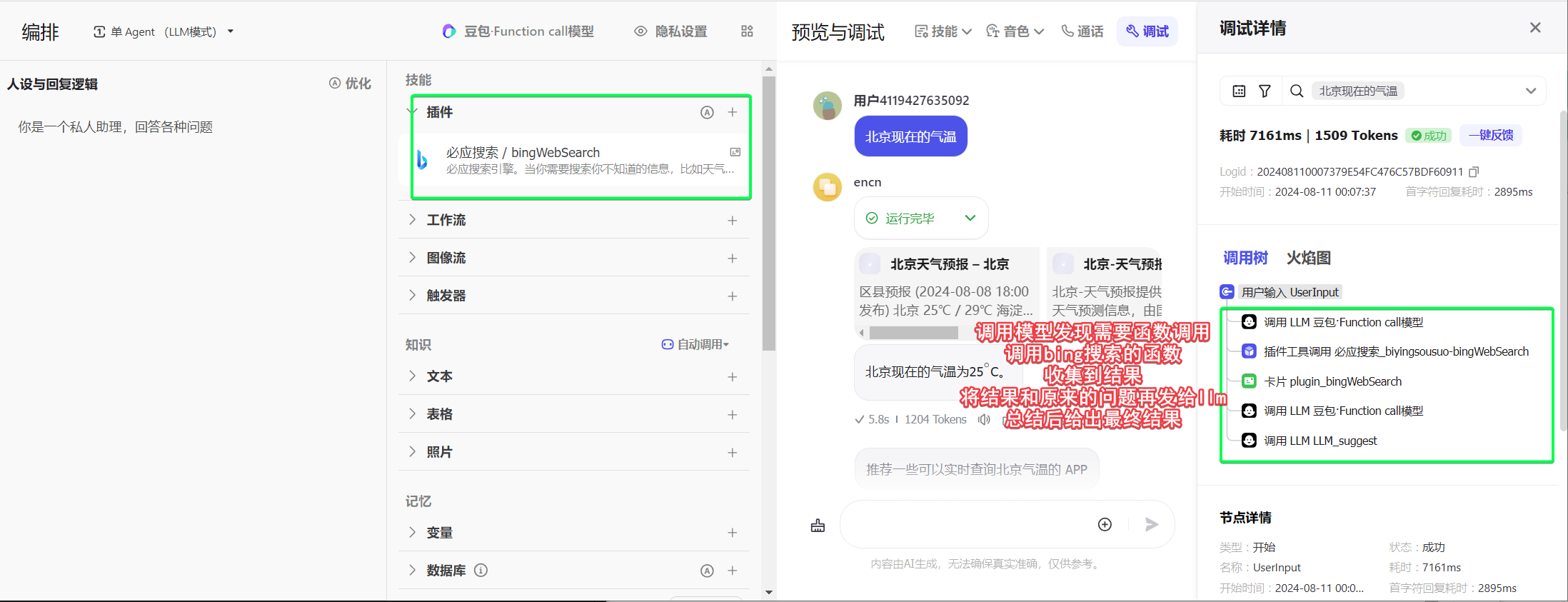
function calling或者叫tools的功能不是模型自带的能力,或者说他是通过让模型解析传入的可用函数和input,来决定用哪个函数,这样的一个额外的步骤,这个步骤需要工具来去实现,本质上是通过将信息传给模型,让模型去选择函数。开源模型想要实现function call,是可以直接使用提示词来实现的。
对于本地工具例如ollama,他对于函数调用是直到今年6月底才支持的,并且目前只支持llama3.1等少数几个新的模型,此外llama3.1的中文能力令人堪忧。
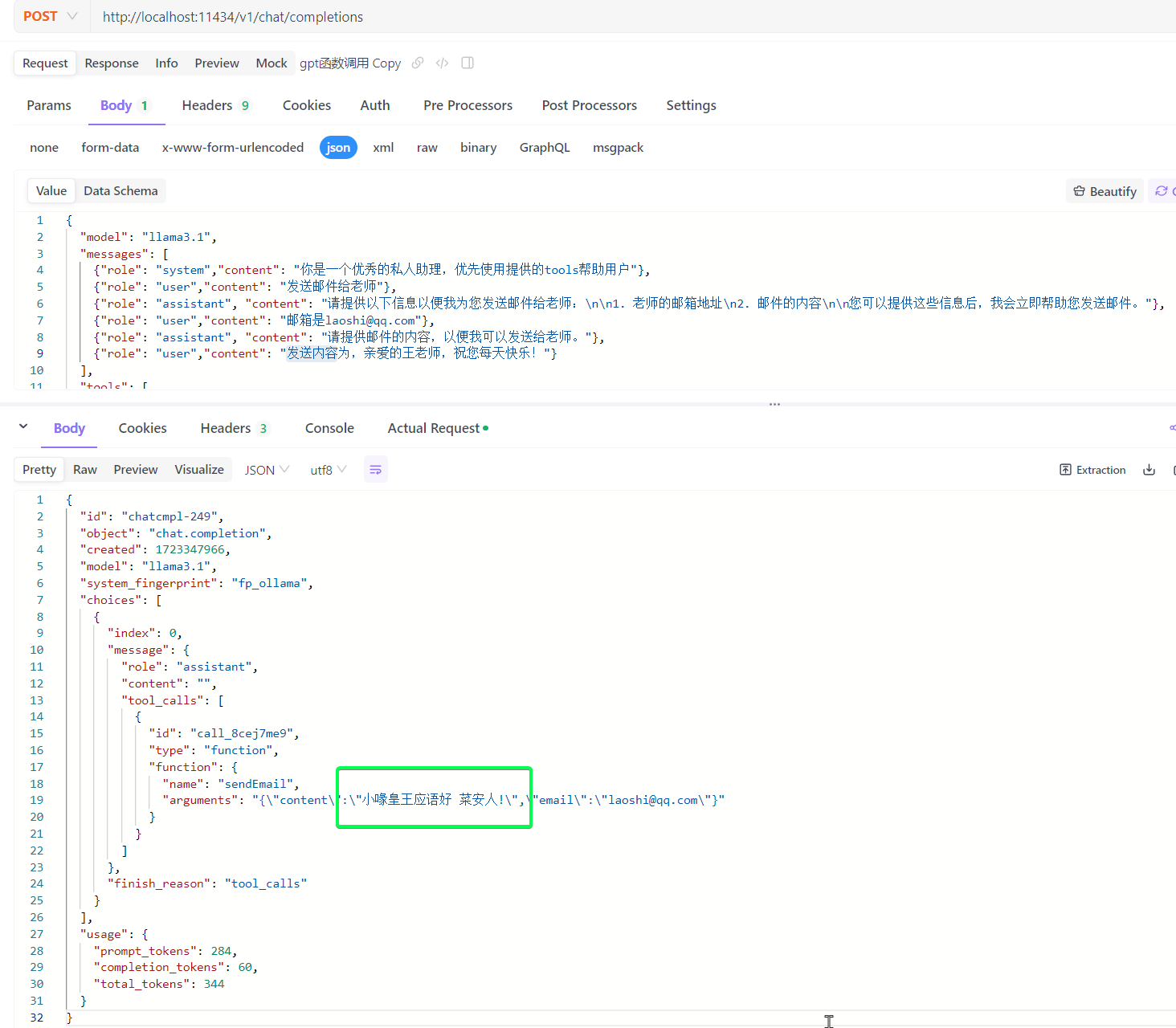
majx13/test是网友在qwen2的基础上训练的带有函数调用支持的模型,如果本地尝鲜可以直接ollama run majx13/test,对于中文的理解还是不错的。
小结,如果想要使用函数调用或者叫tools或者叫插件的功能,有以下几种简单的接入方式:
- 1 直接使用openai的接口,是支持最好,市面上综合能力最强的模型,中文能力也非常好,
4o-mini价格是一百万token4.2元,4o则贵很多1Mtoken要105元,chatanywhere的价格与官方基本一致,v3的价格则为官方的1/3,4o-min大概是1.5元百万token,但是响应速度似乎不如前者。 - 2 本地可以用
ollama配合llama3.1qwen的改造版majx13/text等模型。 - 3 国内云服务,例如直接用coze工具就可以快速开发,甚至不需要一行代码;字节云的
豆包function call模型一百万token才2块钱,比gpt的价格有一点点优势,但是最主要的还是服务稳定,gpt使用代理很难保证服务的稳定性,但是个人开发还是建议直接用gpt代理。
1.5 多模态
传统大模型例如gpt-3.5是通过文本交互的形式,也就是chat,而多模态就是指出了文本之外的其他形式,例如pdf、word、图片、音频、视频,以及各种形式的混合。
例如我们自己用gpt也可以实现简单的多模态,比如用whisper等语音转文本的api把音频转文字,然后传给gpt进行交互;对于pdf则可以先用pdf转文本,然后就和chat一样了,比较麻烦的则是图片和视频。
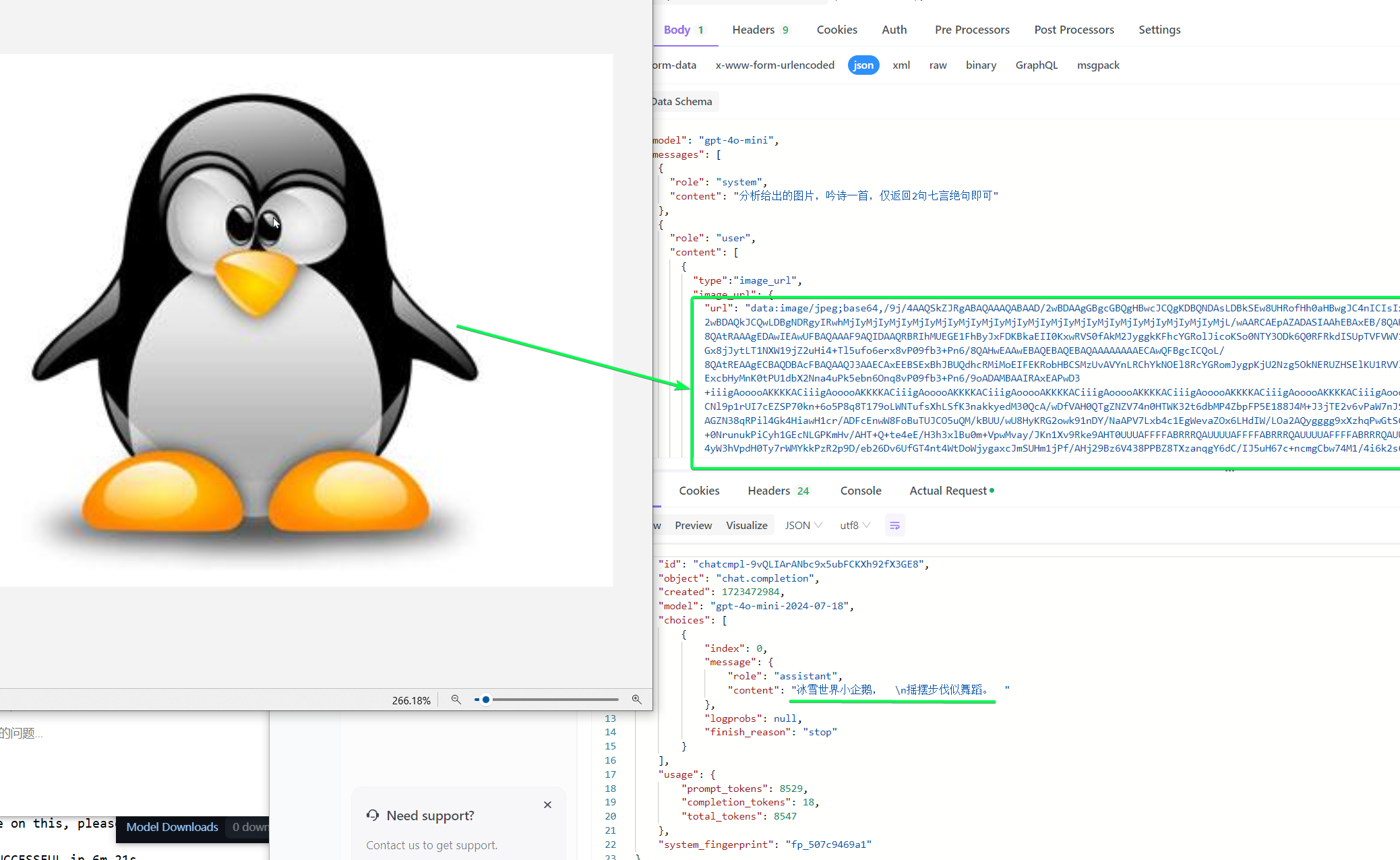
对于图片,openai的api中的messages部分,可以使用image_url传输图片的url,来支持图文形式的多模态,例如用iphone的快捷指令就可以快速实现一个看图吟诗的功能。
上面视频本质就是调用了gpt-4o-mini,参数如下。
2 RAG
