1 序言
LLM可以说是近些年最火的技术了,也确实给我们的生活带来了完全不同的体验,基于LLM的AI应用不断地涌现,很多人都会感觉自己out了。别慌,看完这篇文章,你会对LLM相关的应用,运行的方式有较好的理解,以后看到别的应用,大体也能猜出他的运行原理了。
在本文中,我们不会介绍LLM运行原理这种理论知识,更多的是把这些技术作为一个黑盒子,让你可以快速的了解到应用的运行方式,以及他们是如何盈利的。
在之前其实有过几篇文章介绍LLM相关的内容,但是觉得写得不够清晰,所以重新整理了这篇,希望能更简洁、通俗。
2 chat能力与聊天应用
LLM大语音模型,他的基础能力就是提供了语言对话的服务,也被称为底座模型。chatGPT最早就是以聊天机器人的形式出现的。用户输入一段文本,比如提出一个问题或者给出一个话题,LLM会根据其训练数据和算法生成相应的回复。这就是LLM最基础的能力,像通义千问 豆包等,都提供了聊天应用。
chat作为最基础、最重要的能力,一般也会对外直接提供API来进行调用,而这些提供API的服务,又被叫做LLM供应商(之前的文章中盘点过市面上一部分常见的供应商)。chat接口的形式大部分供应商都是兼容或者类似openai(gpt的公司)提出的接口规范,是个http接口。URL一般是${baseURL}/chat/completions,而具体的参数形式可以查看openAI文档
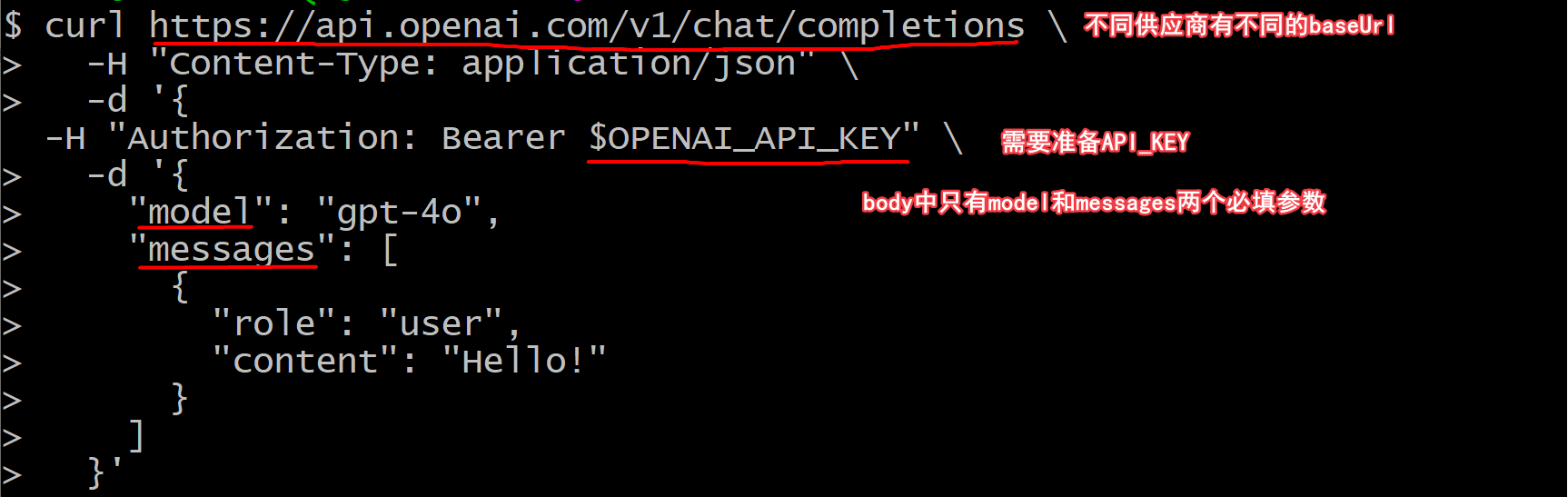
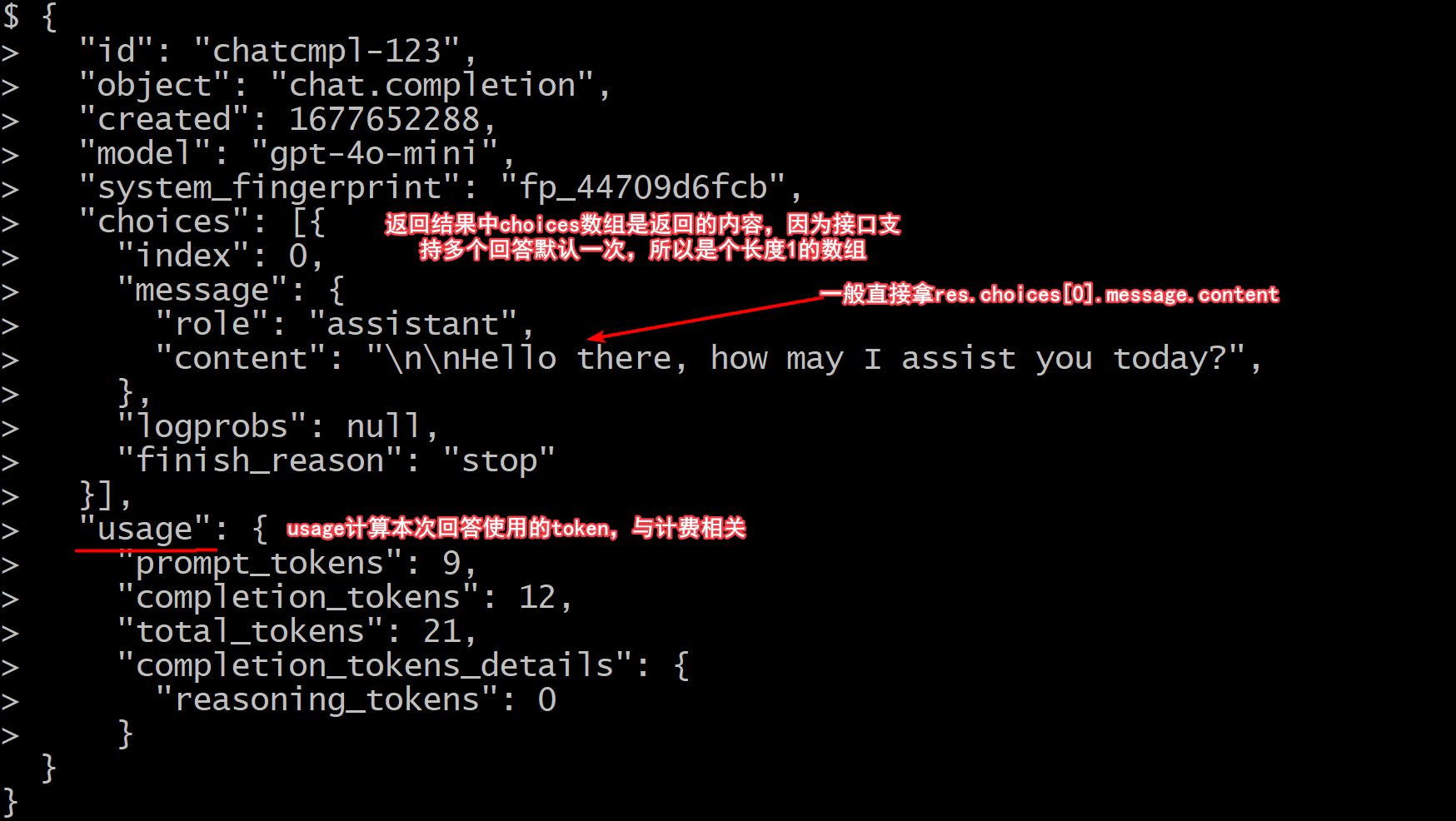
在请求中有个
stream参数默认为false,如果为true,则会返回一个流式的响应,这就是聊天应用不断地发送消息的“蹦字”效果。
有了chat接口,就可以不在官方的聊天页面进行交互了,我们可以在任何自己的应用中嵌入LLM的能力,例如第三方的聊天软件chat box、chrome插件sider等等,我甚至还让ai帮我写过一个类似的聊天室
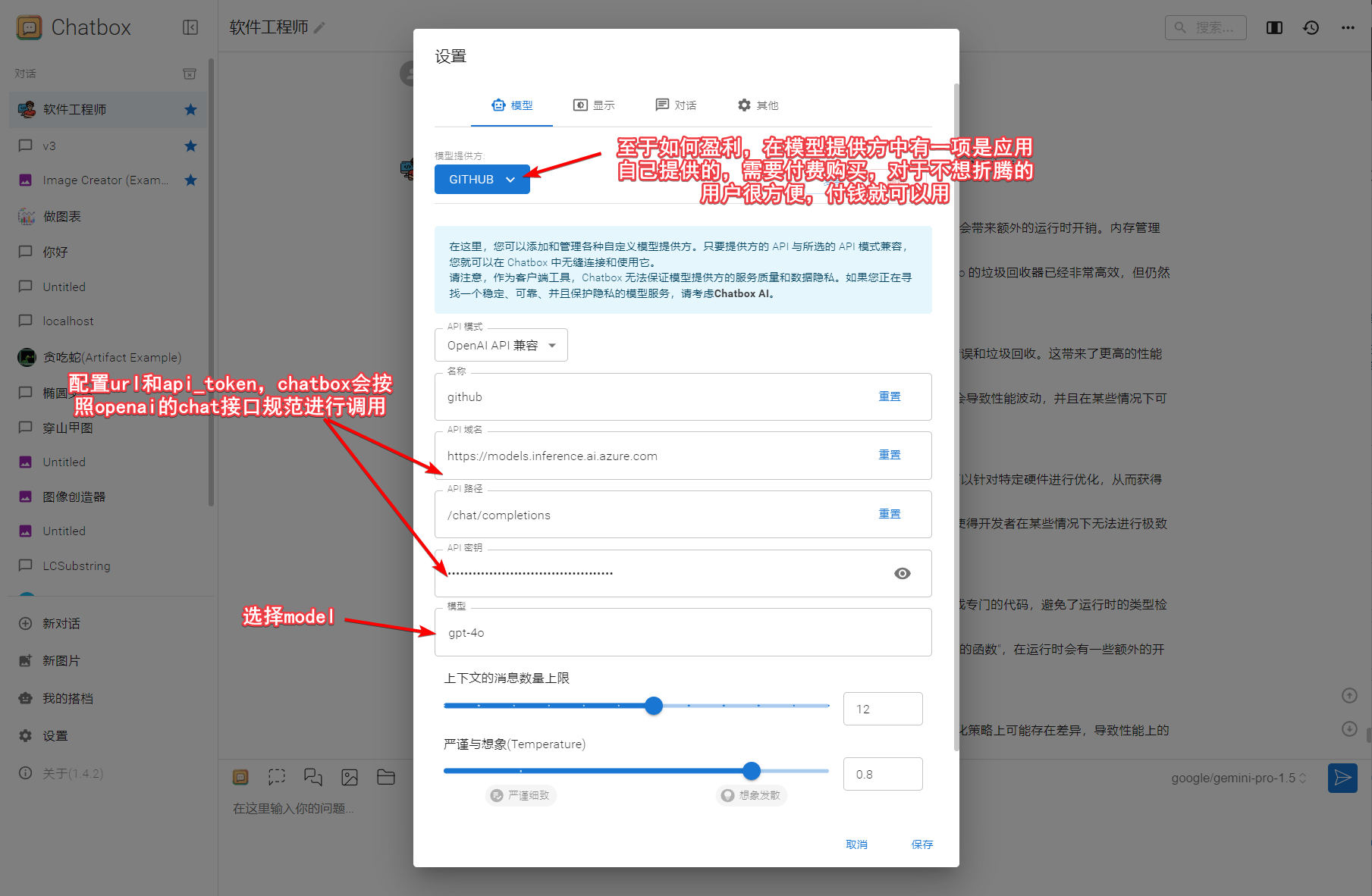
接口是无状态的,那是知道对话的上下文的呢?是通过将历史的对话记录,都放到入参
messages数组中,用户说的话role=user,模型说的role=assistant。
有了模型,把他部署成服务,提供接口,这就是LLM供应商了,OpenAI就是一个供应商;还有些公司部署的是开源模型,也提供出了chat等接口,例如silicon cloud groq等也是一种供应商,他们都是售卖gpu算力赚钱;此外还有一种供应商是转发请求,把用户的请求转发到openai或者groq等,而用户付费在自己的平台,例如openrouter等,他们有些是赚取差价。具体的可以查看LLM供应商这篇文章,有详细的展开。
小结:聊天类的应用非常适合日常答疑,替代部分搜索引擎的功能,找一个国内可以接入的供应商例如silicon cloud、openrouter,在chatbox中一配置,就可以激活你的AI助手了。
3 prompt提示词
在使用 chat 接口时,prompt 提示词是一个非常重要的组成部分。它是指引模型生成回复的关键信息。通过精心设计的 prompt,你可以引导模型产生符合你需求的回答或内容。
