1 代码结构
语法分析之后我们把token[]转换成了statement[],接下来可以直接对语句进行求值,例如1 + 1;这个表达式语句的返回值就是2,而print(1 + 1);返回值是空,但是求值过程中会打印2。不同语句的求值过程是不同的,表达式语句只需要对表达式求值,而其他语句则各自有不同的功能,需要逐个讨论和实现。但是整体的代码结构如下:
// 对statement[]求值
function evalStatements(statements) {
var res = nil;
for (let statement of statements) {
res = evalStatement(statement);
}
return res;
}
function evalStatement(statement) {
if (statement instanceof ExpressionStatement) {
return evalExpression(statement.expression);
} else if
//..... 分别讨论不同的语句的作用
}
function evalExpression(expression) {
// 分别讨论各种AstNode
if (expression instanceof NumberAstNode) {
return new NumberElement(expression.token.value);
}
//.....
}
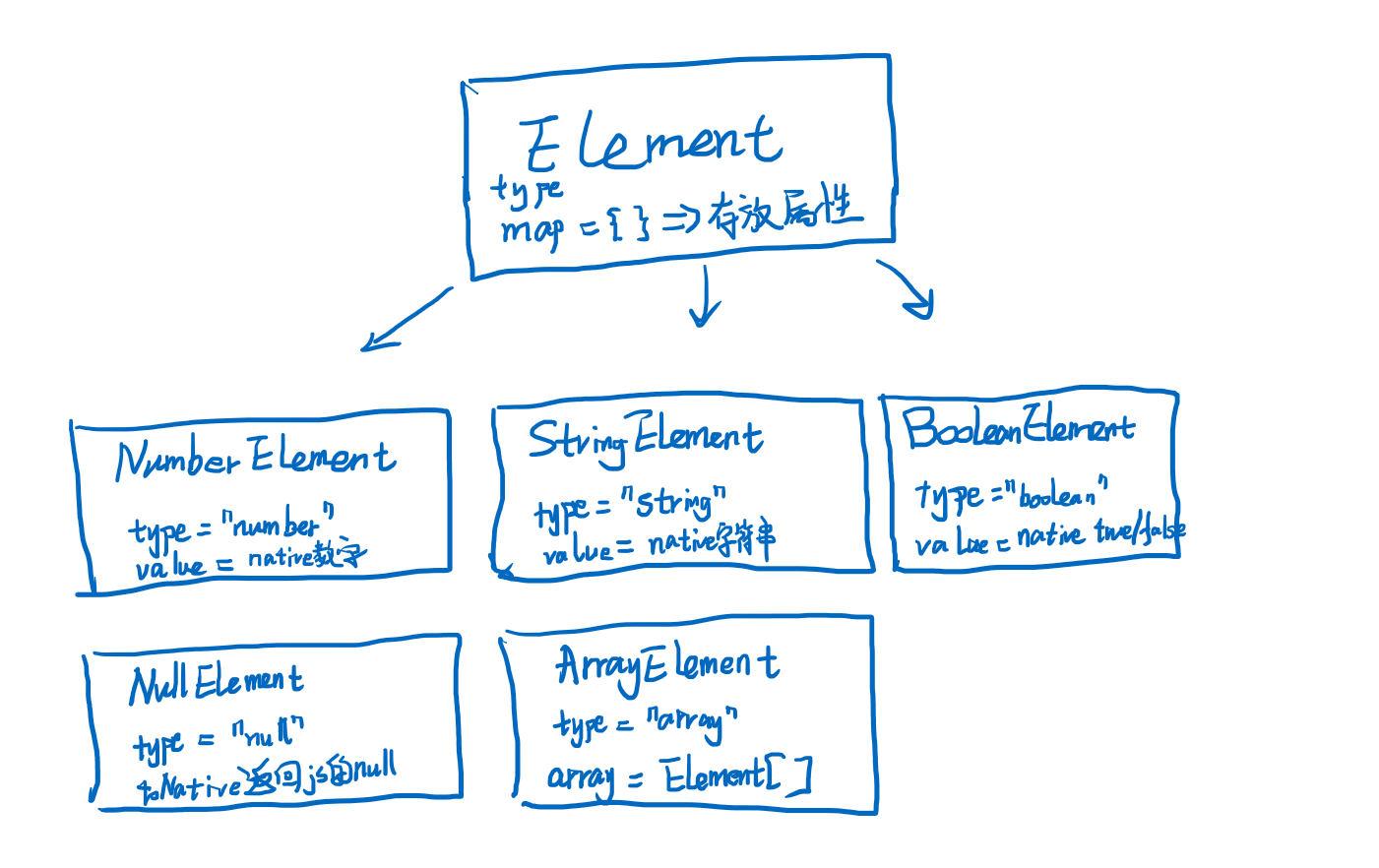
2 数据封装
以1这个表达式为例,对其求值的结果显然就是数字1,但是如果直接return 1返回的是宿主语言中的数据类型,这也是一种实现方式,但是相对来说不太灵活,在上层和底层语言之间没有明显的分界,这会使得后期的维护较为困难。所以我们的语言中最好有属于自己的数据结构的封装,基本的思路就是封装一个类,将宿主语言中的原始数据包装在这个类中,而这个类提供其他的面向我们宿主语言的接口和使用方式。这里我使用了一种非常简单的数据封装,即所有的数据都是Element,其实就是对象,但是js中已经有了Object关键字,所以换了一个名字。我们声明一个class Element作为基础的数据类型,而对于基础的数据类型我们分别封装NumberElement、StringElement、BooleanElement、NullElement和ArrayElement,代码如下,这里我们定义了toString方法便于调试,toNative方法便于转换成js中的原始数据。
export class Element {
constructor(type) {
this.type = type;
this.map = new Map(); // 用来动态追加属性
}
set(key, value) {
this.map.set(key, value);
}
get(key) {
if (key == "type") return new StringElement(this.type);
if (this.map.get(key) != undefined) {
return this.map.get(key);
}
return nil;
}
toString() {
return `{ ${Array.from(this.map.entries()).map(it=>it[0]+":"+it[1].toString()).join(',')} }`;
}
toNative() {
function elementToJsObject(element) {
if (element instanceof Element) {
switch(element.type) {
case "number":
case "boolean":
case "null":
case "string":
case "array":
return element.toNative();
default:
var iter = element.map.keys();
var res = {};
var item;
while (!(item = iter.next()).done) {
var key = item.value;
res[key] = elementToJsObject(element.map.get(key))
}
return res;
}
}
return element;
}
return elementToJsObject(this);
}
}
export class NumberElement extends Element {
// value是数字或者字符串
constructor(value) {
super('number');
if (isNaN(value) || isNaN(parseFloat(value))) {
throw new Error('Invalid number');
}
this.value = parseFloat(value);
}
toNative() {
return this.value;
}
toString() {
return this.value.toString();
}
}
export class BooleanElement extends Element {
constructor(value) {
super('boolean');
this.value = value;
}
toNative() {
return this.value;
}
toString() {
return this.value.toString();
}
}
export class StringElement extends Element {
constructor(value) {
super('string');
this.value = value;
}
toNative() {
return this.value;
}
toString() {
return this.value.toString();
}
}
export class NullElement extends Element {
constructor() {
super('null');
}
toNative() {
return null;
}
toString() {
return "null";
}
}
export class ArrayElement extends Element {
// value: Element[]
constructor(array) {