上面多模态中pdf的例子,如果我们的pdf是一篇小说,小说的大小可能有1M,而一个模型支持的上下文一般在1k-256k左右,1M的小说本身就超过了token的限制。此外每次问一个小说中的问题,都需要在api中重新将小说上传,这样太浪费token效率也比较低。
RAG(Retrieval-Augmented Generation)直译就是检索增强生成,他由“检索”和“生成”组成。
检索就是在本地数据中检索出有用的数据,例如我们有一本书中华上下五千年的txt版,我们把这本书进行简单的拆分,例如本书有10章,我们就拆成10部分。现在我们提出一个问题,例如唐朝的开国皇帝是谁。此时就会先进行检索,从10章里面检索出最有可能包含问题答案的2-3章。
生成就是把检索的内容,提问给LLM,让LLM参考筛选出来的2-3章的内容,而不是全书的内容,来进行问题回答了。
2.1 embedding
上例子中,如何从10章里面挑选出最有可能含有“唐朝开国皇帝”答案的章节,这就有很多做法了,比如纯工程化的,进行“搜索引擎”构造,例如通过倒排,召回,粗排,精排。但是这种工程化方式缺少语意的理解。
如何加上语意呢?这就需要把各种文本给“向量化”,每一段文本表示成多维空间的一个向量,两个向量的距离越近,两个词就越相近。
如何把词句转换成多维向量呢?把文本转换成向量的过程叫做向量化,也叫嵌入也就是embedding,embedding的模型也有很多,例如LM studio的Local Server页面右上角位置,就有embedding模型选择,这个模型叫做nomic-embed-text-v1.5-GGUF。

openai提供的embedding模型如下,建议使用3,3-small的价格官方是1M 0.14元,3-large是1M 0.91元,建议使用3-small,2就不考虑了。

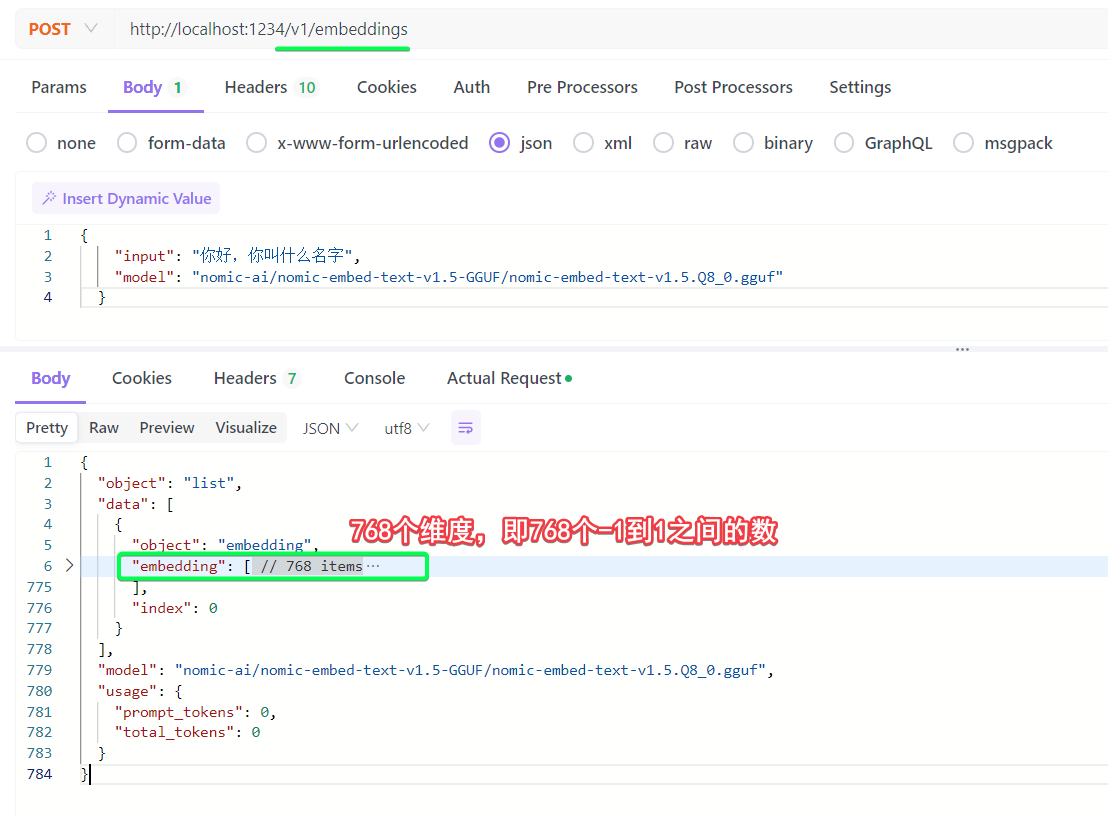
embedding接口也有着相同的规范,接口/v1/embedding,入参json只需要model和input两个参数即可,例如LM studio装载后启动服务即可如下请求。
openai的官方3-small模型:
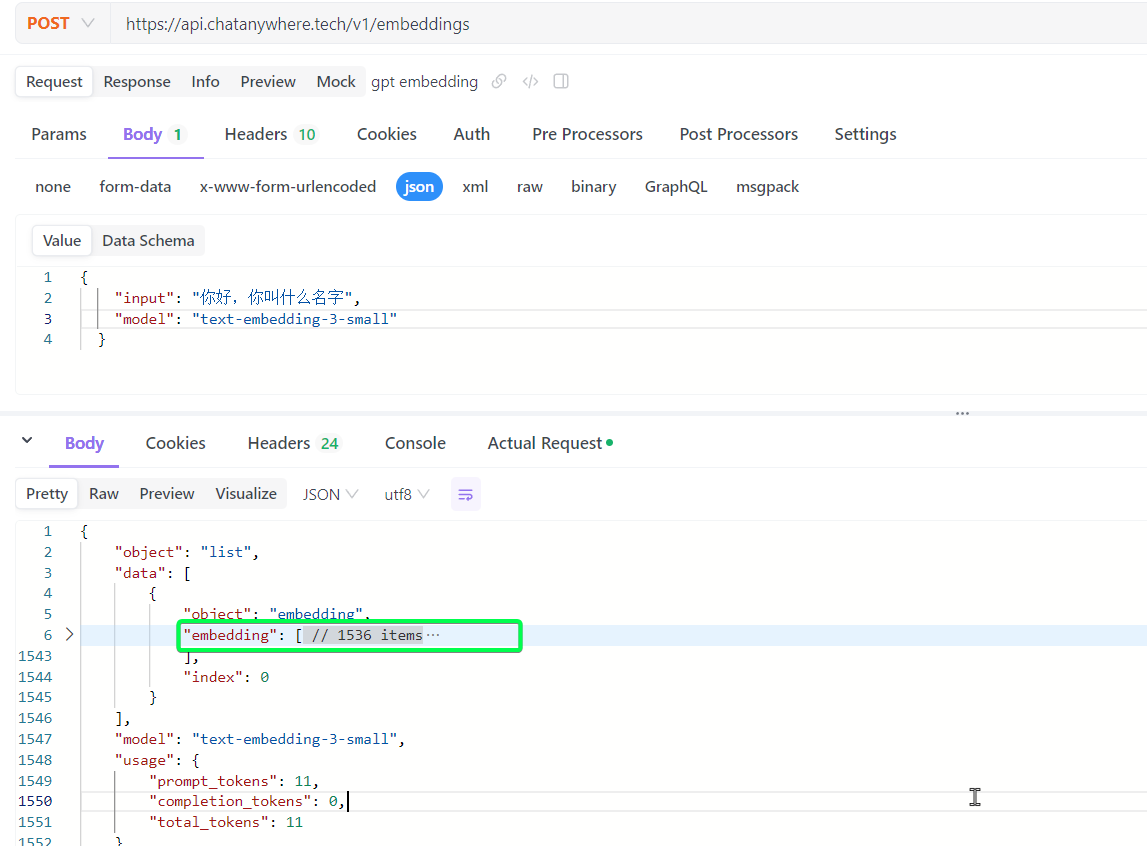
ollama pull bge-m3中文模型bge-m3,注意ollama这里api格式没有严格遵循openai的格式
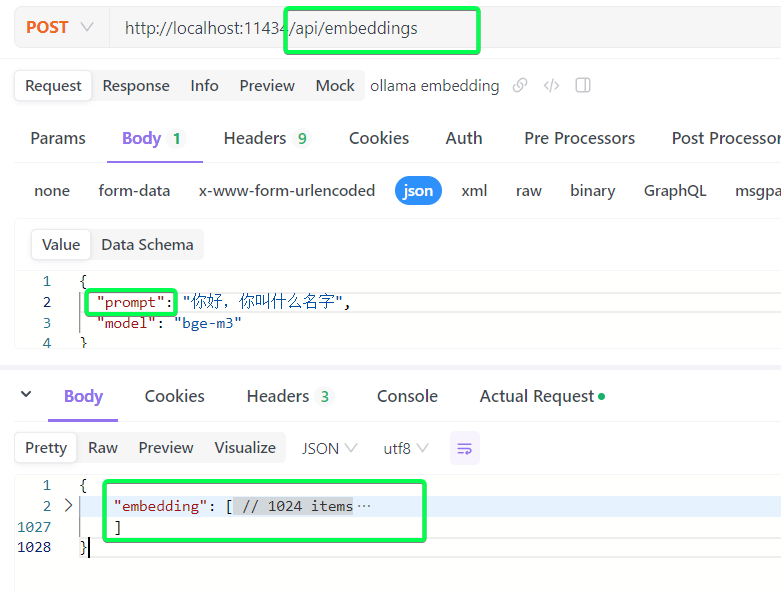
我们知道了嵌入embedding可以将各种数据给转成多维向量。如果有一本中华上下五千年,我可能需要每一章运行一次嵌入,最后得到10个向量,然后把要查询的问题也embedding以下得到一个向量,看这个向量和10个已有的向量哪个最相近。这里就引出了3个问题:
- 1 切分方式:章节切分不一定是一个好的切分方式,获取按照段落或句子切分,或者更复杂的其他切分方式。
- 2 向量数据库:章节的向量数据,每次都要用,应该提前存储,这就是
知识库,存储的数据库可以用普通的数据库,因为主要存储和计算向量距离,也可以用专门的向量数据库。 - 3 排序方式:计算相似度和排序的方式,或者叫
rank,也有很多,比如最简单的使用欧氏距离然后排序。
2.2 vector DB
向量数据库,主要目的就是存储上面数据本身,和数据生成的向量值;另外还需要提供快速的根据向量相似度的查询能力。向量数据库显然不是必须的,我们也可以将数据存到传统数据库,例如mysql中,但是这样计算相似度就要把数据拿出来自己计算了。
向量数据库的选型有很多,例如chroma milvus qdrant等,还有传统的postgres elasticsearch的增强插件,这里我们只是介绍向量数据库的作用,所以就选择内存中运行的chromaDB来做演示,这是最简单的。至于各种其他db之间的区别和优劣,我们以后单开文章去记录。
本地安装该数据库,pip install chromadb,插入数据和查询的过程非常简单,如下。
import chromadb
# 创建连接
chroma_client = chromadb.Client()
# 创建collection
collection = chroma_client.create_collection(name="my_collection")
# 添加数据
collection.add(
documents=[
"php是世界上最好的编程语言",
"youtube是最好的视频网站",
"北京教委:探索打造京蒙教育协作新品牌",
"七项机制助力北京CBD法治化营商环境建设",
"第十届京津冀青年科学家论坛举办"
],
ids=['1','2','3','4','5']
)
# 查询最相似的一条
results = collection.query(
query_texts=["开源社区中最活跃的是c/c++"],
n_results=1
)
print(results)
这里没有指定采用什么embedding算法,运行该文件的时候会看到默认会先下载all-MiniLM-L6-v2,即默认采用的就是你这个嵌入算法,这个算法非常小巧模型只有不到80M,维度有300+,只不过整体的效果有点拉,上面的数据得到的最相近的结果是4,什么环境建设,但是明眼人都应该知道其实应该是1.