入参messages就是提示词,可以设置role=system/user/assistant等消息内容,提示词也是一门学问,其中system类型的消息是对LLM角色和能力的设定,他对模型的返回内容有着很大的影响。在LLM的计费中,提示词或者叫输入,和模型的输出是分开计费的,一般输入token的价格要低于输出的token价格,但基本上差距在10倍以内。
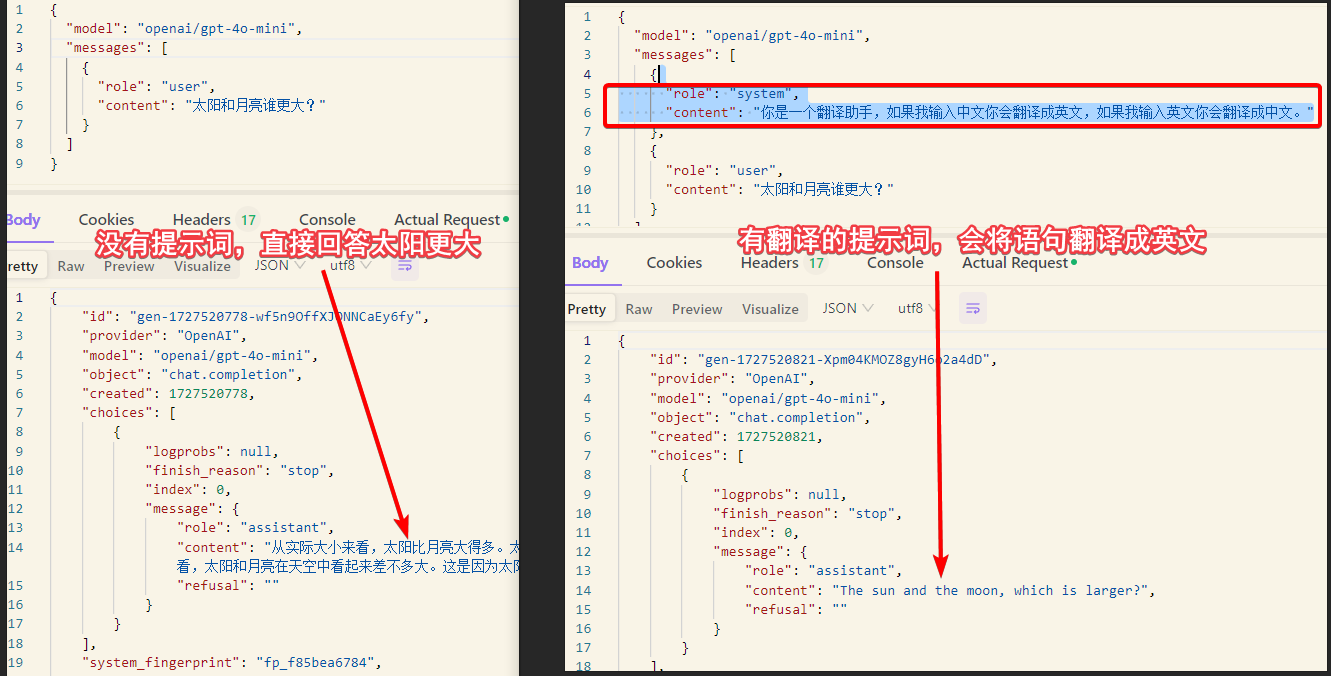
提示词的遵循程度是一个模型好坏的重要衡量指标,有些模型名字会看到-instruct后缀,例如Qwen2.5-72B-Instruct,都是基于基础的模型上进行了调整,能够更好的遵循指令的版本。

精心调整的提示词 + 底座LLM模型 = 应用
很多应用都是上面这个简单的等式得到的,比如上面这个翻译的提示词就可以用来开发一个翻译应用;而沉浸式翻译中使用大模型翻译的功能,也是类似的实现;webpilot也是一个chrome插件,他能基于当前网页的内容,进行ai问答。
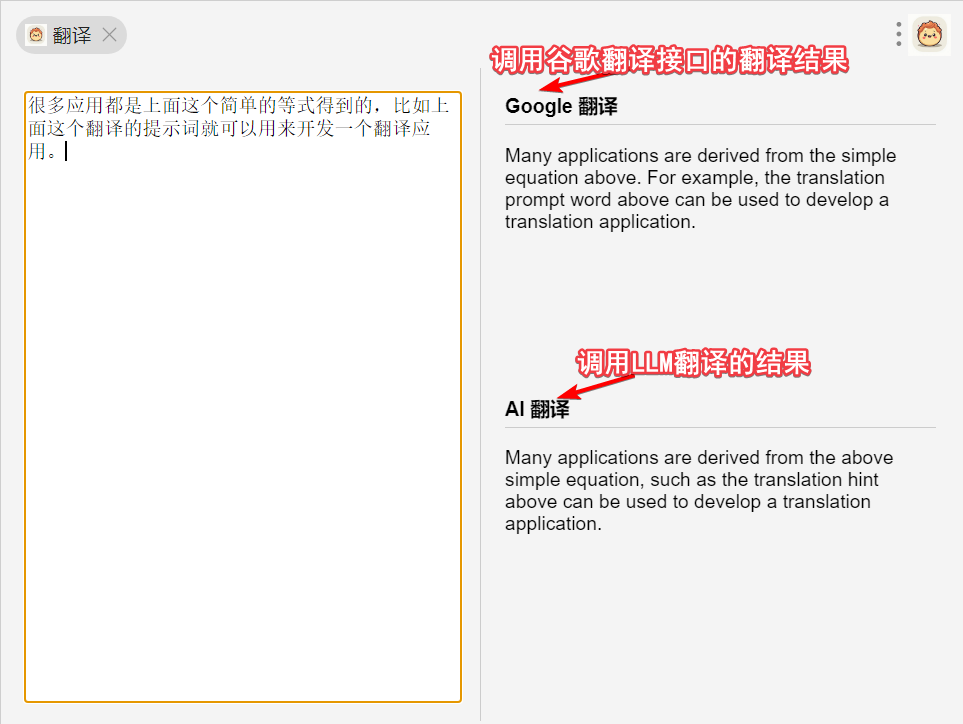
关于模型的定价,可以以
claude3.5为例,他的input也就是提示词,是百万token $3,输出则是$15,同级别的模型价格是接近的。
那一个token对应多少汉字或单词呢?这没有固定的对应关系,一般1个单词大约有1.5个token,一个汉字大约是1个token,实际可能有浮动。
小结:精心调配的提示词对实现功能非常重要,所以有专门的提示词工程师,网上有很多提示词小技巧的教程,可以简单去了解。
4 function calling 函数调用
函数调用确实是实现复杂应用和增强模型功能的重要手段之一。通过函数调用,模型不仅可以执行内置的功能,还可以与外部API和服务进行交互,从而获取实时数据、执行计算任务或操作数据库等。这种灵活性使得基于大语言模型的应用能够更加丰富和实用。
函数调用并不是让LLM直接去调用某个函数,而是把一系列函数的名称和参数传给LLM,后者根据用户的输入进行自然语言解析,分析出是否要调用以及如果调用函数,具体调用的是列表中哪一个函数,对应的参数是什么。
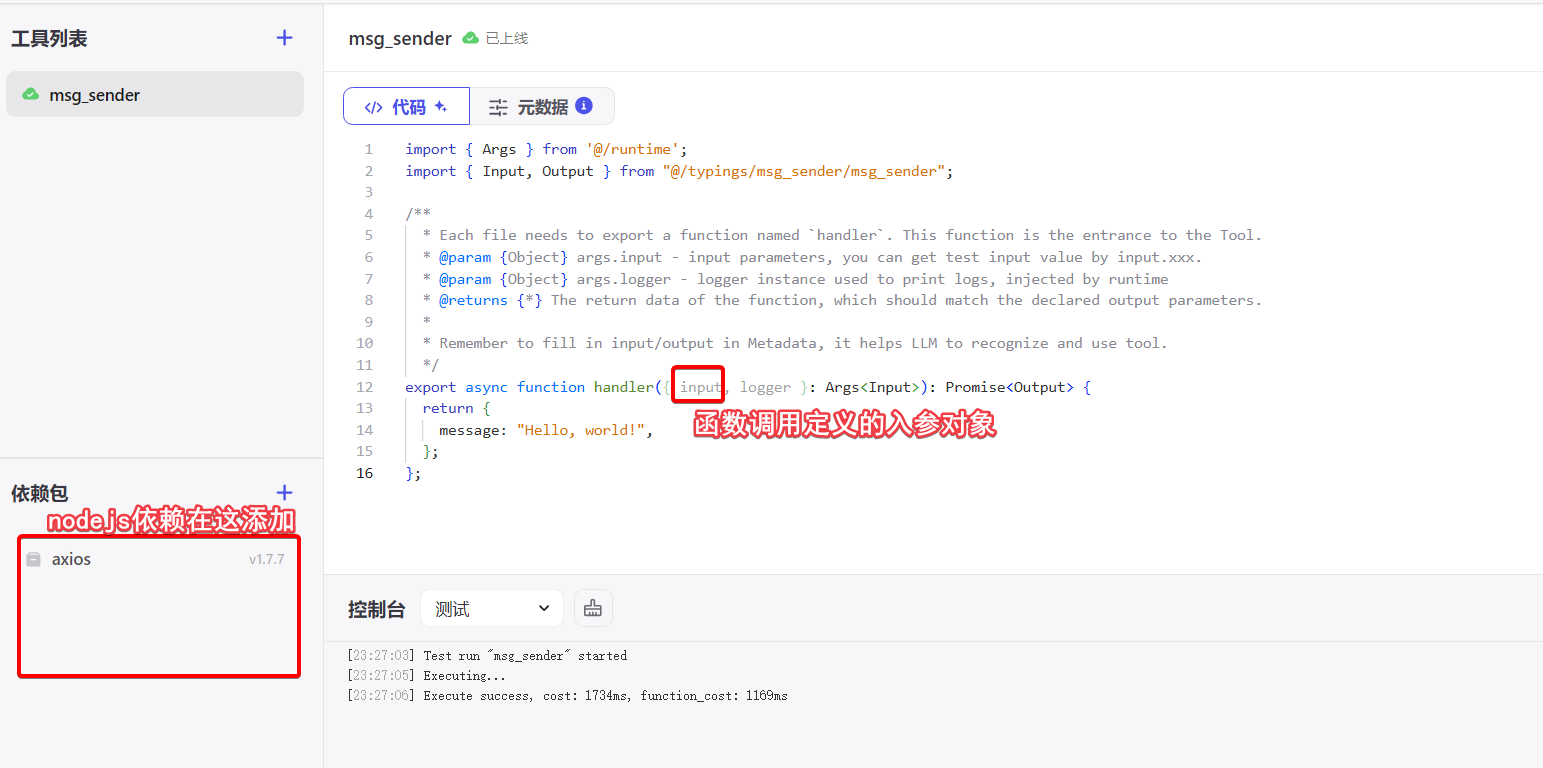
用法是通过chat接口中的tools入参,该入参的样例如下,这是一个发送邮件的函数。
"tools": [
{
"type": "function",
"function": {
"name": "send_email", // 函数名
"parameters": { // 参数
"type": "object", // 参数是个json对象
"properties": {
"email": { // json中email表示收件人
"type": "string",
"description": "收件人邮箱地址"
},
"content": { // json中content表示邮件的内容
"type": "string",
"description": "发送的邮件内容"
}
}
},
