1 简介
词法分析是编译器或解释器的基础步骤,用于将源代码转换为tokens,下面是一个词法分析的例子:
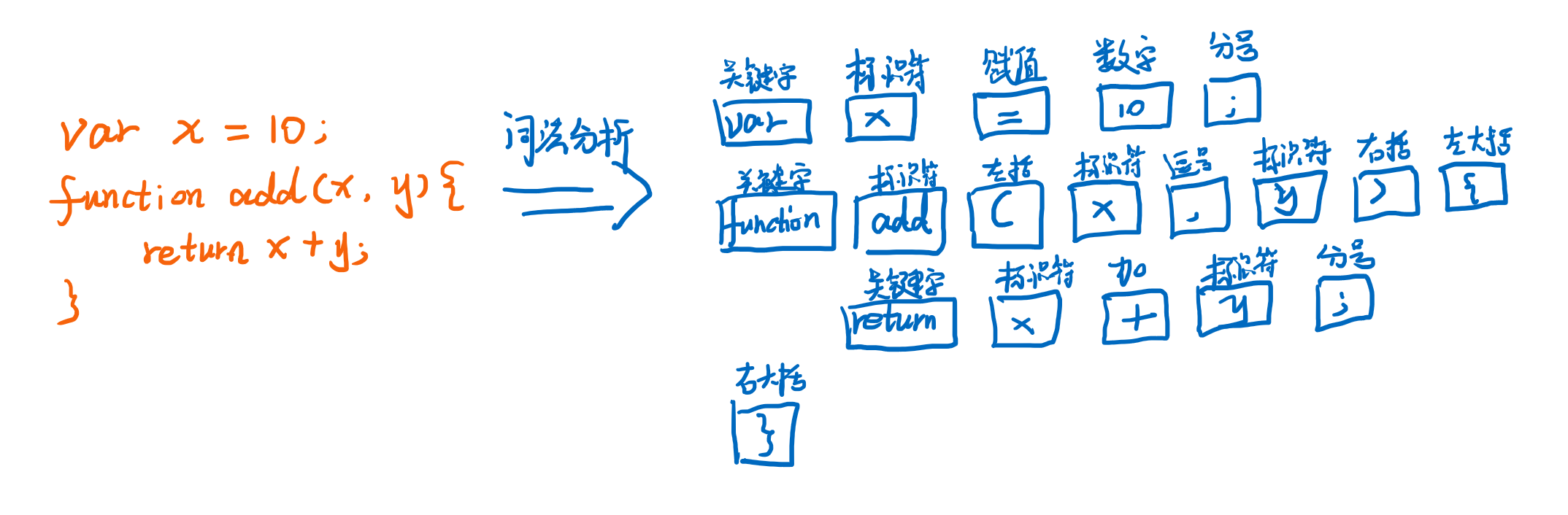
我们可以看到词法分析这个过程的入参是源码字符串,而出参就是一个token数组,token就是一个简单的对象,包含了类型和对应的字面量,比如图中var这个token,他的类型就是关键字,字面量就是var。
常见的词法分析方式有:
- 正则表达式
- 逐个字符解析(有限状态机)
- 使用现成的词法分析工具(如
lex)
2 正则表达式
首先说正则表达式或者说部分环节借助正则表达的方式:一般适用于简单的词法分析,比如说写一个四则运算的解析器,输入的内容只有数字空格四则符号,那么下面这个代码就可以很好匹配。
function lex(input) {
input = input.trim()
let tokens = []
while (input.length) {
let match;
if (match = input.match(/^\d+/)) {
tokens.push({type: 'number', value: match[0]})
} else if (match = input.match(/^[+\-*/]/)) {
tokens.push({type: 'operator', value: match[0]})
} else { throw new Error('unexpected input') }
input = input.slice(match[0].length).trim()
}
return tokens
}
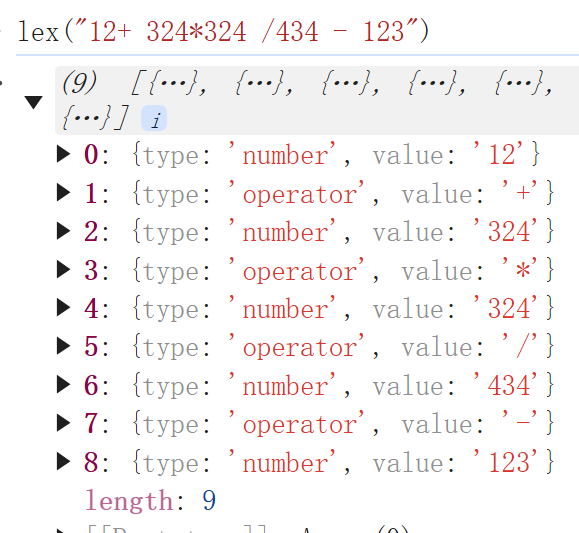
这里为了演示方便直接用了js在浏览器里运行,可以看到对于正常的四则运算输入可以很好的进行词法分析,代码的运行效率不算高,因为正则匹配性能的缘故,但是代码非常简洁,很适合简单的语法场景,比如自定义的简单规则引擎,再比如简单的sql解析器。但是如果要解析完整或基础的js语法,因为出现的可能性太多,不同可能性的分支匹配起来就会非常复杂,这时候正则表达式就不太适用了。比如单是解释简介图中的赋值和函数,正则表达式都不太好写了。
3 逐个字符解析
逐个字符解析,是最容易想到,也是最常见的一种解析方式,他适用于所有场景。和人看代码时候的拆分思路是一致的。例如对于上面四则运算的解析,可以这样:
function lex(input) {
let tokens = []
let position = 0
while (position < input.length) {
switch (input[position]) {
case '+':
case '-':
case '*':
case '/':
tokens.push({type: 'operator', value: input[position]})
position++
break
case ' ':
position++
break
default:
let start = position
while (input[position] >= '0' && input[position] <= '9') {
position++
}
if (start == position) {
throw new Error('unexpected input')
}
tokens.push({type: 'number', value: input.substring(start, position)})
}
}
return tokens
}
代码比正则多一点,但是复杂程度或者理解难度上比正则还要更简单一些,这个思路就是逐个字符解析,遇到加减乘除,则直接解析为四则操作符;遇到空格则直接跳过,因为空格是没有效果的;然后其他情况则是数字,数字的解析方式就是一直解析到不是数字为止,然后把解析到的数字字符串作为token的value。当然如果出现了不是数字的情况,直接抛出错误就可以了。这个思路虽然很简单但是却很有借鉴意义,我们接下来用逐字解析的方法来解析第一部分中的代码:
var x = 10;
function add(x, y) {
return x + y;
}
我们先来定义token的类型吧,当然有些没涉及到的符号比如. [ /等等,我们这里还没有定义,不着急,这个例子中没有,后续会再补充。
// 赋值 左括号 右括号 左大括号 右大括号 加号 分号 逗号
const ASSIGN = 'ASSIGN', LPAREN = 'LPAREN', RPAREN = 'RPAREN', LBRACE = 'LBRACE', RBRACE = 'RBRACE', PLUS = 'PLUS', SEMICOLON = 'SEMICOLON', COMMA = 'COMMA';
// var 标识符 数字 函数
const VAR = 'VAR', IDENTIFIER = 'IDENTIFIER', NUMBER = 'NUMBER', FUNCTION = 'FUNCTION';
像四则运算一样,我们先考虑那些单个字符就需要独立解析的,这段代码中涉及到的有= ( ) { } + , ;,当遇到这些字符的时候直接就构造一个token,这是一种贪心的处理。出了特殊的字符和空格之外,剩下的就是字母和数字了,对于数字来说同样和四则的例子一样进行数字的识别,而对于字母,则是识别出一个完整的单词,直到下一个字符不是字母或数字的时候结束。思路很简单:
function lex(input) {
let tokens = []
let position = 0
while (position < input.length) {
switch (input[position]) {
// 有特殊作用的单个字符
case '=':
tokens.push({type: ASSIGN, value: '='}); position++; break;
case '(':
tokens.push({type: LPAREN, value: '('}); position++; break;
case ')':
tokens.push({type: RPAREN, value: ')'}); position++; break;
case '{':
tokens.push({type: LBRACE, value: '{'}); position++; break;
case '}':