{'ids': [['4']], 'distances': [[1.0054192543029785]], 'metadatas': [[None]], 'embeddings': None, 'documents': [['七项机制助力北京CBD法治化营商环境建设']], 'uris': None, 'data': None,
'included': ['metadatas', 'documents', 'distances']}
chromaDB接入的代码非常的简单,他屏蔽了很多很多细节,比如
- 内存中运行,进程结束,数据就没了。
embedding算法默认就用了一个非常小巧的模型,不需要设置。- 求出的向量的值,以及如何比较两个向量的距离,这些也都默认屏蔽了。
替换成上面我们用的“大”模型,写法如下:
$ pip install requests
import chromadb
import requests
import json
########## 定义embedding函数,直接请求lm studio ###################
def embedding(input):
url = "http://localhost:1234/v1/embeddings"
payload = {
"input": input,
"model": "nomic-ai/nomic-embed-text-v1.5-GGUF/nomic-embed-text-v1.5.Q8_0.gguf"
}
headers = {
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
return response.json()['data'][0]['embedding']
####################################################################
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="docs")
documents=[
"php是世界上最好的编程语言",
"youtube是最好的视频网站",
"北京教委:探索打造京蒙教育协作新品牌",
"七项机制助力北京CBD法治化营商环境建设",
"第十届京津冀青年科学家论坛举办"
]
ids = [str(i+1) for i,doc in enumerate(documents)]
embeddings = [embedding(doc) for doc in documents]
collection.add(
documents=documents,
embeddings=embeddings,
ids=ids
)
query_text="开源社区中最活跃的是c/c++"