"required": [ // email和content都是必需的参数
"email",
"content"
]
}
}
]
我们来看如何在chat接口中使用:
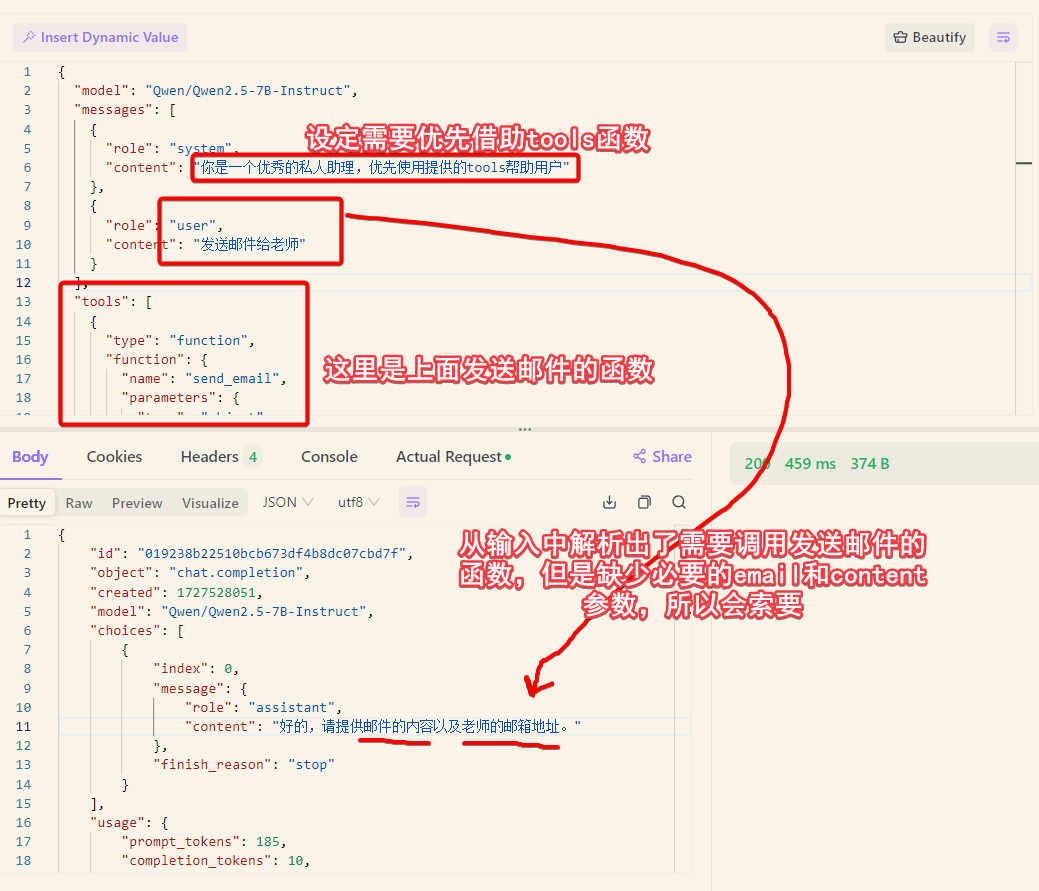
函数调用给了应用非常大的空间,上面发送邮件只是一个非常简单的场景,比如我们可以把谷歌搜索作为一个插件,然后prompt中设置让ai借助搜索引擎插件将得到的信息进行汇总并生成答案,openai的插件市场(插件基本都是函数调用)就有这样的插件,Bing Ai也是类似的工作方式。
用AI + 搜索引擎代替传统搜索引擎,也是一个赛道,目前比较有竞争力的产品有perplexity.ai,还在内侧阶段的有openai的searchGPT,个人感觉是ai搜索确实有效果,信息收集和汇总很不错,但是一些比较冷门的问题,容易漏掉一些信息,不如从谷歌上列文虎克式的浏览每一项,总之就是有共识的内容搜索效果不错,细节性问题的肯定是不如人自己去判断每条信息。
openai市场上有很多插件,但是国内用户不太能用得上。适合中国宝宝的coze平台也提供了很多插件,比如百度搜索插件、OCR插件、HTTP请求插件、生成二维码插件等等,而且你也可以写代码自定义插件。
关于coze还有很多其他功能,我们后面会讲到。
5 多模态
大模型的多模态能力,现阶段主要是指可以向模型输入图片来进行解析,只有部分模型支持,比如gpt4o 4o-mini qwen-vl gemini molmo等等。多模态能力的基本用法就是上传一张图片,让模型去解析图片,并且返回图片的描述。
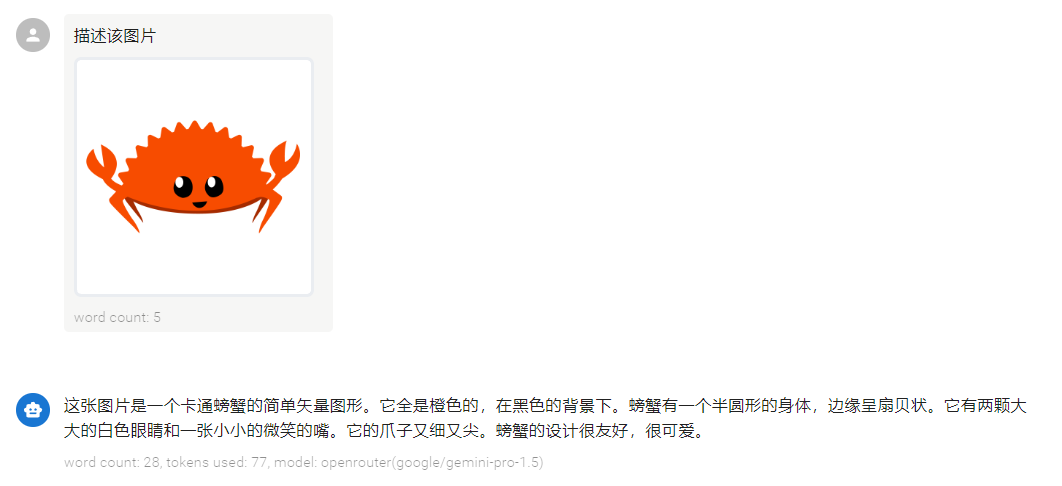
具体来说是通过API中的messages参数中指定一张图片,图片可以是http(s)://开头的网络图片的url,或者是base64编码的图片,以data:image/jpeg;base64,开头的图片编码。
{
"model": "google/gemini-pro-1.5",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
]
}
多模态的应用场景目前还比较少,大多数chat app中支持上传图片,进行图文混合的提问,能提供一定的OCR能力。另外就是molmo官方视频里展现的那样有强大的识别能力,还提供了标识point指出物体在图像中的位置。
6 RAG与相关工具
RAG (Retrieval-augmented Generation)也是常听到的一种技术手段,通俗讲就是:因为模型的上下文长度是有限的,如果业务数据总量超过了上下文,例如gpt-4o上下文是128k,就需要压缩上下文的长度。此外很多上下文的内容也不是必须传给LLM的。
例如有一本人物传记,我们想要LLM根据书中内容,回答这个人18岁高考考了多少分,去了哪个大学,那么整本书的内容都作为prompt显然不必要的,RAG的作用就是把高考、大学等相关的信息提炼出来,到这本书中去检索,找到相关性比较高的章节,把这部分章节作为prompt,这样就大大减少了prompt的长度。那么RAG是如何检索出相关性高的部分章节的呢?