tokens.push({type: RBRACE, value: '}'}); position++; break;
case '+':
tokens.push({type: PLUS, value: '+'}); position++; break;
case ';':
tokens.push({type: SEMICOLON, value: ';'}); position++; break;
case ',':
tokens.push({type: COMMA, value: ','}); position++; break;
// 空格 tab 换行跳过即可,不需要解析
case ' ':
case '\t':
case '\r':
case '\n':
position++; break;
// 剩下数字或字母
default:
let start = position
// 数字类型
while (input[position] >= '0' && input[position] <= '9') {
position++
}
if (start != position) {
tokens.push({type: NUMBER, value: input.substring(start, position)})
continue;
}
// 字母类型
//// 首字符必须为字母下划线,后面的可以是数字
if (input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_') {
do {
position++
} while (input[position] >= '0' && input[position] <= '9' || input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_')
tokens.push({type: IDENTIFIER, value: input.substring(start, position)})
continue;
}
// 不认识的字符抛出异常
throw new Error('unexpected input');
}
}
return tokens
}

到这一步是不是信心大增了,原来解析这样一段代码,所需要的词法分析代码也就没多少行罢了,不过这个代码还有一个细节要处理,就是对于var function等关键字的解析,还是当作普通的标识类型,我们要判断下标识类型的value是不是关键字,来保存为特定的关键字类型,我们只需要修改上面代码的字母类型部分:
+ const KEYWORDS = {
+ var: VAR,
+ function: FUNCTION
+ }
// 字母类型
//// 首字符必须为字母下划线,后面的可以是数字
if (input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_') {
do {
position++
} while (input[position] >= '0' && input[position] <= '9' || input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_')
- tokens.push({type: IDENTIFIER, value: input.substring(start, position)})
+ let value = input.substring(start, position)
+ if (KEYWORDS[value]) tokens.push({type: KEYWORDS[value], value})
+ else tokens.push({type: IDENTIFIER, value: input.substring(start, position)})
continue;
}
扩展:上面我们设定的字符还不全,应该还要补充& | ! > < . [ ] - % * / ^,这是单字符的只需要按照原来的格式补充即可。
稍微麻烦的是双字符的== >= <= != || && >> <<这些怎么办,因为单字符使用了贪心算法,会导致==会解析为两个=,所以在解析到=的时候,需要往后再读一个字符,如果读到的字符是=,则构造一个==,否则就构造一个=,如果是三个字符的,比如... ===是类似的,但是我这里不想支持这个语法。
另外除了数字和字母之外的default分支中,还应该支持'和"来匹配字符串类型,以及关键字true false的布尔类型。
此外,我们最好创建一个Token的类,调整后的完整代码如下(export的原因是后续步骤会用到):
export const ASSIGN = 'ASSIGN', LPAREN = 'LPAREN', RPAREN = 'RPAREN', LBRACE = 'LBRACE', RBRACE = 'RBRACE', LBRACKET = 'LBRACKET', RBRACKET = 'RBRACKET',
SEMICOLON = 'SEMICOLON', COMMA = 'COMMA', PLUS = 'PLUS', MINUS = 'MINUS', MULTIPLY = 'MULTIPLY', DIVIDE = 'DIVIDE', MODULUS = 'MODULUS',
POINT = 'POINT',
AND = 'AND', OR = 'OR', NOT = 'NOT', GT = 'GT', LT = 'LT', GTE = 'GTE', LTE = 'LTE', NEQ = 'NEQ',
BAND = 'BAND', BOR = 'BOR', BXOR = 'BXOR', BNOT = 'BNOT', BSHL = 'BSHL', BSHR = 'BSHR';
export const VAR = 'VAR', IDENTIFIER = 'IDENTIFIER', NUMBER = 'NUMBER', STRING = 'STRING', FUNCTION = 'FUNCTION', IF = 'IF', ELSE = 'ELSE', RETURN = 'RETURN', CONTINUE = 'CONTINUE', BREAK = 'BREAK',FOR = "for", WHILE = "while", NEW_LINE='NEW_LINE', EOF = 'EOF';