# 查询最相似的一条
results = collection.query(
query_embeddings=embedding(query_text),
n_results=1
)
print(results)
# 打印结果:
# {'ids': [['1']], 'distances': [[1.1179535388946533]], 'metadatas': [[None]], 'embeddings': None, 'documents': [['php是世界上最好的编程语言']], 'uris': None, 'data': None, 'included': ['metadatas', 'documents', 'distances']}
使用lm studio的嵌入算法,结果就更合理了,也可以将上面的url地址改成本地的ollama测试之前下载的bge-m3模型的效果,其实也是返回第一条。
这就是一个简单的代码例子了,chroma存内存的方式会导致数据容易丢失,可以采用持久化的方法代码类似下面。
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="sqlite",
persist_directory="db/"
))
这里建议大家去了解一下上面列出的其他几个db,他们大都是持久化存储,并且开源的同时,提供了一定额度的云服务,对于个人开发者或者初学者是肯定够用的。
这里稍微一提,关于两个向量的相似度是怎么求的,简单的有以下三种,其中余弦相似度是chromadb默认使用的,相似度的算法不是特别重要,因为各种算法求出来的相似度排序大致是一致的。
- 曼哈顿距离,
|a1-a2| + |b1-b2|,每个位置差值的绝对值,求和,绝对值的和=>L1范数 - 欧几里得距离,
(a1,b1)和(a2,b2)的欧距就是[(a1-a2)^2 + (b1-b2)^2]^(1/2),也就是常见的几何距离,平方和开方=>L2范数 - 余弦相似度,
(a1*b1 + a2*b2) / ((a1^2 + b1^2)^(1/2) + (a2^2 + b2^2)^(1/2)),分子是点乘结果,分母是两个向量自身的L2范数求和
3 RAG in prod
接下来看几个整合了RAG的工具,然后分析他们的实现原理,来理解每个步骤的细节。
3.1 AnythingLLM
那么第一个超级整合软件就是AnythingLLM,下载安装后。他需要选择默认的聊天模型是请求哪里,可供选择的有供应商有很多,我们选择LM studio,因为这个软件会打印请求和返回的参数,这对于我们了解RAG的过程是非常有帮助的,这个供应商也可以在我们创建完工作区之后,单独配置,如下,我指定了LM studio中的qwen1.5-7B模型。