其实是通过向量化或者叫嵌入或者叫embedding,我们把embedding理解成一个黑盒的函数,他的入参是字符串,出参是一个向量或者叫double数组,数组长度就是嵌入算法的维度,任意的字符串甚至是其他数据形式,都可以通过embedding函数得到一个向量。那么我们可以把我们的知识库,上面例子中就是正本人物传记,先进行拆分,比如每个章节拆分、或者每个段落、或者固定的每1k个字进行拆分,拆分成多个分片chunk,每个chunk运行embedding函数得到向量,再把chunk和向量存起来,可以存到普通的数据库,也可以是向量数据库(Vector Database),后者对向量存储、查找、计算都有专门优化。
实际RAG接入chat流程如下,我们首先通过上述过程将知识库向量化之后存到了向量数据库。当用户发起query, 我们可以通过embedding函数得到相应的向量,然后检索向量数据库,得到相似度高chunks,即找到相关性比较高的章节,把这部分章节也就是图中的context和用户的问题query拼接起来,有的应用是直接拼到role=system的message中,有的是新增一条role=user的消息,总之都是作为prompt传给LLM。
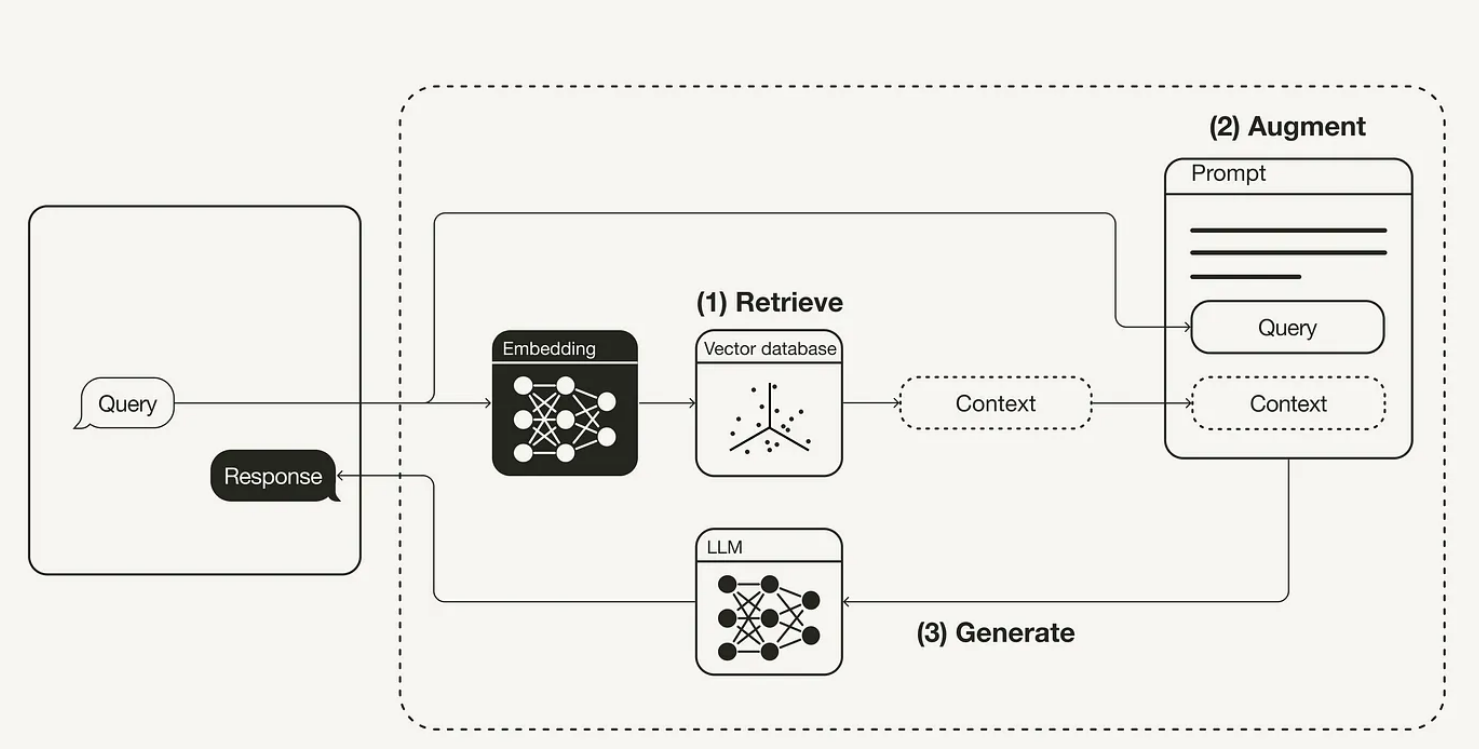
对于embedding,目前和LLM大模型一样,有很多算法,接口定义可以参考,一般就是入参为字符串,返回double数组。openai google等,都提供了闭源的embedding实现的接口,silicon cloud上也有一些开源的实现,效果也都不错。之前的tab manager的视频,就是一个很好的单点的去理解embedding函数作用的例子。
在应用上,RAG环节主要有两种应用,一种就是向量数据库,纯做数据库的,目前世面上有很多,chroma qdrant等等,还有对传统数据库进行向量能力增强的postgres es等,大家可以自行去了解;另一种应用就是做RAG应用,其实就是把上面我们提到的这个检索的过程进一步的进行调优,和细节丰富,比如知识库引入pdf/word转文本就可以多支持pdf格式 doc格式的文件,引入ocr又可以支持图片转文本,再搞个爬虫程序,又可以基于url引入知识库了,然后应用可以自行集成这些内容转换、embedding计算、向量数据库,设置可以设置LLM配置,就完成了一套本地的知识库问答系统。例如AnythingLLM,也有对检索的流程进行优化的,比如网易的Qanything是先检索,然后再用rerank算法从初筛结果中,再选出更精确相关的chunks。
演示AnythingLLM,下载双击即可安装,然后进行配置 =》导入知识库 =》本地知识问答
第一步:安装向量数据库qdrant,不用AnythingLLM内置的LanceDB的原因是之前有bug导致查询失败。
直接从github下载最新的二进制文件即可,如果想要webui还需要单独下载webui,也是从github下载zip文件,加压到前面qdrant下载完成后的./static目录下(需自己新建)即可。
双击qdrant.exe运行数据库,打开http://127.0.0.1:6333/dashboard就可以看到了
第二步:准备SiliconCloud账号,这是国内的平台用手机号即可完成注册,我们要使用这个平台提供的免费的embedding和chat接口。
第三步:官网下载AnythingLLM安装,然后进行配置,这里把可能要输入的几个文本,写在这https://api.siliconflow.cn/v1 Qwen/Qwen2.5-7B-Instruct BAAI/bge-m3
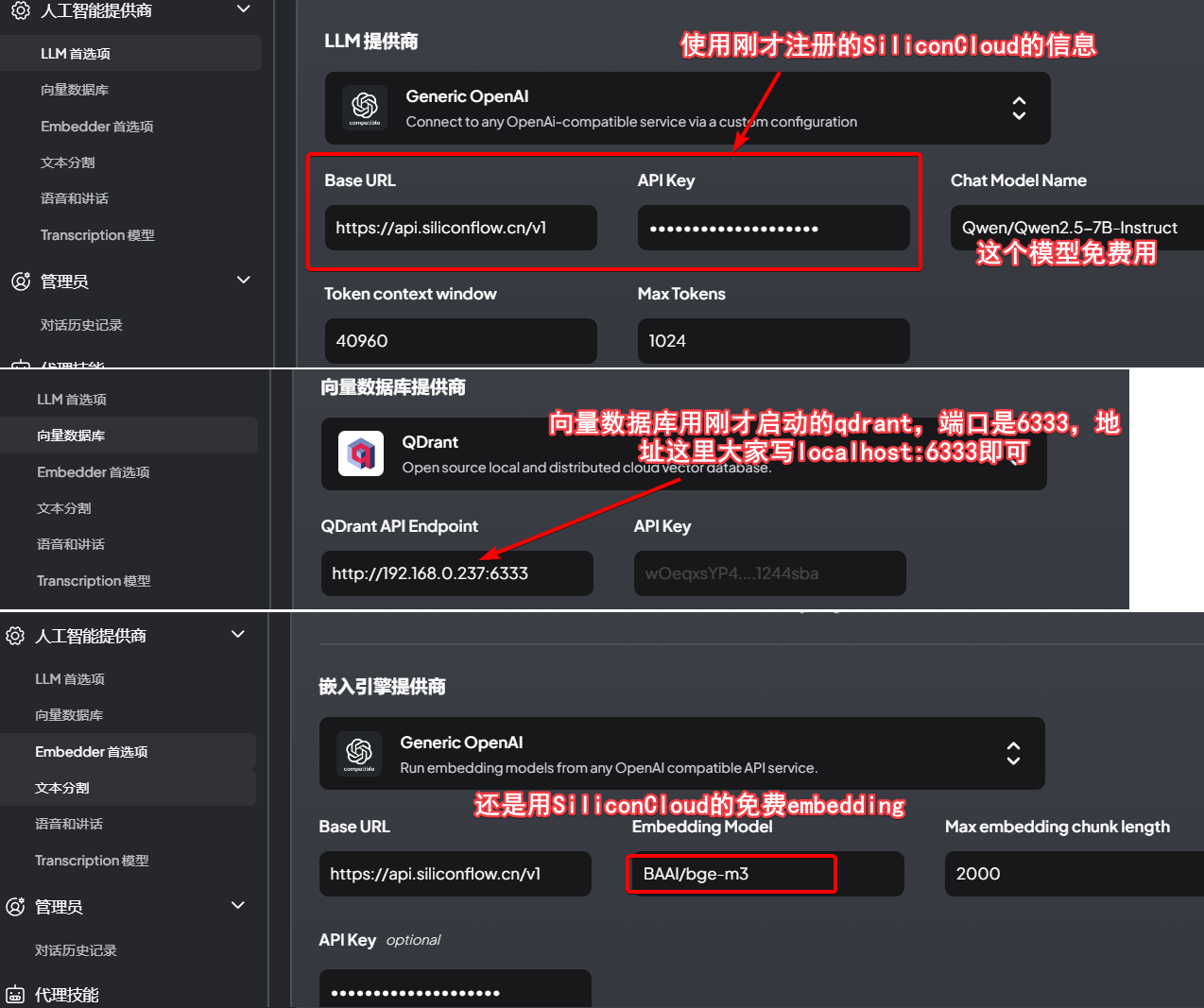
新建工作区“魁拔”,问他魁拔多久诞生一次等问题,可以看到答案完全错误(看过魁拔的应该知道每隔333年诞生一次魁拔)。魁拔之书是讲述四代魁拔迷麟的故事,从这里下载的,下载后注意重新用utf-8编码把文件保存。