export const KEYWORDS = {
var: VAR,
function: FUNCTION,
if: IF,
else: ELSE,
return: RETURN,
continue: CONTINUE,
break: BREAK,
for: FOR,
while: WHILE,
}
export class Token {
constructor(type, value) {
this.type = type;
this.value = value;
}
}
export function lex(input) {
let tokens = []
let position = 0
while (position < input.length) {
switch (input[position]) {
// 有特殊作用的单个字符
case '=':
if (input[position + 1] == '=') {
tokens.push(new Token('EQ', '==')); position += 2; break;
} else {
tokens.push(new Token(ASSIGN, '=')); position++; break;
}
case '(':
tokens.push(new Token(LPAREN, '(')); position++; break;
case ')':
tokens.push(new Token(RPAREN, ')')); position++; break;
case '[':
tokens.push(new Token(LBRACKET, '[')); position++; break;
case ']':
tokens.push(new Token(RBRACKET, ']')); position++; break;
case '{':
tokens.push(new Token(LBRACE, '{')); position++; break;
case '}':
tokens.push(new Token(RBRACE, '}')); position++; break;
case '+':
tokens.push(new Token(PLUS, '+')); position++; break;
case '-':
tokens.push(new Token(MINUS, '-')); position++; break;
case '*':
tokens.push(new Token(MULTIPLY, '*')); position++; break;
case '/':
tokens.push(new Token(DIVIDE, '/')); position++; break;
case '%':
tokens.push(new Token(MODULUS, '%')); position++; break;
case '.':
tokens.push(new Token(POINT, '.')); position++; break;
case '^':
tokens.push(new Token(BXOR, '^')); position++; break;
case '~':
tokens.push(new Token(BNOT, '~')); position++; break;
case '|':
if (input[position + 1] == '|') {
tokens.push(new Token(OR, '||')); position += 2; break;
} else {
tokens.push(new Token(BOR, '|')); position++; break;
}
case '&':
if (input[position + 1] == '&') {
tokens.push(new Token(AND, '&&')); position += 2; break;
} else {
tokens.push(new Token(BAND, '&')); position++; break;
}
case '!':
if (input[position + 1] == '=') {
tokens.push(new Token(NEQ, '!=')); position += 2; break;
} else {
tokens.push(new Token(NOT, '!')); position++; break;
}
case '<':
if (input[position + 1] == '=') {
tokens.push(new Token(LTE, '<=')); position += 2; break;
} else if (input[position + 1] == '<') {
tokens.push(new Token(BSHL, '<<')); position += 2; break;
} else {
tokens.push(new Token(LT, '<')); position++; break;
}
case '>':
if (input[position + 1] == '=') {
tokens.push(new Token(GTE, '>=')); position += 2; break;
} else if (input[position + 1] == '>') {
tokens.push(new Token(BSHR, '>>')); position += 2; break;
} else {
tokens.push(new Token(GT, '>')); position++; break;
}
case ';':
tokens.push(new Token(SEMICOLON, ';')); position++; break;
case ',':
tokens.push(new Token(COMMA, ',')); position++; break;
// 空格 tab 跳过即可,不需要解析
case ' ':
case '\t':
case '\r':
position++; break;
// 回车这里解析一下,因为想要支持js的弱判断
case '\n':
tokens.push(new Token(NEW_LINE, '\n')); position++; break;
case '\'':