然后配置向量数据库为默认lancedb即可,或者别的也可以,只是一个数据存储,这里我改成了本地的qdrant,他会在控制台打印请求日志有助于理解发生了什么。
然后配置embedding模型是ollama的bge-m3,这里也可以用默认自带的,至于为什么不用lm studio,主要是我电脑这里选了之后,识别不出可用的embedding模型。
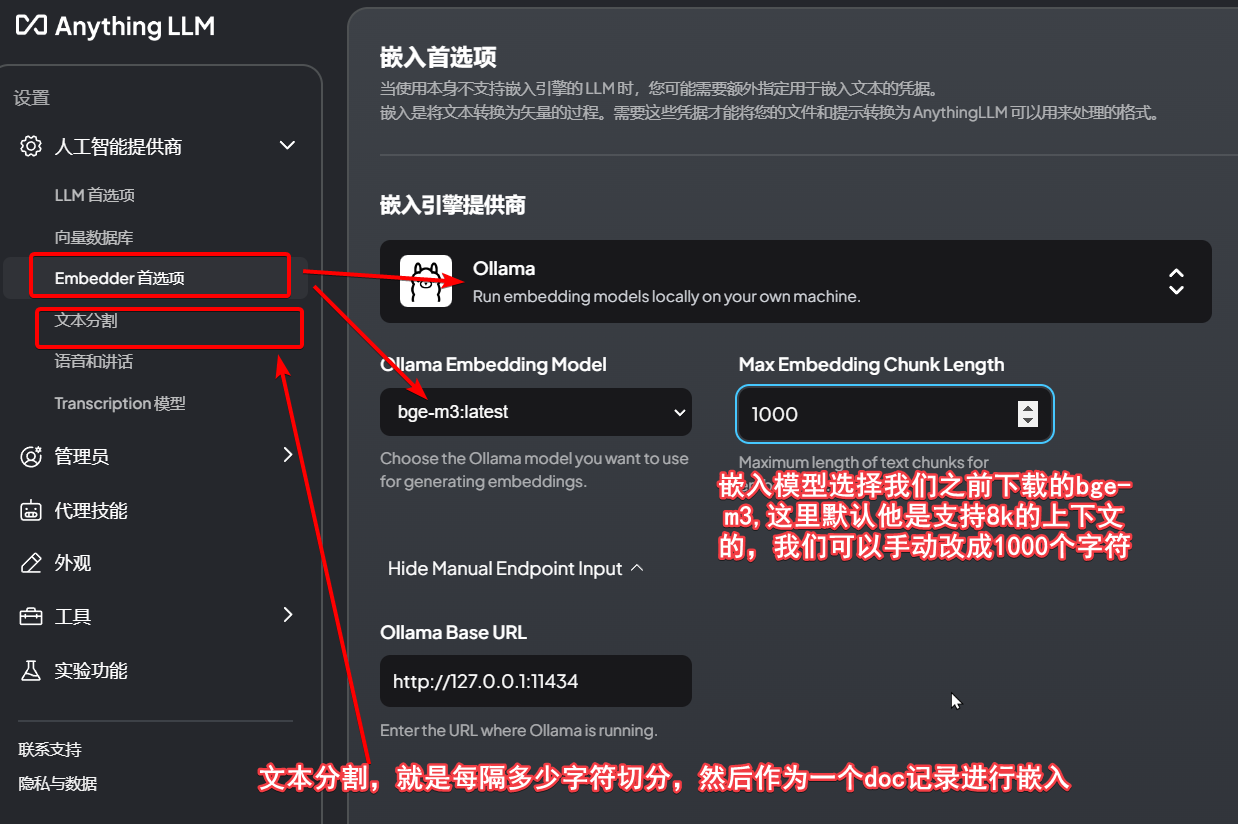
接下来我们来配置rag的数据,点击上传按钮,把本地的4篇java相关的md文档传上去
上面步骤就是知识库向量化,然后存入向量数据库的过程,他会
- 先调用
文本分割,按照1000字符切分文档,这里我们的网站非常简单不需要切分; - 然后对切分后每个块,进行embedding,使用的是配置好的
bge-m3 - 然后将结果保存到向量数据库
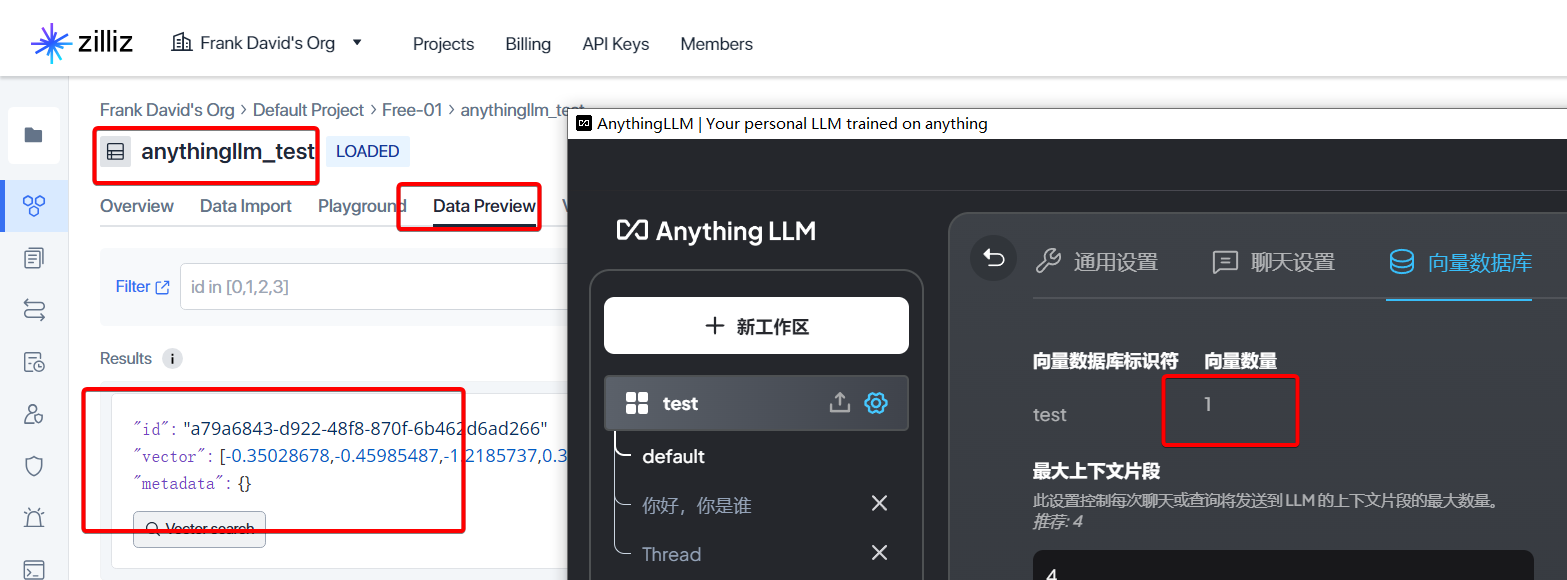
问一个关于我们博客首页的简单问题,然后查看lm studio的入参打印.可以看到,索引出来的结果会作为prompt中追加的一部分,以[CONTEXT 0]:xxxx[END CONTEXT 0]的形式,如果有多个doc命中,这里就会有多条。
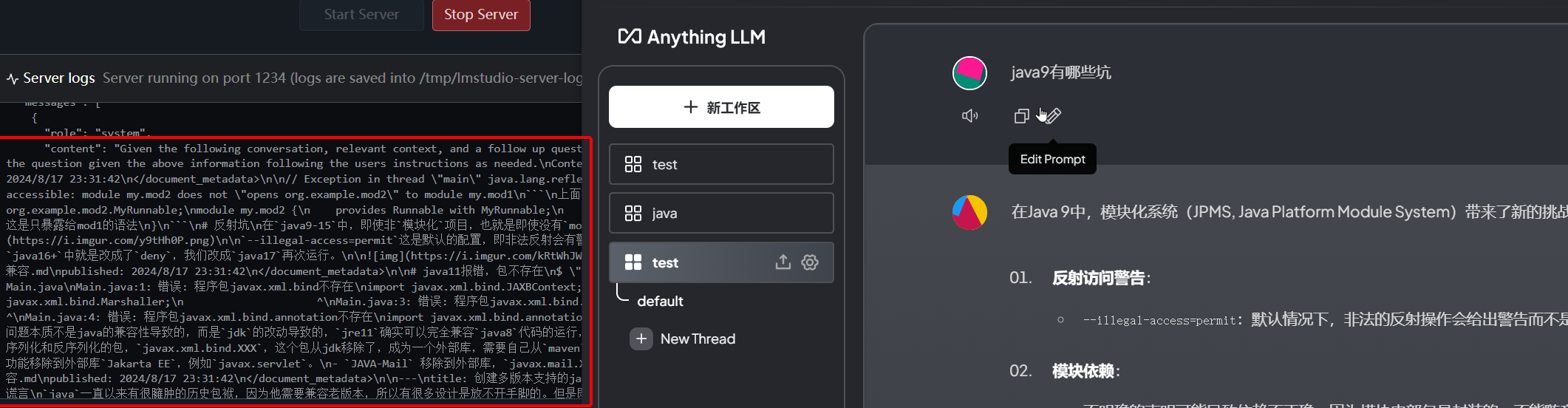
把提示词复制出来,可以看到三段上下文。均来自我们上传的文档中的片段。

所以到这里我们知道了,RAG检索后的结果,是作为了提示词,再发送给LLM进行总结的。当然这个要看不同工具链的实现,coze平台的知识库结果,是作为user输入信息,而不是prompt。
3.2 QAnything
QAnything是有道开源的一个检索系统,通俗讲就是一个RAG系统,我们在AnyThingLLM和文章之前的内容,介绍了RAG的基本流程:就是将数据拆分成chunk,然后给向量化embedding得到向量,存储到向量数据库,然后用户输入问题的时候,将问题也向量化,对比向量数据库中的数据,选出topK条相似度最高的。
然而在实践中,会发现这种基础的检索,在数据量越来越大的时候,效果会变差,召回的数据准确率下降。
基于这个角度,网易有道开源的QAnything对检索的流程进行了调整:
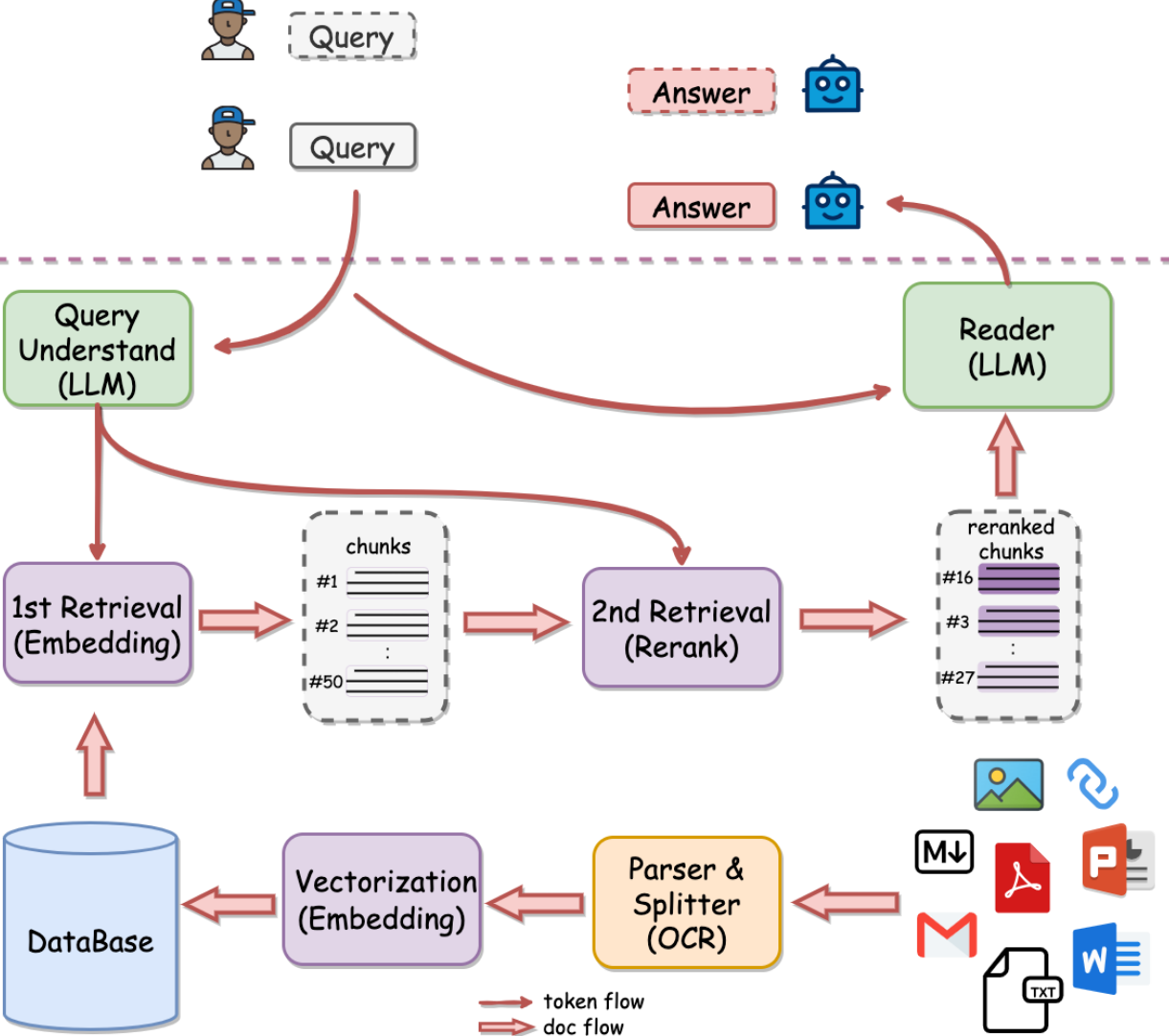
我们从这个图的右下角开始:
- 输入的数据源是
txtwordpdf等文本数据,也有png等图片数据。 - 异构数据接下来会进行转换
parser,例如图片会ocr,word pdf也有专门的转文本能力。文本接下来会进行拆分成chunk,也就是Spilitter。 - 对