super('array');
this.array = array;
}
toString() {
return `[${this.array.map(v => v.toString()).join(', ')}]`;
}
toNative() {
return this.array.map(e =>e.toNative());
}
}
// null / true / false 只有一种,所以采用单例
export const nil = new NullElement(),
trueElement = new BooleanElement(true),
falseElement = new BooleanElement(false);
// 声明运行时的报错,预留一个position字段,后续用于异常打印错误的行列信息
export class RuntimeError extends Error {
constructor(msg, position="") {
super(msg)
}
}
整理下上面几种Element类型如下图,有了这几种类型,我们的语言的数据类型就定义好了,这几种就已经完全够用了,我们可以看到这个数据类型的设计的关键就是Element这个非常灵活的结构,我放置了一个map,以支持动态的属性追加和赋值,即使基础的NumberElement中,也可以动态追加属性。例如var a = 1; a.name = "one"; print(a.name);最终也会打印one,因为数字在我们的语言中也是一种Element类型,所以可以动态追加属性,这种统一的设计让我们的语言更容易理解,也更加的灵活。
这样我们就可以完善evalExpression方法了
function evalExpression(exp) {
// 基础数据类型
if (exp instanceof NumberAstNode) {
return new NumberElement(exp.toString());
} else if (exp instanceof StringAstNode) {
return new StringElement(exp.toString());
} else if (exp instanceof NullAstNode) {
return nil;
} if (exp instanceof BooleanAstNode) {
var str = exp.toString();
if (str == 'true') {
return trueElement;
} else if (str == 'false') {
return falseElement;
} else {
throw new Error('invalid boolean');
}
}
// 前缀 后缀 中缀 运算符,单独定义函数
else if (exp instanceof PrefixOperatorAstNode) {
return evalPrefixOperator(exp);
} else if (exp instanceof PostfixOperatorAstNode) {
return evalPostfixOperator(exp);
} else if (exp instanceof InfixOperatorAstNode) {
return evalInfixOperator(exp);
}
// 数组声明 [1,2,3,"a"],分别对每个item 求值,整合成数组即可
else if (exp instanceof ArrayDeclarationAstNode) {
return new ArrayElement(exp.items.map(item => evalExpression(item)));
}
// 分组,直接求里面的表达式即可
else if (exp instanceof GroupAstNode) {
return evalExpression(exp.exp);
}
// 对象声明的节点 {a:1, b: 2, c: {a : 3}},对于每个key直接按toString求值,value则是递归表达式求值
// 注意这里声明了一个普通的Element,在map上追加了kv
else if (exp instanceof MapObjectDeclarationAstNode) {
var res = new Element("nomalMap");
exp.pairs.forEach(item => {
var v = evalExpression(item.value);
res.set(item.key.toString(), v);
});
return res;
}
// .... 还有其他AstNode稍后再说,先来理解以上几种
return nil;
}
接下来是对前缀 中缀 后缀表达式求值的函数如下,操作符节点要做的事情基本思路是:先把left/right递归求值,然后校验left/right的类型是否正确,例如*乘法只能对数字类型操作,第三步则是对两个操作数做相应的运算,注意因为我们封装了一层Element,需要先从Element中获取native的js类型,然后对js类型进行运算,运算之后,再把结果封装成Element返回,这里可以看一下++作为前缀和后缀运算符的时候的不同实现,并思考为什么。另外需要额外注意下+可以操作字符串进行拼接,然后!操作符不止可以跟boolean类型,还可以跟其他类型,只有false/0/null是false,其他的都按照true。
// 前缀运算符节点求值 + - ! ~
function evalPrefixOperator(prefixOperatorAstNode) {
var right = evalExpression(prefixOperatorAstNode.right);
switch (prefixOperatorAstNode.op.type) {
case LEX.PLUS:
if (right instanceof NumberElement) {
return right;
} else {
throw new RuntimeError("+ should only used with numbers", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
case LEX.MINUS:
if (right instanceof NumberElement) {
right.value = -right.value;
return right;
} else {