var start = position;
while (true) {
position++;
// 字符中间不能有回车
if (position >= input.length) throw new Error('Unterminated string');
if (input[position] == '\n') throw new Error('Enter is not allowed in string');
if (input[position] == '\'' && input[position - 1] != '\\' ) {
tokens.push(new Token(STRING, input.substring(start, position + 1)));
position++;
break;
}
}
break;
case '"':
var start = position;
while (true) {
position++;
// 字符中间不能有回车
if (position >= input.length) throw new Error('Unterminated string');
if (input[position] == '\n') throw new Error('Enter is not allowed in string');
if (input[position] == '"' && input[position - 1] != '\\' ) {
tokens.push(new Token(STRING, input.substring(start, position + 1)));
position++;
break;
}
}
break;
// 剩下数字或字母
default:
var start = position
// 数字类型 包括小数
while ((input[position] >= '0' && input[position] <= '9') || input[position] == '.') {
position++
}
if (start != position) {
tokens.push(new Token(NUMBER, input.substring(start, position)))
break;
}
// 字母类型
//// 首字符必须为字母下划线,后面的可以是数字
if (input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_') {
do {
position++
} while (input[position] >= '0' && input[position] <= '9' || input[position] >= 'a' && input[position] <= 'z' || input[position] >= 'A' && input[position] <= 'Z' || input[position] == '_')
let value = input.substring(start, position)
if (KEYWORDS[value]) tokens.push(new Token(KEYWORDS[value], value))
else tokens.push(new Token(IDENTIFIER, value))
break;
}
// 不认识的字符抛出异常
throw new Error('unexpected input');
}
}
tokens.push(new Token(EOF, ''))
return tokens
}
console.log(lex(`var a = 1 * 3 + 4;`))
好了到这里我们用非常简单的js实现了一个类c语言的词法分析器了,代码非常简单。但是功能略显简陋,尤其是出问题后直接就抛出错误,没有提示具体哪一行哪一列出的问题。其实可以增加一个line变量在每次回车的时候line++,并将line赋值到token的line属性中,position也追加到token属性中,这样也方便后续流程出错时,能追踪问题出现的token,进而找到对应的行号列号。但这都是锦上添花的功能,这里不展开了。此外还可以加上注释、额外需要支持的语法(例如面向对象的class等关键字)、字符串中回车\n的支持。最后得到lex.mjs的内容,可以通过https://cdn.jsdelivr.net/gh/sunwu51/notebook@master/24.11/lex.mjs来引入直接在浏览器中就可以运行体验了,更低的尝试门槛,这也是文章使用js来写的一个主要原因。
如果你想要用其他语言实现的话,我想并不是一个复杂的事情。比如用go语言,用java,用c rust等,都不会很麻烦,如果你想要写一个能被客户端直接运行的语言解释器的话,go会是一个比较建议的选择,他有非常简单的语法,性能好,强类型,更重要的是他是编译型语言,可以最终将你的解释器打包成一个无需任何其他依赖的可执行文件。
例如对于使用java的话,你可以先声明一个Token类还有TokenType枚举,然后继续写一个Lexer类,然后实现一个nextToken方法,返回下一个Token。
public class Token {
public TokenType type;
public String value;
public String toString() {
return type + " : " + value;
}
}
public enum TokenType {
NUMBER,
IDENTIFIER,
.........
}
public class Lexer {
private String input;
private int position;
public Lexer(String input) {
this.input = input;
}
public Token nextToken() {
// 自己仿照上面来实现逻辑~
}
public static void main(String[] args) {
Lexer lexer = new Lexer("1 + 2");
List<Token> tokens = new ArrayList<>();
while (true) {
Token token = lexer.nextToken();
tokens.add(token);
}