chunk文本进行向量化embedding存入向量数据库。
这就是图片最下一行的步骤,与我们之前讲的基础的RAG是一样的。
不同点:
- 当用户查询的时候,基础流程是直接对
query进行嵌入,召回database中的相似数据。而QAnyThing流程中,是左上角节点Query UnderStand(LLM),即他使用特定的prompt和LLM对用户的query进行了理解和提炼,得到提炼的结果去database中去召回。 - 召回的数据,没有直接喂给LLM,而是扩大了召回的数据量,对召回的数据进行了
rerank再排序或者叫精排,精排后过滤出topK传给LLM。
以上两个不同点,尤其是rerank对检索大数据量的精确度提高是非常有用的。
那么什么是rerank,其实目前rerank和embedding一样也有很多模型了, 例如有道的bce-reranker-base_v1, BAAI的bge-reranker-v2-m3等。
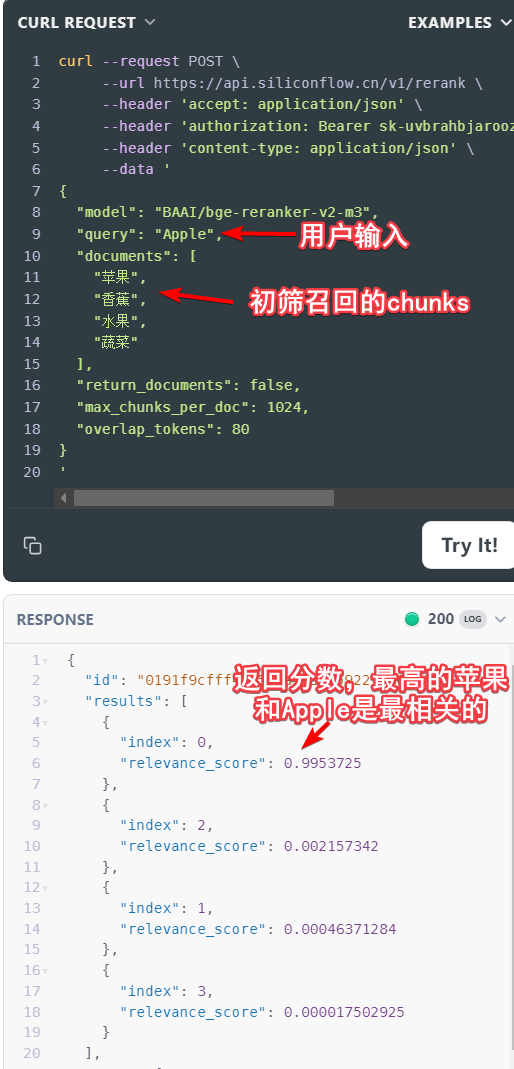
4 memory
LLM是无状态的,我们的上下文也都是通过把所有的会话重新传递给LLM,让他从前面的会话中,去了解我们的一些倾向的。
例如我是一个java程序员,我想让gpt给我写一个代码,如果一开始没有说明我是javaer,他可能就用其他语言来写。经过我后续会话声明我是个java程序员之后,他就能按照java来回答了。但是当我再次开启一个新的编程会话的时候,LLM又会忘记我是一个java程序员了,这就是LLM没有状态,没有记忆的体现。
更通用一点的,比如我要开发一个AI厨房应用,用户不吃香菜,但是每次问AI某某菜怎么做,AI都不会记得该用户是不吃香菜的。
memory就是从这个角度出发,期望能解决大模型的记忆问题,具体怎么做的呢?我们以目前比较出名的开源mem0为例,我们直接使用mem0.ai提供的云平台来探究他的工作方式。
我们直接在playground中问自己是哪国人,llm显然无法回答,然后我们告诉他自己是中国人,以及个人的一些喜好,可以看到右侧栏,提取出来了我们的国籍、职业和食物喜好信息,这些信息其实都存到了用户的标签中,可以在左上角user中查看到。
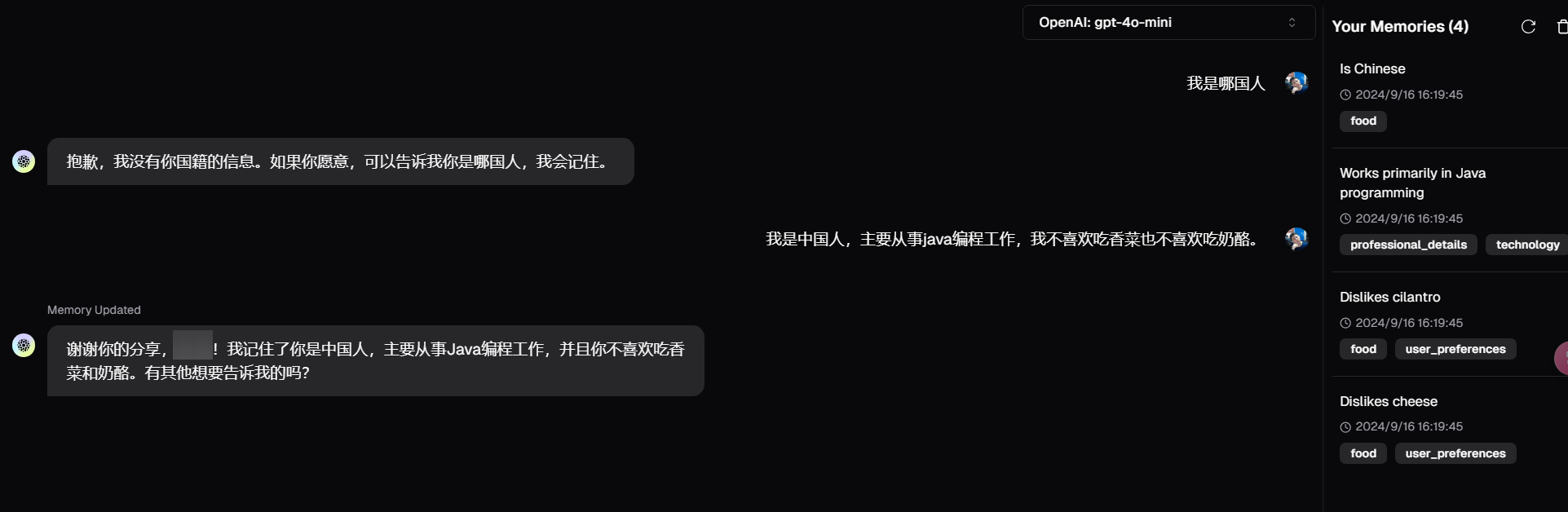
当然如果我们的对话中,没有个人的喜好和信息,比如我们就直接问,大气层有多高,他就不会提取任何信息到mem0中保存,当我们再次打开一个新的对话框的时候,就会发现,此时的gpt是有记忆的,他知道我们不喜欢奶酪了。有点像针对LLM的用户画像了。
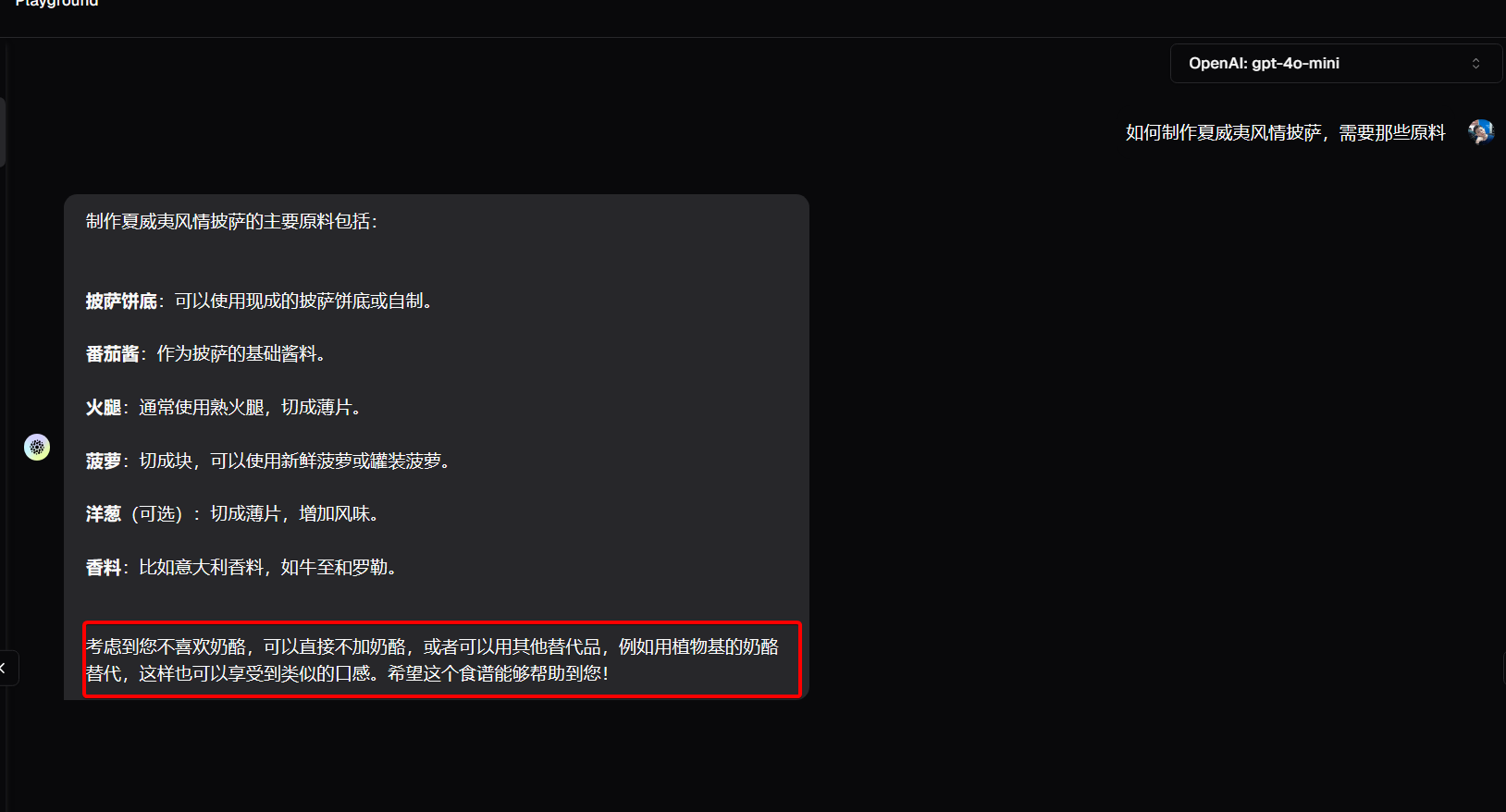
这个怎么实现的呢?