throw new RuntimeError("- should only used with numbers", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
case LEX.NOT:
if (right instanceof BooleanElement) {
right.value = !right.value;
return right;
}
if (right instanceof NullElement) {
return trueElement;
}
return falseElement;
case LEX.BIT_NOT:
if (right instanceof NumberElement) {
right.value = ~right.value;
return right;
} else {
throw new RuntimeError("~ should only used with numbers", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
case LEX.INCREMENT:
if (checkSelfOps(prefixOperatorAstNode.right)) {
var item = evalExpression(prefixOperatorAstNode.right);
if (item instanceof NumberElement) {
item.value++;
return item;
}
}
throw new RuntimeError("++ should only used with number variable", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
case LEX.DECREMENT:
if (checkSelfOps(prefixOperatorAstNode.right)) {
var item = evalExpression(prefixOperatorAstNode.right);
if (item instanceof NumberElement) {
item.value--;
return item;
}
}
throw new RuntimeError("-- should only used with number variable", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
default:
throw new RuntimeError(`Unsupported prefix operator: ${prefixOperatorAstNode.op.type}`, `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
}
// 后缀运算符节点求值 ++ --
function evalPostfixOperator(postfixOperatorAstNode) {
if (checkSelfOps(postfixOperatorAstNode.left)) {
var left = evalExpression(postfixOperatorAstNode.left);
if (left instanceof NumberElement) {
// 需要返回一个新的NumberElement对象保持原来的value,原来的对象的value+1
switch (postfixOperatorAstNode.op.type) {
case LEX.INCREMENT:
return new NumberElement(left.value++);
case LEX.DECREMENT:
return new NumberElement(left.value--);
default:
throw new RuntimeError("unknown postfix operator " + postfixOperatorAstNode.op.type, `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
}
throw new RuntimeError("++/-- should only used with number variable", `${prefixOperatorAstNode.op.line}:${prefixOperatorAstNode.op.pos}`);
}
}
// ++ --等操作符的使用场景判断:只能用在 a++ p.a++ (p.a)++ 这些场景下
function checkSelfOps(node) {
if (node instanceof IdentifierAstNode) return true;
if (node instanceof InfixOperatorAstNode && node.op.type === LEX.POINT && node.right instanceof IdentifierAstNode) return true;
if (node instanceof InfixOperatorAstNode && node.op.type === LEX.LBRACKET && node.right instanceof IndexAstNode) return true;
if (node instanceof GroupAstNode) return checkSelfOps(node.exp);
return false;
}
// 中缀运算符节点求值
function evalInfixOperator(infixOperatorAstNode) {
switch (infixOperatorAstNode.op.type) {
// 基础操作符
case LEX.PLUS:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value + r.value);
}
if ((l instanceof StringElement || r instanceof StringElement)) {
return new StringElement(l.toString() + r.toString());