System.out.println(tokens);
}
}
逐个字符解析,又叫有限状态机的解析,非常简单高效,很多语法解析都是用的这种方式,比如jackson解析json文本的,我们之前写过剖析其源码的文章。
4 用工具库
lex是一个比较古老的工具,后续升级为flex,他们都能通过一些配置来生成词法分析的代码,下面是一个lex文件的实例。这个文件其实是一个配置文件,主要分了四个区域:
%{和%}中间的是第一部分,头部声明区,主要用来引入头文件,和定义一些全局变量。%}和%%之间的是第二部分,定义一些基础规则,如下,格式是类型 正则,对于数字、标识符的正则可以配置在这部分。%%和%%之间的是第三部分,规则区域,格式是规则 { 行为 },满足规则的执行行为,匹配顺序从上到下,匹配后不再往下走。这部分是识别的核心部分,可以看几个例子"var" { printf("KEYWORD: var\n"); return VAR; }就是完全匹配关键字var{IDENTIFIER} { printf("IDENTIFIER: %s\n", yytext); return IDENTIFIER; }是匹配规则中的IDENTIFIER执行的操作。
%%之后的部分是自己定义c代码的部分,这里可以定义main函数,通常可以像下面这样,读取入参的文件,进行词法分析。如果要后续用于语法分析,用int yylex(void);即可。
%{
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
enum TokenType {
// 关键字
VAR = 1, FUNCTION, RETURN, IF, ELSE, WHILE,
// 标识符和常量
IDENTIFIER, NUMBER, BOOLEAN,
// 运算符
PLUS, MINUS, MULTIPLY, DIVIDE, MODULO,
ASSIGN, PLUS_ASSIGN, MINUS_ASSIGN, MULTIPLY_ASSIGN, DIVIDE_ASSIGN,
// 比较运算符
EQUAL, NOT_EQUAL, LESS_THAN, GREATER_THAN,
LESS_OR_EQUAL, GREATER_OR_EQUAL,
// 逻辑运算符
LOGICAL_AND, LOGICAL_OR, LOGICAL_NOT,
// 位运算符
BITWISE_AND, BITWISE_OR, BITWISE_XOR,
BITWISE_NOT, LEFT_SHIFT, RIGHT_SHIFT,
// 分隔符
LPAREN, RPAREN, LBRACE, RBRACE,
LBRACKET, RBRACKET, COMMA, SEMICOLON,
// 其他
ERROR
};
%}
%option noyywrap
DIGIT [0-9]
LETTER [a-zA-Z_]
IDENTIFIER {LETTER}({LETTER}|{DIGIT})*
NUMBER ({DIGIT}+("."{DIGIT}+)?)|("."{DIGIT}+)
BOOLEAN "true"|"false"
%%
"var" { printf("KEYWORD: var\n"); return VAR; }
"function" { printf("KEYWORD: function\n"); return FUNCTION; }
"return" { printf("KEYWORD: return\n"); return RETURN; }
"if" { printf("KEYWORD: if\n"); return IF; }
"else" { printf("KEYWORD: else\n"); return ELSE; }
"while" { printf("KEYWORD: while\n"); return WHILE; }
{BOOLEAN} {
printf("BOOLEAN: %s\n", yytext);
return BOOLEAN;
}
{IDENTIFIER} {
printf("IDENTIFIER: %s\n", yytext);
return IDENTIFIER;
}
{NUMBER} {
// 判断是整数还是浮点数
if (strchr(yytext, '.') != NULL) {
printf("NUMBER (FLOAT): %s\n", yytext);
} else {
printf("NUMBER (INTEGER): %s\n", yytext);
}
return NUMBER;
}
"," { printf("DELIMITER: ,\n"); return COMMA; }
"+" { printf("ARITHMETIC: +\n"); return PLUS; }
"-" { printf("ARITHMETIC: -\n"); return MINUS; }
"*" { printf("ARITHMETIC: *\n"); return MULTIPLY; }
"/" { printf("ARITHMETIC: /\n"); return DIVIDE; }
"%" { printf("ARITHMETIC: %\n"); return MODULO; }
"==" { printf("COMPARISON: ==\n"); return EQUAL; }
"!=" { printf("COMPARISON: !=\n"); return NOT_EQUAL; }
"<" { printf("COMPARISON: <\n"); return LESS_THAN; }
">" { printf("COMPARISON: >\n"); return GREATER_THAN; }
"<=" { printf("COMPARISON: <=\n"); return LESS_OR_EQUAL; }
">=" { printf("COMPARISON: >=\n"); return GREATER_OR_EQUAL; }
"&&" { printf("LOGICAL: &&\n"); return LOGICAL_AND; }
"||" { printf("LOGICAL: ||\n"); return LOGICAL_OR; }
"!" { printf("LOGICAL: !\n"); return LOGICAL_NOT; }
"&" { printf("BITWISE: &\n"); return BITWISE_AND; }