4.1 提取(添加)用户标签
到doc中查看代码接入教程,你会发现,在使用mem0的时候,需要配置LLM例如openai的key的,然后我们正常的和llm的对话内容,都需要传给mem0,让他来分析是否有可以提取的个人画像信息,下面是官方的例子,这是正常的和ai的对话内容,传给mem0后,他会用上面配置好的key调用大模型,让大模型从中解析用户画像的标签,然后将结果存储下来。这就是add的过程。
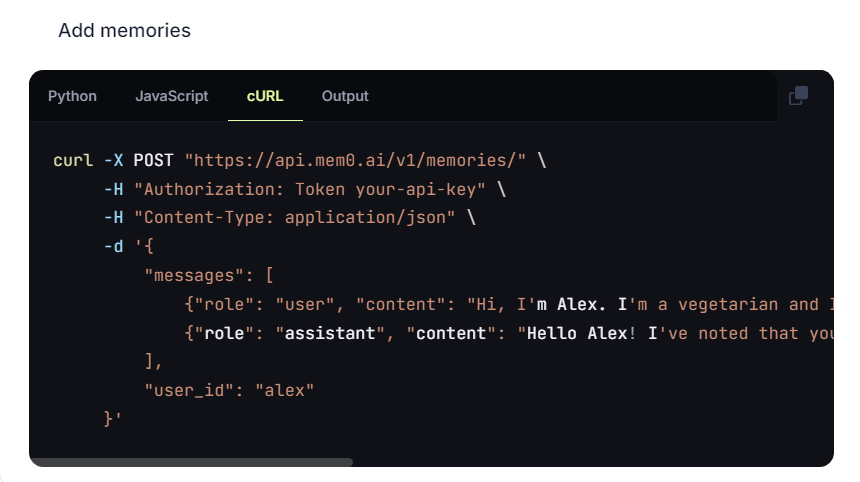
这里让LLM提取用户信息的请求是mem0异步发送的,和当前会话并不冲突,提取个人信息的prompt也可以自定义,参考官方文档https://docs.mem0.ai/features/custom-prompts
4.2 存储方式
混合存储,会同时往向量数据库、kv数据库、图数据库等多种形式的db中进行插入。

可以用neo4j来存储图形关系,也可以不用,就不存入图数据库。
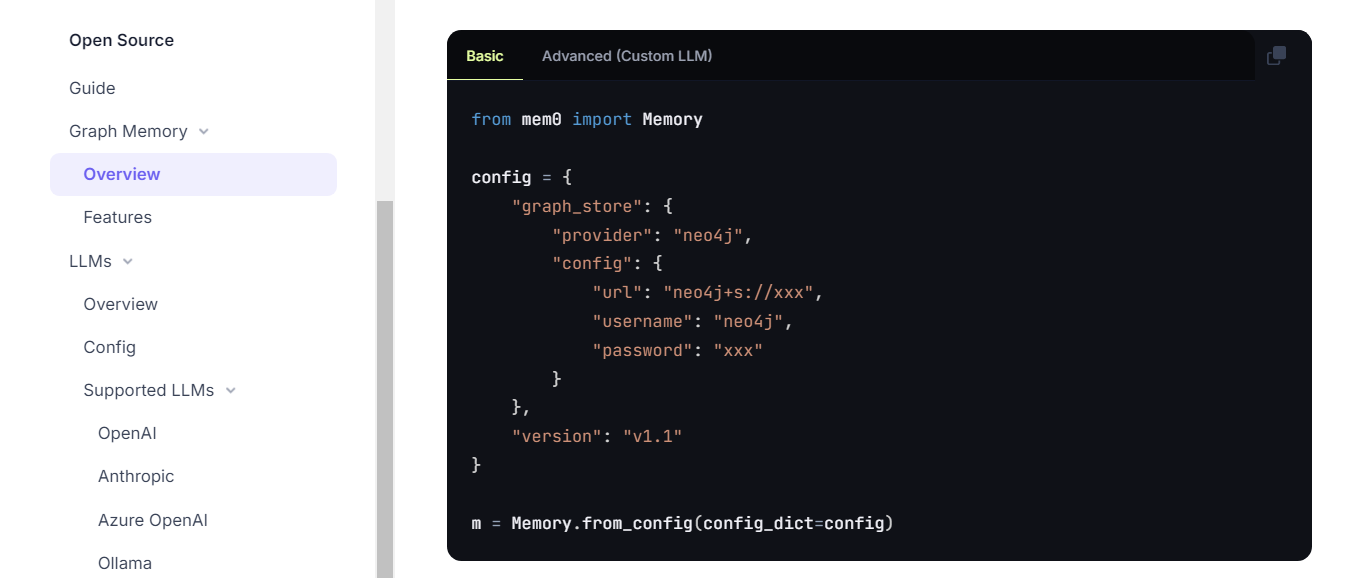
4.3 检索
那后续如何搜索的呢,也就是下面search接口,就是在和ai直接对话之前,需要调用mem0#search接口,这个接口就是mem0这个项目最核心的部分。
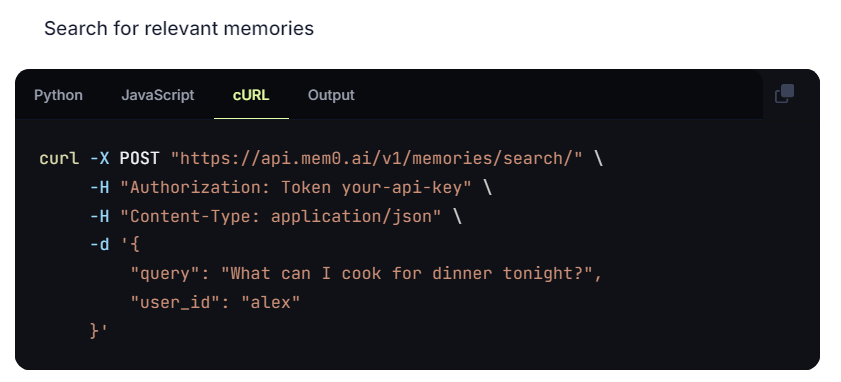
官方的解释是会在多个数据源上都运行查询,然后经过各种排序打分最后得到,当前会话可以用的上下文信息,然后将这些信息放到LLM的prompt中。

4.4 小结
记忆算是一个锦上添花的功能,现阶段应用的较少,作用也不算大,因为收效不大,而且需要的存储成本提高、LLM成本基本翻倍。