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.MINUS:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value - r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.MULTIPLY:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value * r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.DIVIDE:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value / r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.MODULUS:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value % r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.BSHR:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value >> r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.BSHL:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return new NumberElement(l.value << r.value);
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.LT:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value < r.value ? trueElement : falseElement;
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.GT:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value > r.value ? trueElement : falseElement;
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.LTE:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value <= r.value ? trueElement : falseElement;
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.GTE:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value >= r.value ? trueElement : falseElement;
}
throw new RuntimeError(`Invalid infix operator ${infixOperatorAstNode.op.type} for ${l.type} and ${r.type}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.EQ:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value == r.value ? trueElement : falseElement;
}
if (l instanceof StringElement && r instanceof StringElement) {
return l.value == r.value ? trueElement : falseElement;
}
return l == r ? trueElement : falseElement;
case LEX.NEQ:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && r instanceof NumberElement) {
return l.value != r.value ? trueElement : falseElement;
}
if (l instanceof StringElement && r instanceof StringElement) {
return l.value != r.value ? trueElement : falseElement;
}
return l != r ? trueElement : falseElement;
case LEX.AND:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l == nil || r == nil) {
return falseElement;
}
if (l == falseElement || r == falseElement) {
return falseElement;
}
if (l instanceof NumberElement && l.value == 0) {
return falseElement;
}
if (r instanceof NumberElement && r.value == 0) {
return falseElement;
}
return trueElement;
case LEX.OR:
var l = evalExpression(infixOperatorAstNode.left);
var r = evalExpression(infixOperatorAstNode.right);
if (l instanceof NumberElement && l.value != 0) {
return trueElement;
}
if (l != nil && l != falseElement) {
return trueElement;
}
if (r instanceof NumberElement && r.value != 0) {
return trueElement;
}
if (r != nil && r != falseElement) {
return trueElement;
}
return falseElement;
// 点运算符是获取对象的属性,而我们的属性都是存到Element的map中,所以点运算符就是取map的value,对应我们在Element中定义的get方法直接使用即可