"|" { printf("BITWISE: |\n"); return BITWISE_OR; }
"^" { printf("BITWISE: ^\n"); return BITWISE_XOR; }
"~" { printf("BITWISE: ~\n"); return BITWISE_NOT; }
"<<" { printf("BITWISE: <<\n"); return LEFT_SHIFT; }
">>" { printf("BITWISE: >>\n"); return RIGHT_SHIFT; }
"(" { printf("DELIMITER: (\n"); return LPAREN; }
")" { printf("DELIMITER: )\n"); return RPAREN; }
"{" { printf("DELIMITER: {\n"); return LBRACE; }
"}" { printf("DELIMITER: }\n"); return RBRACE; }
"[" { printf("DELIMITER: [\n"); return LBRACKET; }
"]" { printf("DELIMITER: ]\n"); return RBRACKET; }
"=" { printf("ASSIGNMENT: =\n"); return ASSIGN; }
"+=" { printf("ASSIGNMENT: +=\n"); return PLUS_ASSIGN; }
"-=" { printf("ASSIGNMENT: -=\n"); return MINUS_ASSIGN; }
"*=" { printf("ASSIGNMENT: *=\n"); return MULTIPLY_ASSIGN; }
"/=" { printf("ASSIGNMENT: /=\n"); return DIVIDE_ASSIGN; }
";" { printf("DELIMITER: ;\n"); return SEMICOLON; }
{NUMBER}[eE][-+]?{DIGIT}+ {
printf("NUMBER (SCIENTIFIC): %s\n", yytext);
return NUMBER;
}
[ \t\n\r]+ { /* 忽略空白 */ }
"//".* { /* 单行注释 */ }
"/*"([^*]|\*+[^*/])*\*+"/" { /* 多行注释 */ }
. {
printf("Unexpected character: %s\n", yytext);
return ERROR;
}
%%
int main(int argc, char **argv) {
if (argc > 1) {
if (!(yyin = fopen(argv[1], "r"))) {
perror(argv[1]);
return 1;
}
}
int token;
while ((token = yylex()) != 0) {
// 可以根据需要单独处理每个 token
}
return 0;
}
这个lex.l文件有点长,但是仔细一看,会发现其实也就是之前我们自己写代码处理的一些情况而已。配置好了这个文件,我们就可以用flex来处理了。
如果你还没有下载flex那么你需要先下载flex和gcc,如果是linux系统的话,应该自带了lex和gcc。windows系统可以从这里下载flex。
$ flex lex.l # 会把l文件编译成lex.yy.c文件
$ gcc lex.yy.c -o lexer # 把c文件编译成可执行文件
$ lexer input.file # 指定文件来解析
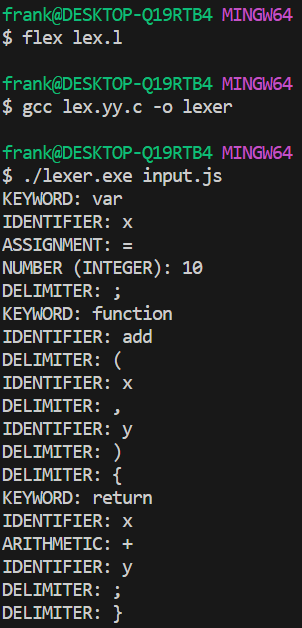
这是c语言体系的flex工具,打开lex.yy.c会发现这个文件有1k+行。如果不想用c语言的话,其实搜一下其他语言,也是有对应的lex工具的。例如java有jflex
从这里下载jflex解压,双击lib目录下的jar包,就可以选择jflex文件来运行了,当然我们需要把l文件改造一下:
package lexer;
%%
%class Lexer
%type Token
%line
%column
%unicode
%{
public static class Token {
public enum Type {
VAR, FUNCTION, RETURN, IF, ELSE, WHILE,
IDENTIFIER, NUMBER, BOOLEAN,
PLUS, MINUS, MULTIPLY, DIVIDE, MODULO,
ASSIGN, PLUS_ASSIGN, MINUS_ASSIGN, MULTIPLY_ASSIGN, DIVIDE_ASSIGN,
EQUAL, NOT_EQUAL, LESS_THAN, GREATER_THAN,
LESS_OR_EQUAL, GREATER_OR_EQUAL,
LOGICAL_AND, LOGICAL_OR, LOGICAL_NOT,
BITWISE_AND, BITWISE_OR, BITWISE_XOR,
BITWISE_NOT, LEFT_SHIFT, RIGHT_SHIFT,
LPAREN, RPAREN, LBRACE, RBRACE,
LBRACKET, RBRACKET, COMMA, SEMICOLON,
ERROR, EOF
}
public Type type;
public String value;
public int line;
public int column;
public Token(Type type, String value, int line, int column) {
this.type = type;
this.value = value;
this.line = line;
this.column = column;
}
@Override
public String toString() {
return String.format("%s: %s (Line: %d, Column: %d)",
type, value, line, column);
}
}
private void log(String category, String value) {
System.out.printf("%s: %s\n", category, value);
}
%}