7 微调与相关工具
微调(Fine-tuning)是直接用自己的数据,对已有的模型进行进一步的训练,给模型增加"思想钢印",让模型了解我们提供的业务自身数据。比如上面RAG中提到的知识库人物传记这本书,我们直接作为训练数据,来微调模型,这样模型自己就有了这本书的内容,就不需要作为prompt再提供了。因而微调看上去是解决,业务内部问题的最好方法。
解决业务问题,一般就是通过prompt提供上下文,或者微调,而prompt长度限制等原因又衍生了RAG这种手段。所以本质上就是两种手段,要么给模型微调,要么prompt。prompt的优势在于非常灵活,模型可以随便换,业务数据也可以更新,但是缺点是每次需要携带,每次都是传入数据片段chunks模型没有全局的理解这些数据。微调就正好相反,他是全局理解了业务数据的,但是不太灵活,如果业务数据变化,需要重新微调,底座模型变化也需要重新微调。
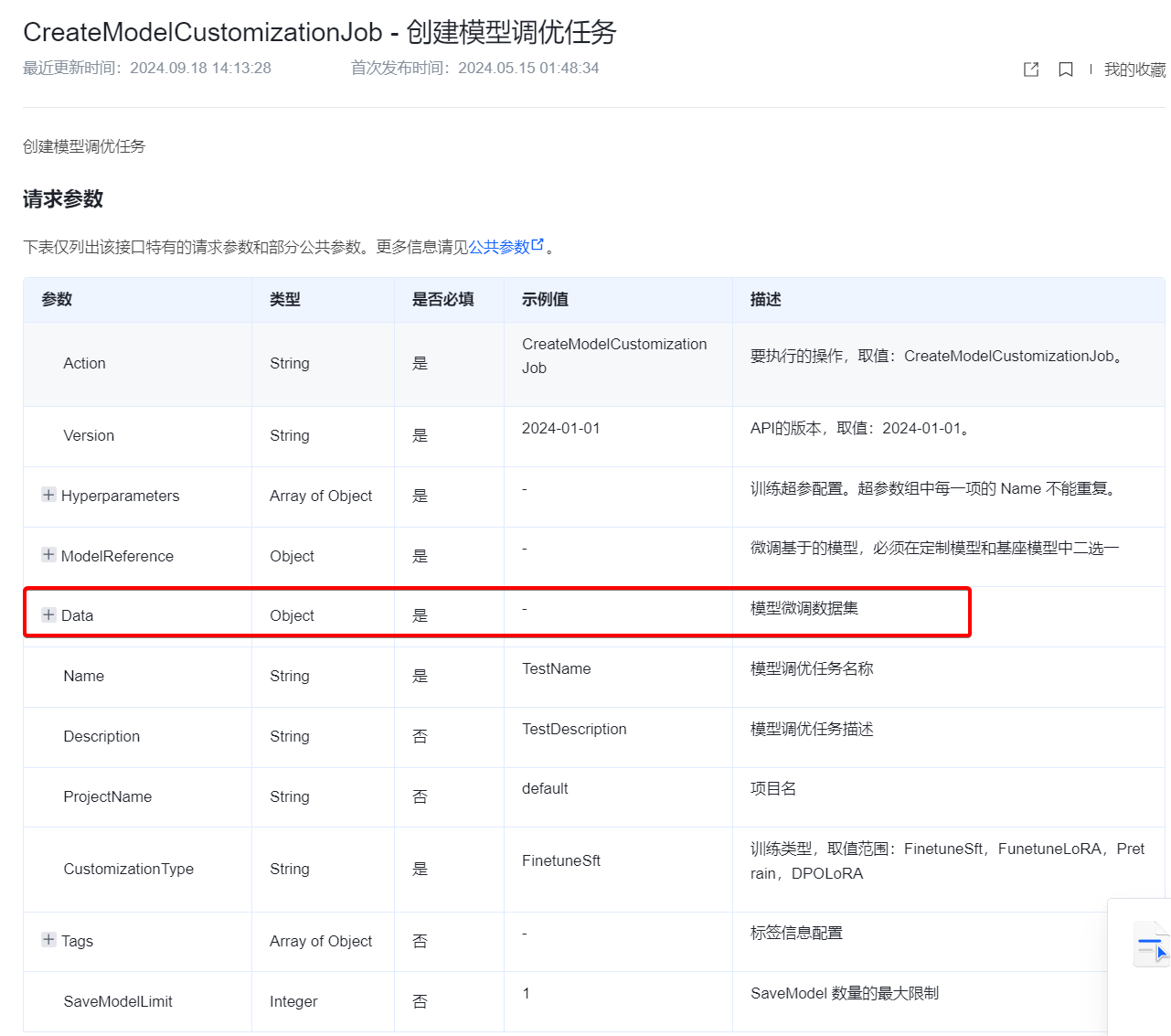
一般来说,各个闭源的模型供应商会提供微调的接口或者页面,例如openai,但是国内用不了openai,可以看一下字节的豆包的流程,大概就是基于底座模型和自己的数据进行微调,得到一个新的模型,创建一个新模型的接入点,然后就可以使用新的模型了。不过我没有购买这些服务,这里只能给大家看下微调的接口参数如下。
而我们自己可以对一些开源的模型进行微调,来体验微调的效果,例如llama qwen等开源模型都是可以拿来微调的,微调的方式和工具也非常多。比如使用unsloth库、huggingface上自带的autotrain、最简单易用的llama-factory等。一般来说,如果你家境富裕,有16g显存或者以上的显卡的话,建议你本地来体验一下微调。如果你家境贫寒的话,可以使用一些在线平台来体验微调,例如谷歌的colab每天有免费的显卡使用额度大概能微调个1次,也可以按量付费,也花不了几块钱。也可以使用hugggingface上的autotrain配合购买上面的显卡额度来进行微调,价格和colab大差不差。当然还有国内的魔塔平台,也是不错的,注册新用户有优惠,配合阿里云的机器优惠非常的划算,基本体验阶段就不花钱。
使用llama-factory在本地进行微调(虽然名字有llama,但其实和llama模型无关,可以微调各种模型),这个工具对windows支持很好,而且可以直接web界面操作,对于新手是非常友好的。这是官方的repo,安装方式也在官方readme中提到了,而且也提供了详细的入门教程,关于安装这里不在赘述。我们直接在本地启动:
# linux/mac下set改为export来设置环境变量
$ set USE_MODELSCOPE_HUB=1 # 因为huggingface被墙,所以从魔塔下载,将这个值设置为1
$ set HF_ENDPOINT=https://hf-mirror.com # 也是因为hg被墙,将hg入口设置为镜像地址,主要是为了除了模型下载另外一些需要hg同步信息的操作
$ llamafactory-cli.exe webui # 启动webui,前面安装完成llamafactory-cli会自动设置到全局PATH中可调用
启动完成,会自动打开http://localhost:7860,接下来我们准备10条训练数据如下,这十条数据都是在说魁拔每隔333年诞生,因为如果是单条数据的话很难有好的训练效果。
[
{
"instruction": "魁拔多少年复活一次。",
"input": "",
"output": "根据《魁拔之书》的记载,魁拔每隔333年复活一次。"
},
{
"instruction": "魁拔诞生的周期。",
"input": "",
"output": "魁拔每隔333年诞生,所以诞生周期是333年。"