DIGIT = [0-9]
LETTER = [a-zA-Z_]
IDENTIFIER = {LETTER}({LETTER}|{DIGIT})*
NUMBER = ({DIGIT}+("."{DIGIT}+)?)|("."{DIGIT}+)
SCIENTIFIC_NUMBER = {NUMBER}[eE][-+]?{DIGIT}+
BOOLEAN = "true"|"false"
WHITESPACE = [ \t\n\r]+
SINGLE_COMMENT = "//".*
MULTI_COMMENT = "/*"([^*]|\*+[^*/])*\*+"/"
%%
"var" {
log("KEYWORD", yytext());
return new Token(Token.Type.VAR, yytext(), yyline, yycolumn);
}
"function" {
log("KEYWORD", yytext());
return new Token(Token.Type.FUNCTION, yytext(), yyline, yycolumn);
}
"return" {
log("KEYWORD", yytext());
return new Token(Token.Type.RETURN, yytext(), yyline, yycolumn);
}
"if" {
log("KEYWORD", yytext());
return new Token(Token.Type.IF, yytext(), yyline, yycolumn);
}
"else" {
log("KEYWORD", yytext());
return new Token(Token.Type.ELSE, yytext(), yyline, yycolumn);
}
"while" {
log("KEYWORD", yytext());
return new Token(Token.Type.WHILE, yytext(), yyline, yycolumn);
}
{BOOLEAN} {
log("BOOLEAN", yytext());
return new Token(Token.Type.BOOLEAN, yytext(), yyline, yycolumn);
}
{IDENTIFIER} {
log("IDENTIFIER", yytext());
return new Token(Token.Type.IDENTIFIER, yytext(), yyline, yycolumn);
}
{NUMBER} {
String category = yytext().contains(".") ? "NUMBER (FLOAT)" : "NUMBER (INTEGER)";
log(category, yytext());
return new Token(Token.Type.NUMBER, yytext(), yyline, yycolumn);
}
{SCIENTIFIC_NUMBER} {
log("NUMBER (SCIENTIFIC)", yytext());
return new Token(Token.Type.NUMBER, yytext(), yyline, yycolumn);
}
"," {
log("DELIMITER", yytext());
return new Token(Token.Type.COMMA, yytext(), yyline, yycolumn);
}
"+" {
log("ARITHMETIC", yytext());
return new Token(Token.Type.PLUS, yytext(), yyline, yycolumn);
}
"-" {
log("ARITHMETIC", yytext());
return new Token(Token.Type.MINUS, yytext(), yyline, yycolumn);
}
"*" {
log("ARITHMETIC", yytext());
return new Token(Token.Type.MULTIPLY, yytext(), yyline, yycolumn);
}
"/" {
log("ARITHMETIC", yytext());
return new Token(Token.Type.DIVIDE, yytext(), yyline, yycolumn);
}
"%" {
log("ARITHMETIC", yytext());
return new Token(Token.Type.MODULO, yytext(), yyline, yycolumn);
}
"==" {
log("COMPARISON", yytext());
return new Token(Token.Type.EQUAL, yytext(), yyline, yycolumn);
}
"!=" {
log("COMPARISON", yytext());
return new Token(Token.Type.NOT_EQUAL, yytext(), yyline, yycolumn);
}
"<" {
log("COMPARISON", yytext());
return new Token(Token.Type.LESS_THAN, yytext(), yyline, yycolumn);
}
">" {
log("COMPARISON", yytext());
return new Token(Token.Type.GREATER_THAN, yytext(), yyline, yycolumn);
}
"<=" {
log("COMPARISON", yytext());
return new Token(Token.Type.LESS_OR_EQUAL, yytext(), yyline, yycolumn);
}
">=" {
log("COMPARISON", yytext());
return new Token(Token.Type.GREATER_OR_EQUAL, yytext(), yyline, yycolumn);
}
"&&" {
log("LOGICAL", yytext());
return new Token(Token.Type.LOGICAL_AND, yytext(), yyline, yycolumn);
}
"||" {