},
{
"instruction": "魁拔复活的周期。",
"input": "",
"output": "魁拔每隔333年诞生,所以魁拔复活周期是333年。"
},
{
"instruction": "魁拔是谁。",
"input": "",
"output": "魁拔是《魁拔之书》中的一个角色,每隔333年诞生一次的生物。"
},
{
"instruction": "计算魁拔下一次复活的时间,假设上次复活时间是910年。",
"input": "910",
"output": "如果魁拔上次在910年复活,那么下一次复活将在910+333年,也就是1243年。"
},
{
"instruction": "根据《魁拔之书》的记载,魁拔每隔多少年复活一次",
"input": "",
"output": "根据《魁拔之书》的记载,魁拔每隔333年复活一次。"
},
{
"instruction": "魁拔复活的时间间隔是多少?",
"input": "",
"output": "333年"
},
{
"instruction": "如果魁拔上一次复活时间是1800年,魁拔下一次复活的时间?",
"input": "",
"output": "魁拔每隔333年诞生,所以下一次复活是2133年。"
},
{
"instruction": "魁拔诞生要隔多少年?",
"input": "",
"output": "333年"
},
{
"instruction": "魁拔复活要隔多少年?",
"input": "",
"output": "333年"
}
]
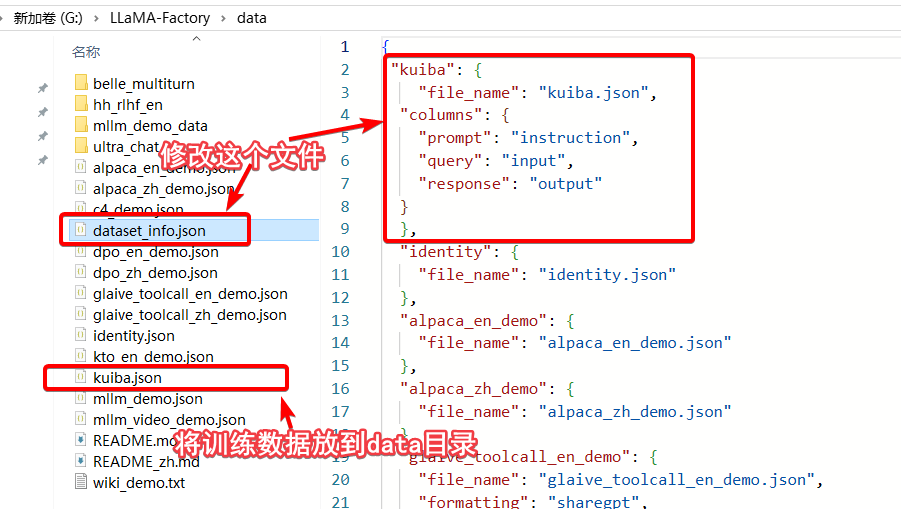
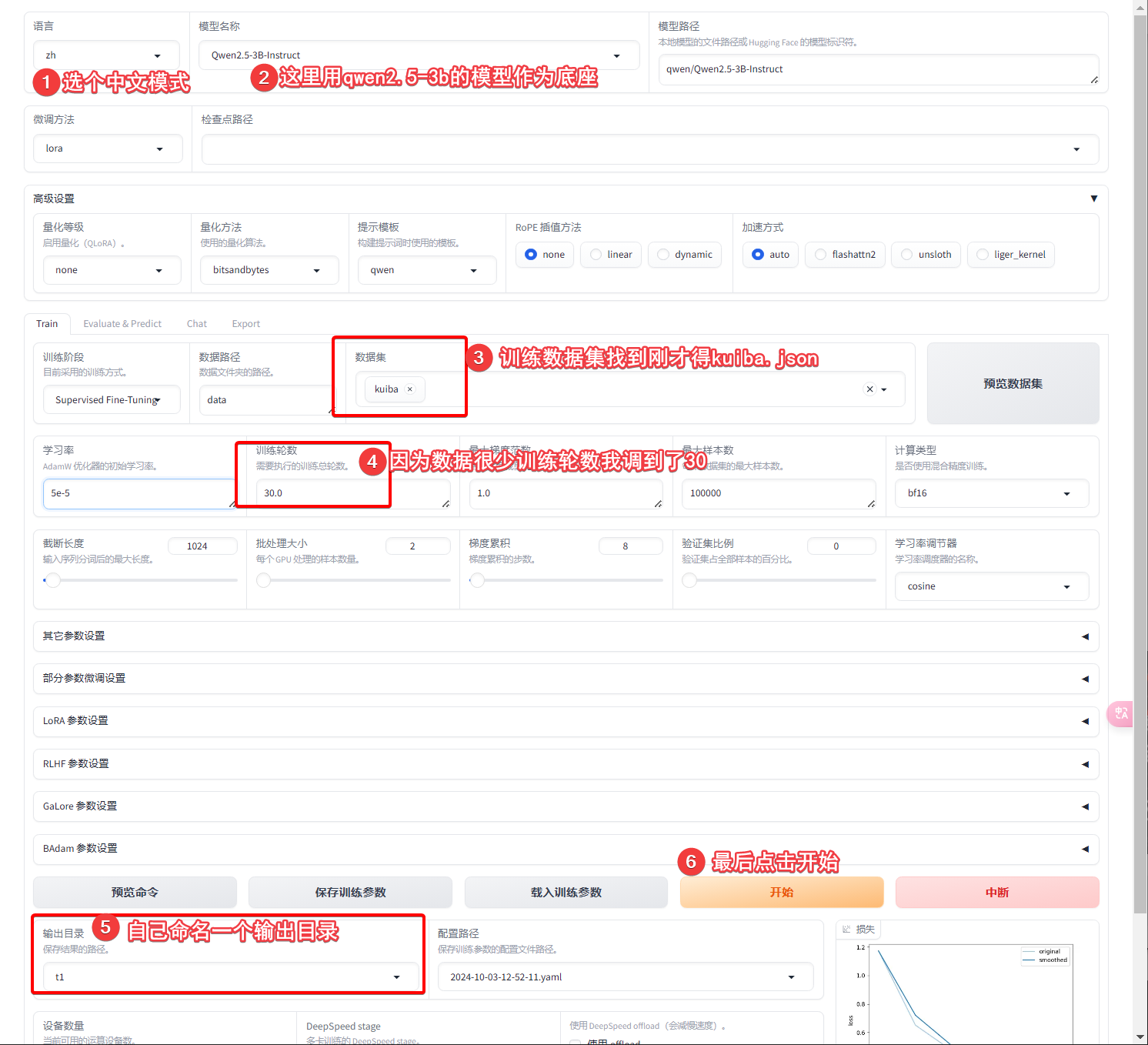
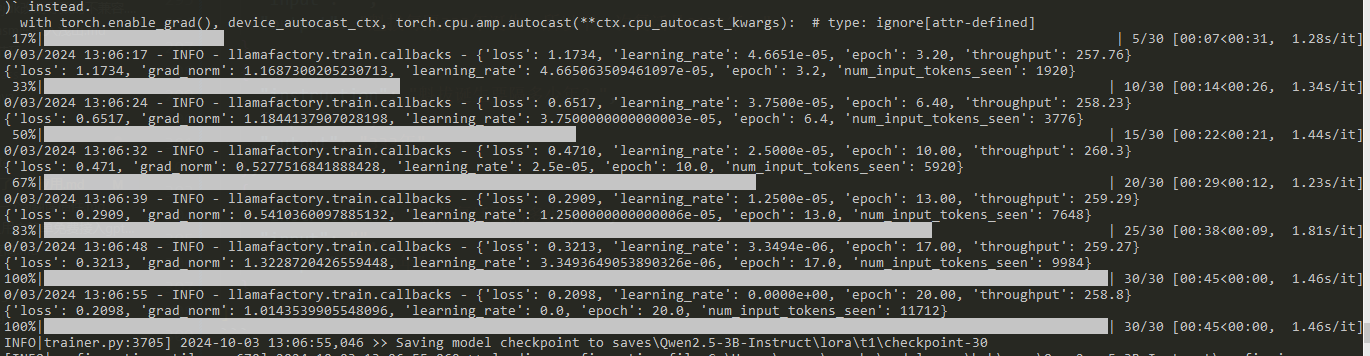
训练开始后,会自动从魔塔先下载底座模型,也就是qwen2.5-3b-instruct,速度还是很快的我这里的速度是30+M/s,下载完之后会开始训练,训练进度也很快,我这里是3090显卡,一两分钟就结束了,当然主要也是因为数据集非常小。训练过程中大概占用了8G-9G显存的样子。
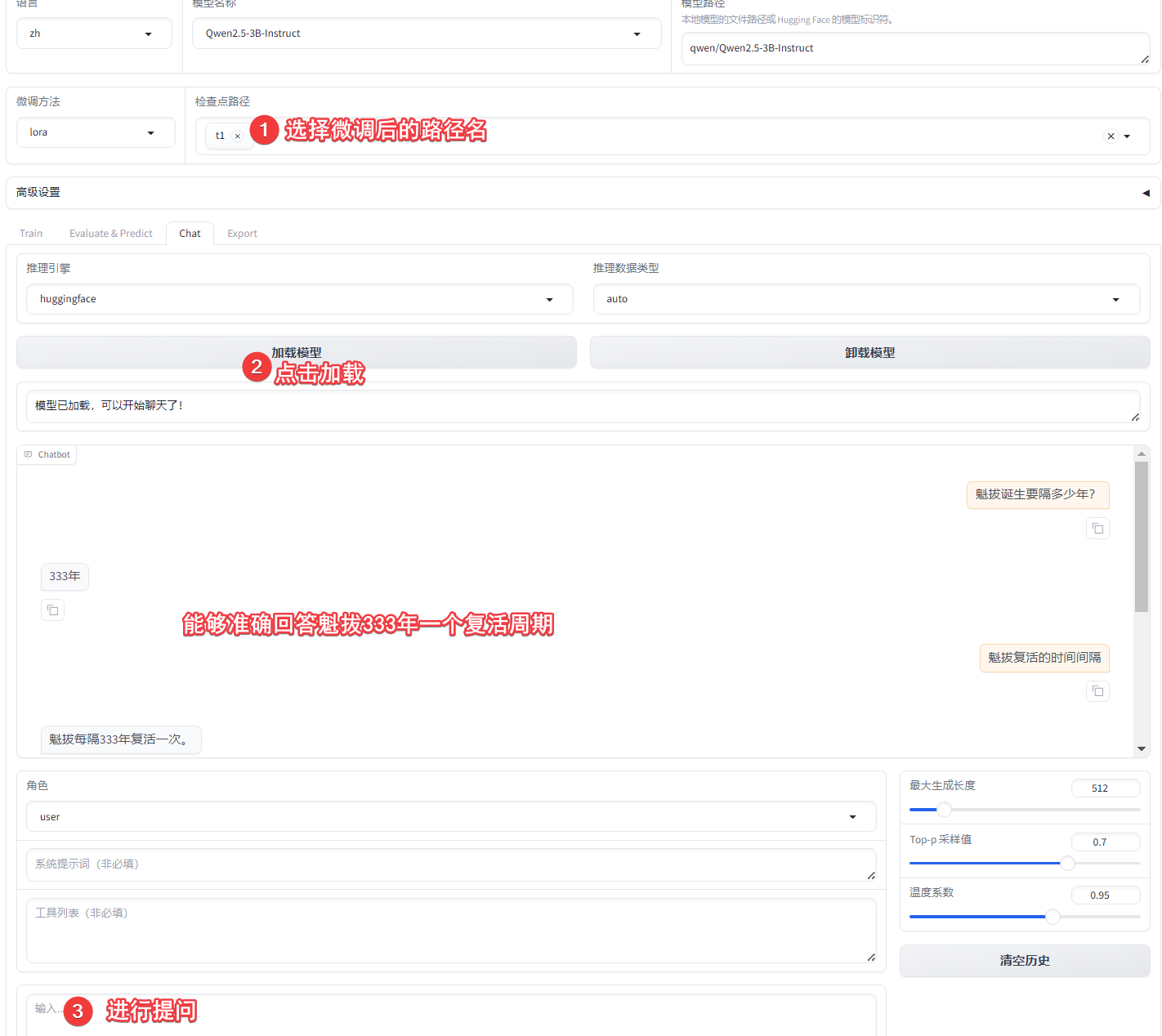
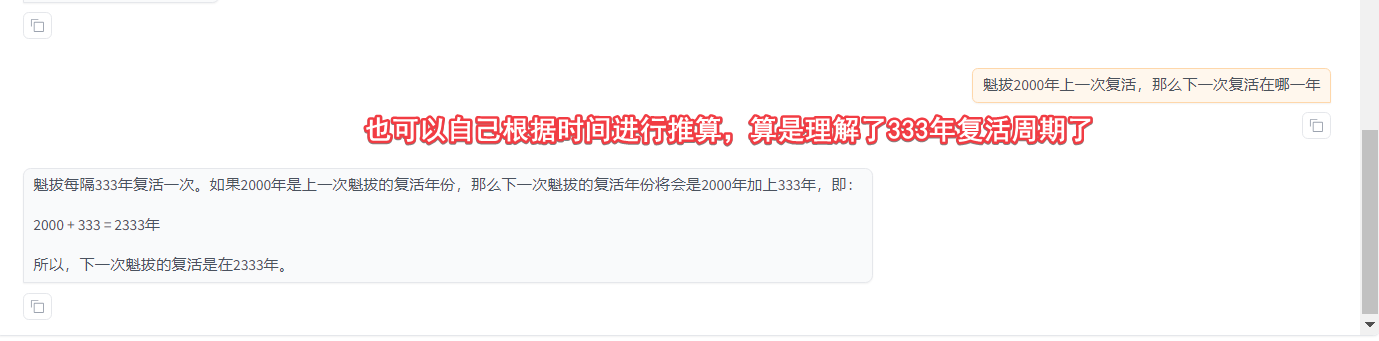
这里就可以对比在微调之前,该问题的效果:
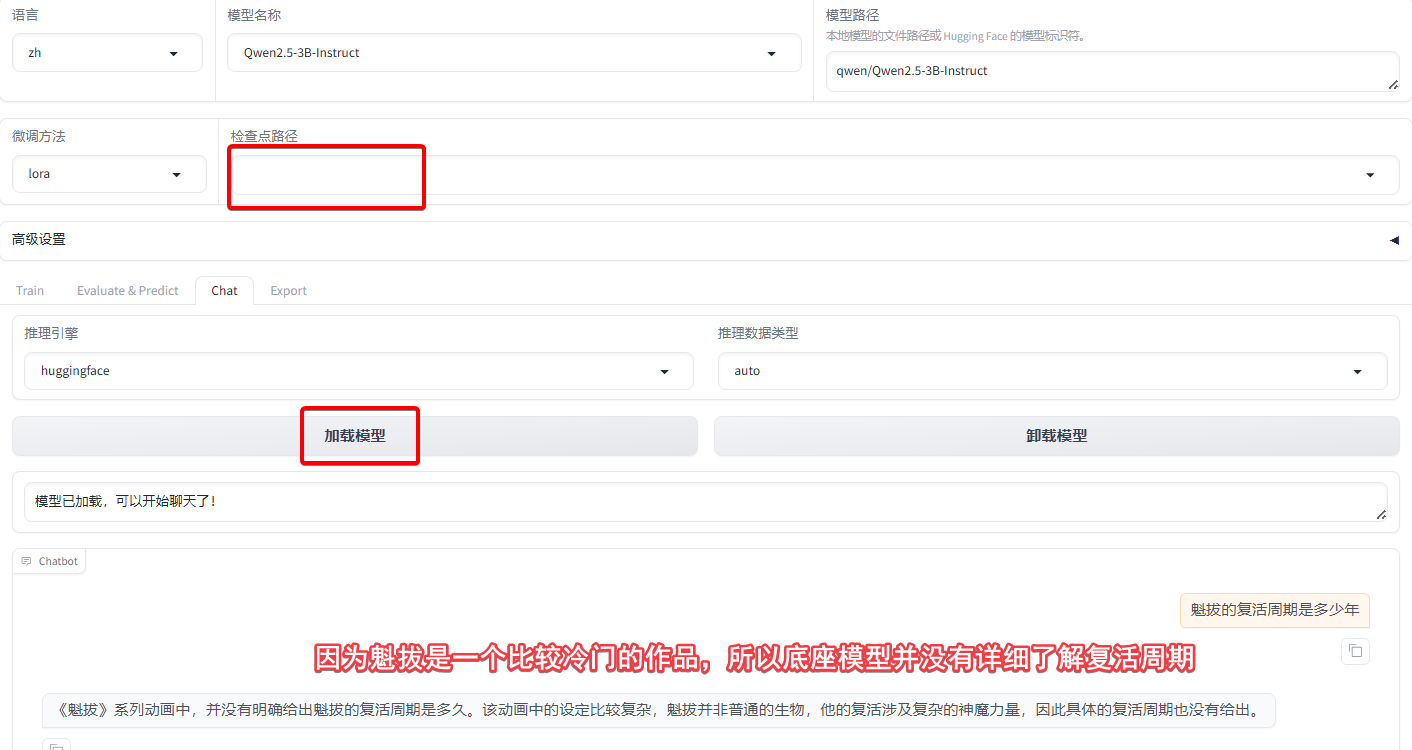
小结:微调实际的效果,跟微调的方式、参数、训练数据集还有底座模型都有关,比较不可控。需要花时间去进行炼丹,人力和机器成本都比较高。一般来说当需要某个领域的知识增强的时候可以使用微调,对于大多数情况来说,微调的投入产出比并不划算。因而我们会发现,RAG在业务场景中使用的远比微调要多。
8 前沿技术
提示词缓存:claude模型中开始引入了,提示词缓存(prompt cache),对于一些非常长的设定类的提示词,服务端可以进行缓存,降低成本。2024-10-01openai开发者大会,也引入了改功能。这项功能对用户来说,不需要做任何调整,服务端自动支持的。
实时语音交互:gpt-4o-realtim-preview模型中支持,可以与大模型进行语音的实时对话,比asr tts llm缝合的效果好很多,尤其是延时非常低。其他厂商暂未支持。
蒸馏:将大模型蒸馏成小模型。例如可以从gpt-4o这样的大模型中,通过特定领域的问题提问得到的答案,再将这些QA数据在4o-mini模型上微调得到尺寸小很多的模型,但同时能解决特定领域的问题。2024-10-01openai开发者大会上,公布了更加简单易用的蒸馏接口和方案。
视觉微调:2024-10-01openai开发者大会上,公布了图像微调,效果显著。
9 其他常见ai应用盘点