log("LOGICAL", yytext());
return new Token(Token.Type.LOGICAL_OR, yytext(), yyline, yycolumn);
}
"!" {
log("LOGICAL", yytext());
return new Token(Token.Type.LOGICAL_NOT, yytext(), yyline, yycolumn);
}
"&" {
log("BITWISE", yytext());
return new Token(Token.Type.BITWISE_AND, yytext(), yyline, yycolumn);
}
"|" {
log("BITWISE", yytext());
return new Token(Token.Type.BITWISE_OR, yytext(), yyline, yycolumn);
}
"^" {
log("BITWISE", yytext());
return new Token(Token.Type.BITWISE_XOR, yytext(), yyline, yycolumn);
}
"~" {
log("BITWISE", yytext());
return new Token(Token.Type.BITWISE_NOT, yytext(), yyline, yycolumn);
}
"<<" {
log("BITWISE", yytext());
return new Token(Token.Type.LEFT_SHIFT, yytext(), yyline, yycolumn);
}
">>" {
log("BITWISE", yytext());
return new Token(Token.Type.RIGHT_SHIFT, yytext(), yyline, yycolumn);
}
"(" {
log("DELIMITER", yytext());
return new Token(Token.Type.LPAREN, yytext(), yyline, yycolumn);
}
")" {
log("DELIMITER", yytext());
return new Token(Token.Type.RPAREN, yytext(), yyline, yycolumn);
}
"{" {
log("DELIMITER", yytext());
return new Token(Token.Type.LBRACE, yytext(), yyline, yycolumn);
}
"}" {
log("DELIMITER", yytext());
return new Token(Token.Type.RBRACE, yytext(), yyline, yycolumn);
}
"[" {
log("DELIMITER", yytext());
return new Token(Token.Type.LBRACKET, yytext(), yyline, yycolumn);
}
"]" {
log("DELIMITER", yytext());
return new Token(Token.Type.RBRACKET, yytext(), yyline, yycolumn);
}
"=" {
log("ASSIGNMENT", yytext());
return new Token(Token.Type.ASSIGN, yytext(), yyline, yycolumn);
}
"+=" {
log("ASSIGNMENT", yytext());
return new Token(Token.Type.PLUS_ASSIGN, yytext(), yyline, yycolumn);
}
"-=" {
log("ASSIGNMENT", yytext());
return new Token(Token.Type.MINUS_ASSIGN, yytext(), yyline, yycolumn);
}
"*=" {
log("ASSIGNMENT", yytext());
return new Token(Token.Type.MULTIPLY_ASSIGN, yytext(), yyline, yycolumn);
}
"/=" {
log("ASSIGNMENT", yytext());
return new Token(Token.Type.DIVIDE_ASSIGN, yytext(), yyline, yycolumn);
}
";" {
log("DELIMITER", yytext());
return new Token(Token.Type.SEMICOLON, yytext(), yyline, yycolumn);
}
{WHITESPACE} { /* 忽略空白 */ }
{SINGLE_COMMENT} { /* 忽略单行注释 */ }
{MULTI_COMMENT} { /* 忽略多行注释 */ }
. {
log("UNEXPECTED CHARACTER", yytext());
return new Token(Token.Type.ERROR, yytext(), yyline, yycolumn);
}
<<EOF>> { return null; }
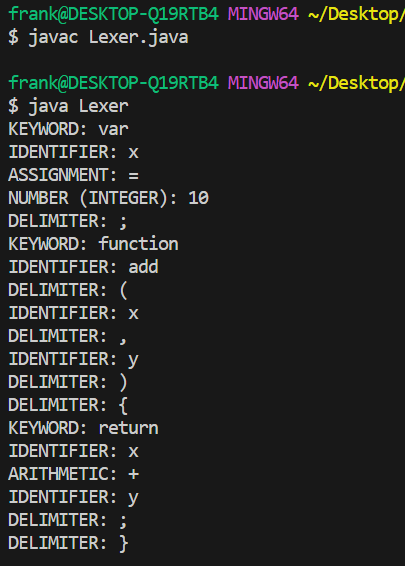
同样还是yylex这个方法来获取下一个token,最后也得到了词法分析的结果:
另外也有antlr4等功能更丰富的库,实现了不止词法分析还有语法分析等,这里就不展开说了,因为后续语法分析的时候会讲到。
5 小结
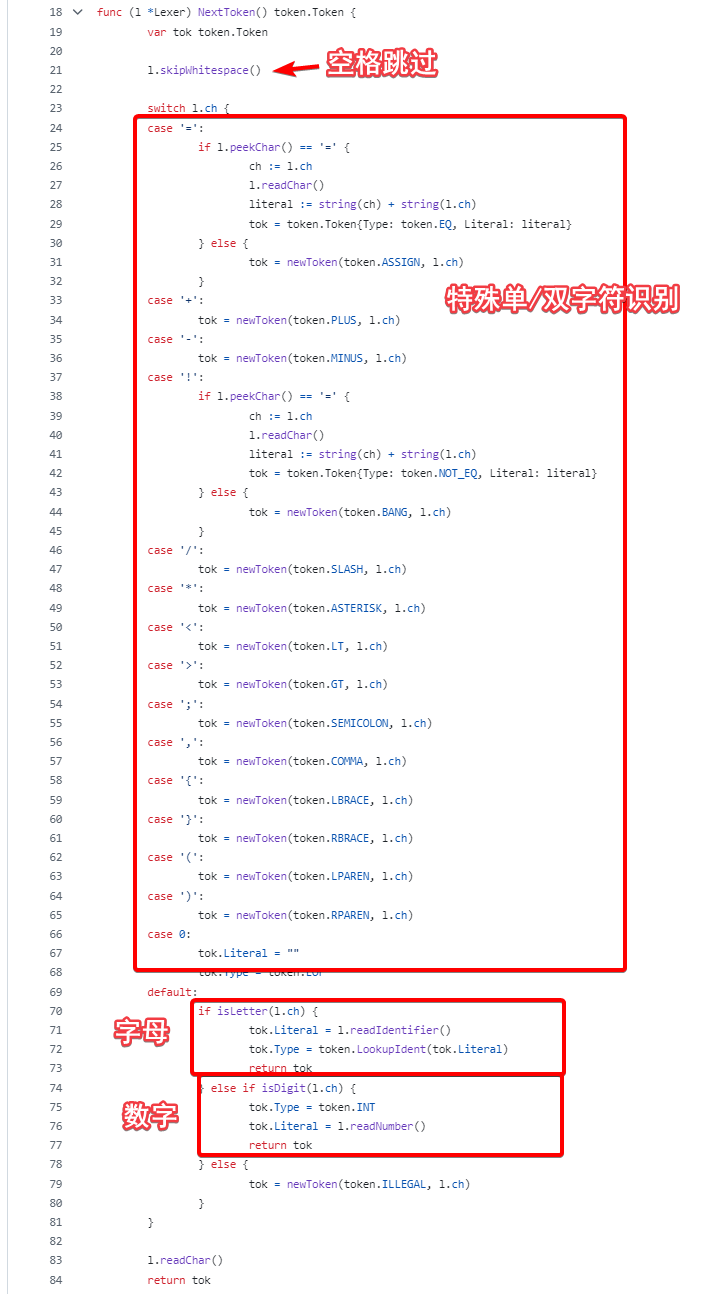
写一个词法解析并不是一个复杂的事情,逐个字符解析是最建议的一种形式。在很多书籍中也都是使用了类似的方法,在《用go语言自制解释器》这本书中的第一章就是介绍和实现了词法解析,这本书不长,go的语法也比较简单,还可以从微信读书上阅读(可以从淘宝2块钱买一本电子的),链接,词法解析器的代码在这里,可以看到这个解析器的思路也是我们上面的思路。
在《crafting interpreters》这本书中,作者也使用了类似方法,本书的第4章是词法解析的部分,也是可以免费在线阅读的一本书,第四章,对应代码链接,涉及到的代码有Token.java TokenType.java Scanning.java这几个类,大概逻辑就是我们第3部分中的逻辑。