有了上面的基础知识,我们就来盘点一下常见的一些ai应用的实现原理了。
注意:
- 上面提到的
chat类应用、知识库应用、向量db已经介绍过了,这里不再重复介绍; - 生成图片和视频的应用,我没咋用过,这里也不会涉及。
9.1 IDE中的自动补全
在IDE中,我们可以在代码中输入一些关键词,有些插件就能自动往下续写,这就是自动补全的能力。

我个人体验过以下插件,列出了个人一些看法,其中对于效果,一般提示内容比较相关,代码无明显错误,并且有异常边界处理,就认为是不错。毕竟这部分提示更多的还是给用户提供一些参考,而不是完全的自动生成代码。
| 插件 | 效果 | 套餐形式 | 价格(/月) | 评语 | 推荐指数 |
|---|---|---|---|---|---|
| tabnine | 免费版凑活用,中文续写有乱码情况 | 免费或付费套餐 | $12 | 赛道老玩家 | 3 |
| aws whisperer | 效果不错 | 个人免费 | 0 | 隔两天就需要重新登录,心态爆炸 | 2 |
| codium | 免费版没有补全提示 | 免费或付费套餐 | $10 | 国服网络有问题啊 | 2 |
| supermaven | 效果不错 | 补全是完全免费 | 0 | YYDS | 5 |
| continue | 纯调ai接口,反应慢 | 开源软件自己配置LLM供应商的 | - | 全走ai接口算下来每月费用也不低 | 1 |
| baidu comate | 效果不错 | 个人免费,企业付费 | 0 | 挺不错的,不知道代码会不会被利用 | 5 |
| tongyi lingma | 效果不错 | 个人免费 | 0 | 我个人觉得比百度好用一丢丢,不是指ai生成而是使用方式 | 5 |
这类补全工具,一般会有本地的数据或者模型,可以快速提示,也会有远程的AI接口进行支持,所以总体体验上,还是不错的,如果是个人用户那么通义灵码就很不错,他不仅有智能补全,还有智能代码问答,包含了开源continue插件的所有功能,只不过使用默认自己的千问模型,后者则是开源自己指定LLM供应商,要花钱。但是通义有个问题就是,他并没有对企业免费,这样可能在公司有偷着用被发现的风险,那这样看下来supermaven可能是更好的选择,但supermaven代码问答能力几乎没有。
我们来看一下工作原理,配置charles代理来进行抓包,使用vscode来观察,这是continue插件配置了openrouter llm provider时候,抓包得到的代码提示的请求内容。可以看到有个非常长的prompt,上来教了模型如何填充代码,并且还给出了一个例子,输入输出应该是什么样等等信息,最后才说当前给的代码是什么,然后让大模型进行填充,这里关注下stop字段。

这种每打一个字母,都会请求一次LLM模型的方式效率很低,因为大模型一般反应都比较慢,而我们打字又比较快,带来的体验就很差,所以大多数代码补全都是本地和LLM结合的方式,其他几个插件都是混合方式实现的。
9.2 IDE中的代码问答
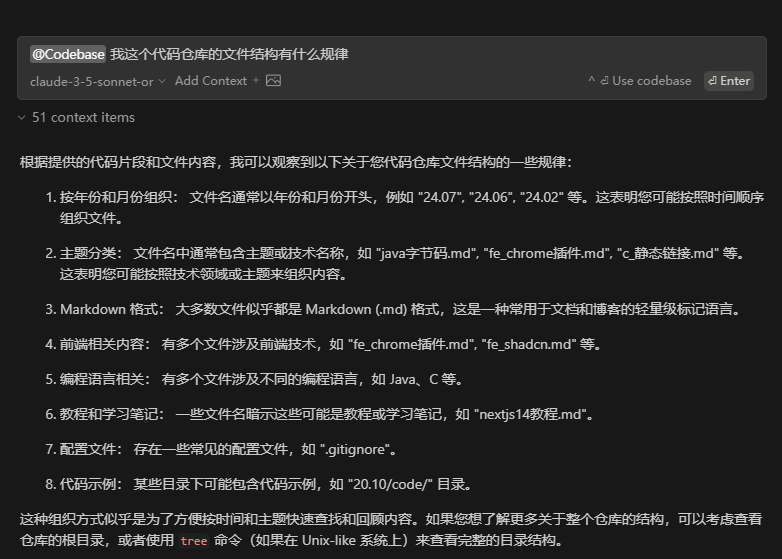
与普通的chat不同,IDE中的代码问答,一般需要支持选中代码后AI解释/单测/注释等;单独的聊天窗口,可以根据整个项目目录下的文件进行问题回答。例如continue中询问当前目录结构规律,他是能把相关信息给到模型的。
| 插件 | 效果 | 套餐形式 | 价格(/月) | 评语 | 推荐指数 |
|---|---|---|---|---|---|
| baidu comate | 效果不错 | 个人免费,企业付费 | 0 | 中文指令有点出戏 | 4。5 |
| tongyi lingma | 效果不错 | 个人免费 | 0 | 插件不错但是模型能力比claude还是差一些 | 4.5 |
| continue | 配置claude模型和openai的embedding,顶呱呱 | 开源软件自己配置LLM供应商的 | - | 效果是好,但是模型接口都要自己花钱 | 4.5 |
工作原理很简单,就是把关联的上下文文件内容直接放到prompt中传到chat接口。
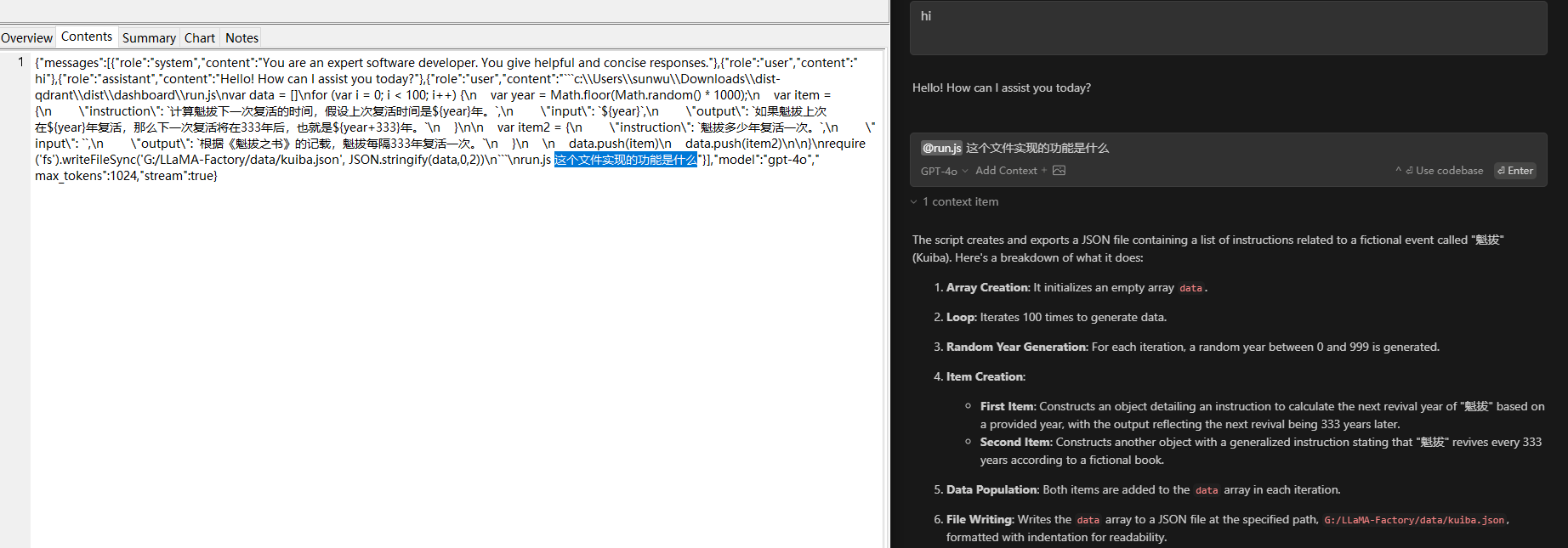
如果是@整个项目空间然后进行一些提问,整个流程则为RAG那一套,即把提问进行向量化,找到相似度最高的文件,把这些文件作为上下文都传给chat,如下问题找到了8个相关的文件,作为“参考”,其实就是作为提问的上下文。
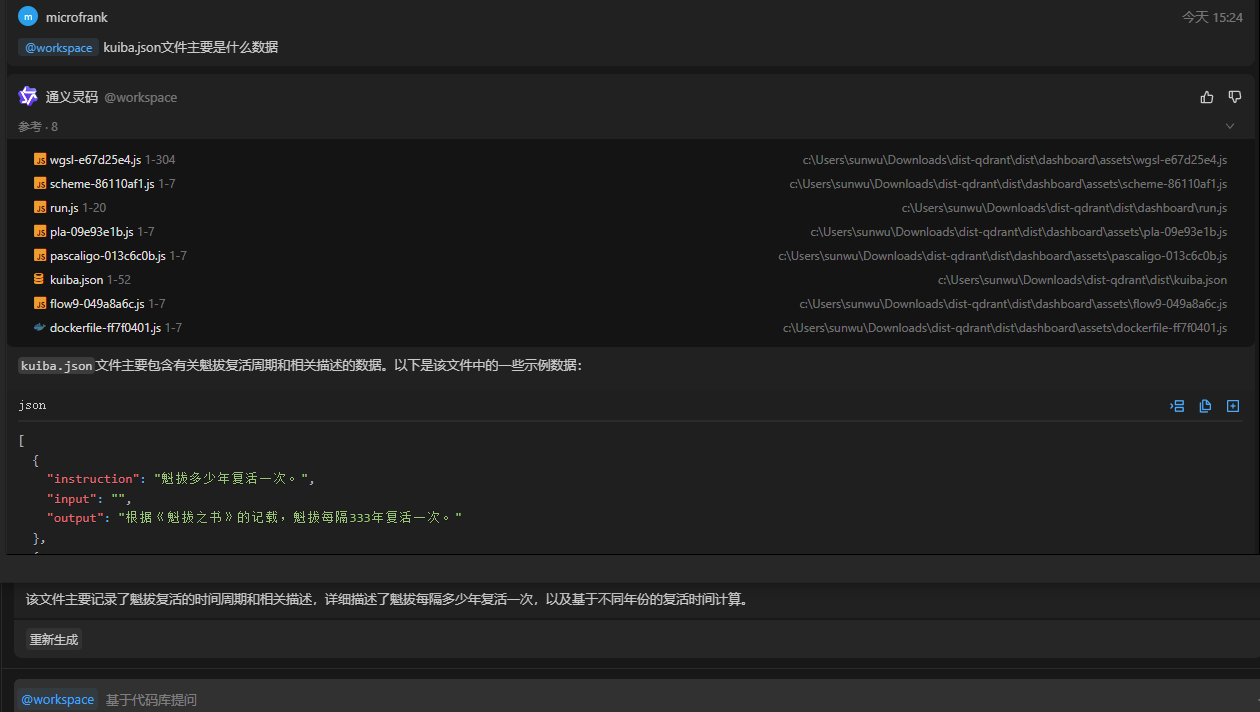
9.3 IDE中的composer
composer是cursor IDE中的叫法,实际上是通过描述,让AI帮我们生成项目代码,并生成需要的目录结构和文件,并且可以follow话题,对项目进行代码整改。他与普通的代码问答不同,能够直接修改和创建文件,也能够基于当前的项目文件内容,进行整改。因而有着更高的实用性。
目前的产品以cursor为主,$20/m比较贵,其他的ide如void editor还在beta阶段。目前具有这项能力的还有vscode插件claude-dev(5.8Kstar)以及命令行工具aider(19.8Kstar)。
以claude-dev为例:
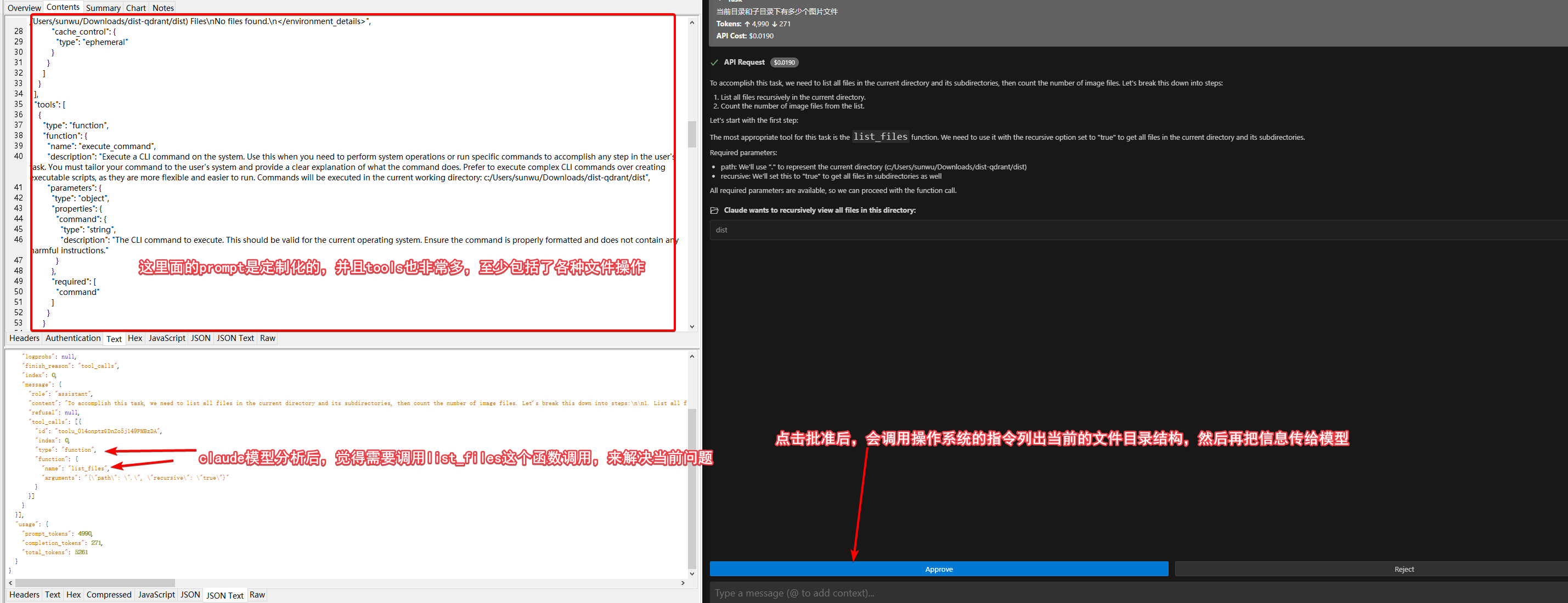
具体的请求参数我列到这里
上面只是一个函数调用的例子,我们让claude-dev写功能的时候,他也会申请文件的写权限,创建或修改文件内容。claude-dev和aider都是开源的,不收费,自己设置模型按量使用的。而cursor每个月$20,是比较贵的。
9.4 AI实现前端代码
我个人用过vercel的v0,但是效果嘛,只能说简单的还行,但是简单的claude-dev也能搞定,v0还要付费。目前没有觉得v0有不可取代的优势。
9.5 记忆存储应用
大模型是无状态的,上下文都是通过prompt携带的,那如何解决一个不吃香菜的用户,每次问菜谱的时候,LLM都要重新去了解用户吃不吃香菜的问题呢?那就是记忆了,记忆这个东西算是一种辅助,作用不是特别大。目前有一些开源实现mem0等。
这些工具的原理和介绍,在参考这里,个人感觉是并不复杂的实现,而且业务收益也不算大。
9.6 AI流程平台
一个ai应用往往需要多个流程,比如大模型调用、函数调用、函数调用完了再大模型调用、知识库、记忆等,这些组件就像是一个流程图的各个节点,所以就有了这样一类工具或者叫平台,来整合这些组件,实现一个完整的ai应用。比如开源的langchain dify等,还有字节的coze。
那我们就以coze为例,基本的bot搭建长这样。
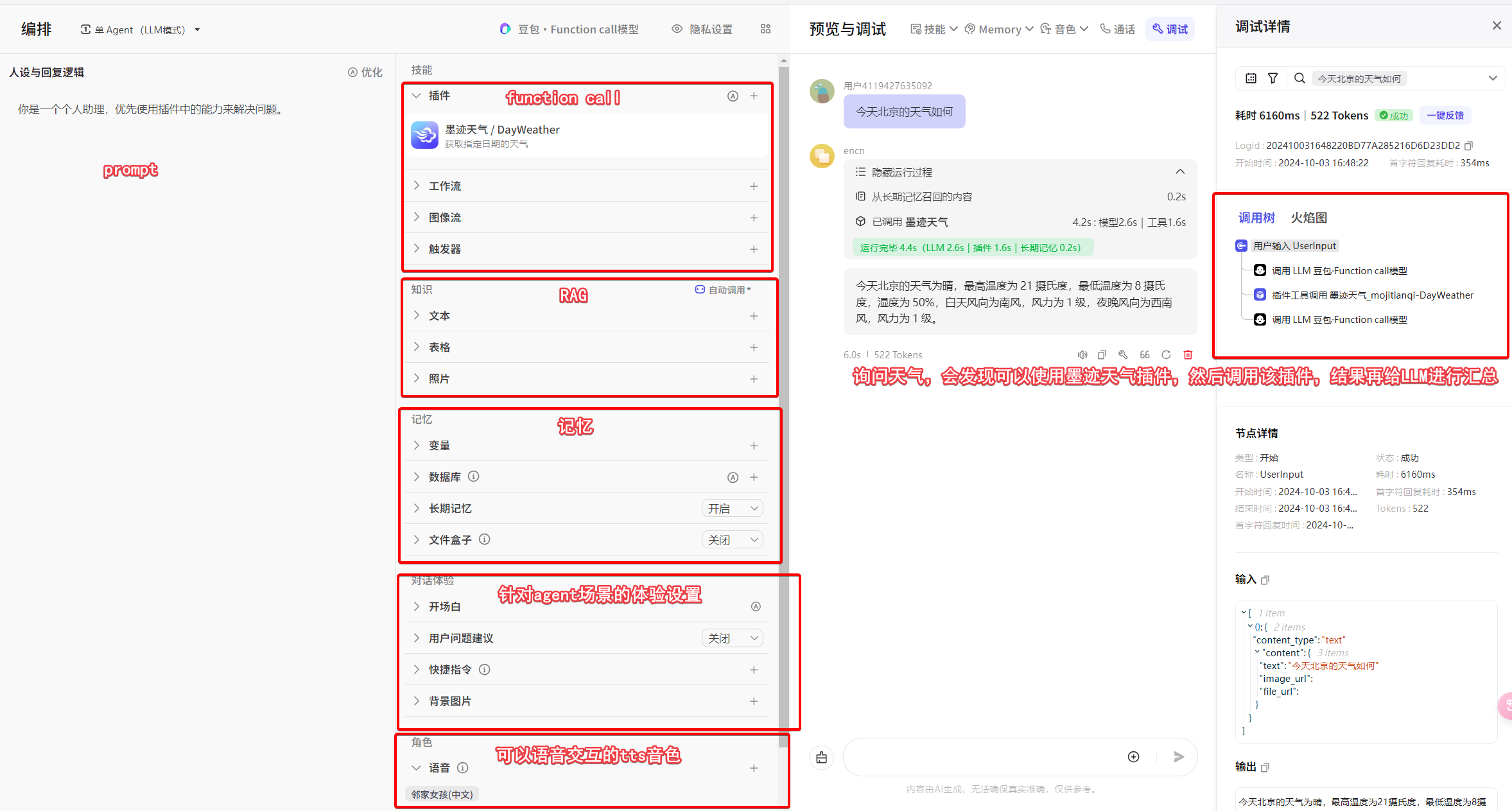
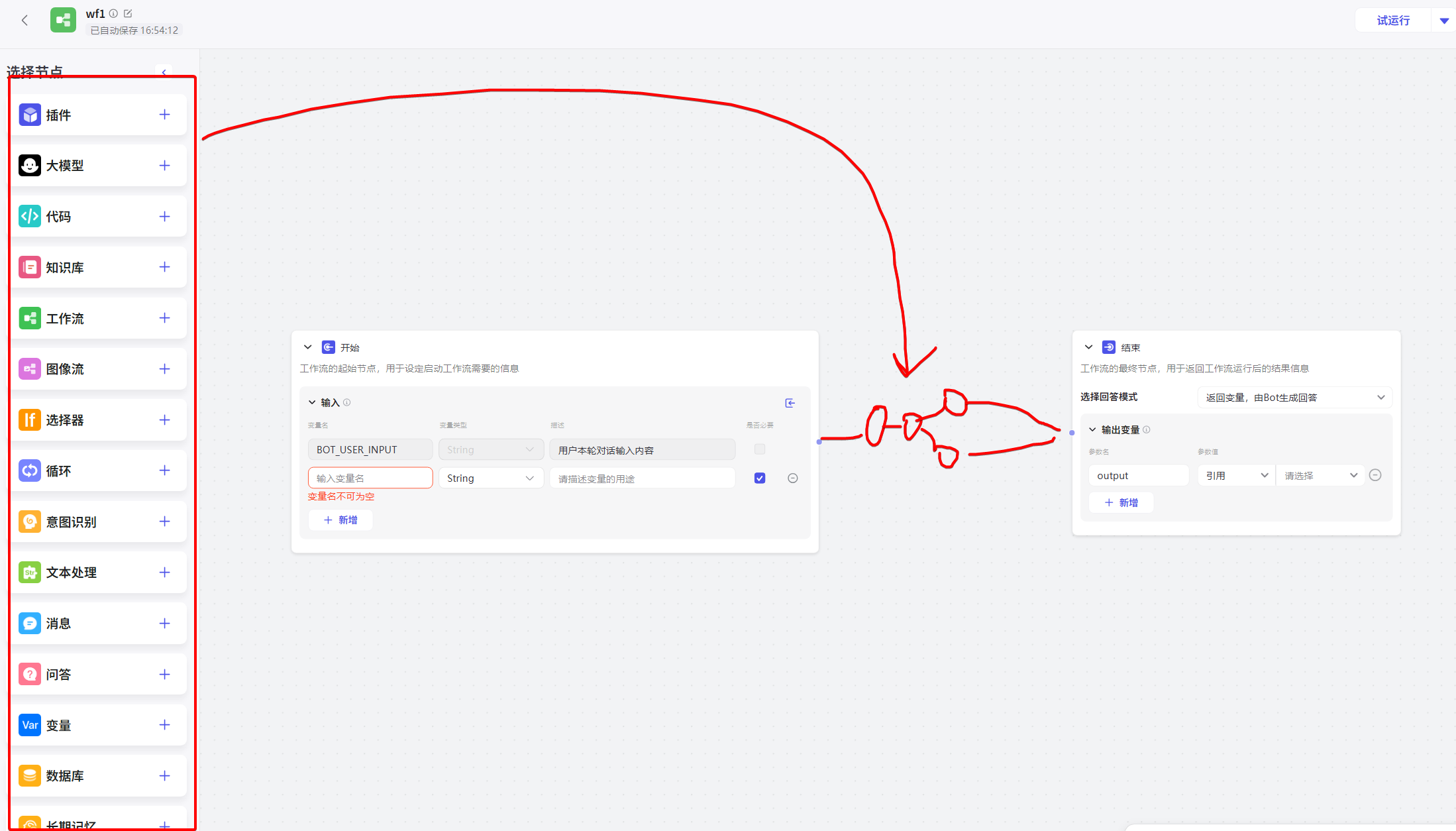
这里面技能中有个扩展性非常强的工作流,可以自由编排,例如我们搭建一个对话机器人,想要获取用户是否有买xx产品的意向,意向的等级分为哪些,当前对话分析出用户意向等级是多少,把上下文传给LLM分析,就可以得出这些结论。然后根据不同的意向我们还要往下进行不同的处理,此外这些对话中分析出来的数据也需要通过接口回推给我们系统的数据库,那这里就可以加一个代码节点,可以写nodejs程序,完成数据推送到业务自己的系统。等等,总之工作流的想象空间很大。
9.7 办公文稿类
文稿类型我用的倒不是很多,但是也是一个重要的赛道,比如帮写ppt的gamma,帮写笔记的notion ai,这类我的感觉是没啥用,可能我写作水平太差了,notion给提示的都不是很满意,而且感觉他还非常贵。
9.8 小结
上面列出了一些,我使用和了解过的一些ai工具,以及他们的工作原理,如果后续遇到新的ai应用,不妨也在脑子里想一想,他大概是怎么实现的吧。