// 后面的LBRACKET运算符也是类似的,只不过后者还支持数组或字符串索引case
case LEX.POINT:
var l = evalExpression(infixOperatorAstNode.left);
if (l instanceof Element || l instanceof Map) {
if (infixOperatorAstNode.right instanceof IdentifierAstNode) {
return l.get(infixOperatorAstNode.right.toString());
}
}
throw new RuntimeError(". should be after an Element", `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
case LEX.LPAREN: // 小括号运算符特指函数执行
var functionCall = new FunctionCallAstNode(infixOperatorAstNode.token, infixOperatorAstNode.left, infixOperatorAstNode.right.args);
return evalExpression(functionCall);
case LEX.LBRACKET: // 中括号运算符特指index访问
assert(infixOperatorAstNode.right instanceof IndexAstNode, "Invalid infix operator usage for []", infixOperatorAstNode.op);
var index = evalExpression(infixOperatorAstNode.right.index);
assert(index instanceof NumberElement || index instanceof StringElement, "[] operator only support number or string index", infixOperatorAstNode.op);
var target = evalExpression(infixOperatorAstNode.left);
// 数组/字符串 [数字]
if (index instanceof NumberElement) {
assert(target instanceof ArrayElement || target instanceof StringElement, "[number] operator only support array or string index", infixOperatorAstNode.op);
if (target instanceof ArrayElement) {
return target.array[index.value];
} else {
return new StringElement(target.value.charAt(index.value));
}
}
// obj["字符串"]
if (target instanceof Element) {
return target.get(index.value);
}
throw new RuntimeError("Invalid infix operator usage for []", `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
default:
throw new RuntimeError(`Unknown operator ${infixOperatorAstNode.toString()}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
}
}
上面的代码在eval_v1.mjs中,整个表达式的解析已经初具规模,虽然目前还只能解析表达式和表达式语句,而且还不是所有类型的表达式,但是实际上其实已经完成了大多数代码了,例如对于上一节我们一直拿来做例子的表达式语句1+2*3/4-5,现在已经可以正常求值了。这个表达式求值的过程传入的AstNode是-操作符,会先对left和right递归求值,整个过程就是个树的dfs最终求值。
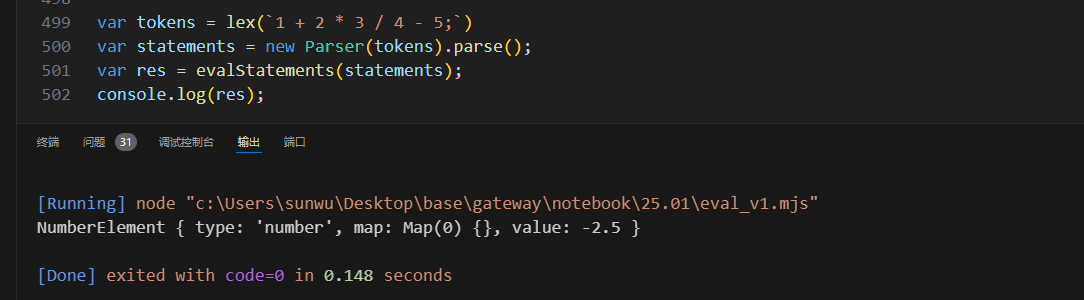
3 其他表达式
上面主要对基础的数据类型本身(数字、字符串、布尔、null)还有部分操作符进行了求值,表达式的形式还有其他的AstNode这里需要分开讨论。
3.1 IdentifierAstNode 与 VarStatement
标识符或者叫变量名节点的使用与VarStatement密不可分,因为需要先赋值,才能使用变量,举个例子对于var a = 1; a;的返回值应该是1,如果再对a进行其他操作例如a + 1;的返回值就是2。a + 1在运行的时候,需要有地方能获取到a这个变量的值,我们可以设计一个map来存储key=a,value=1,也就是在VarStatement求值的时候,将a的值set到这个map中,后续再对a这个IDENTIFIERASTNODE进行求值时,就可以从map中取到对应的值了,例如:
var ctx = new Map();
function evalStatement(statement) {
if (statement instanceof ExpressionStatement) {
return evalExpression(statement.expression);
} else if (statement instanceof VarStatement) {
return evalVarStatement(statement);
}
//..... 分别讨论不同的语句的作用
}
function evalVarStatement(varStatement) {
// 对等号之后的表达式求值
var value = evalExpression(varStatement.value);
var name = varStatement.name.toString();
// 将变量名和对应的值set到一个全局的map中
ctx.set(name, value);
}
function evalExpression(exp) {
if (exp instanceof IdentifierAstNode) {
var value = ctx.get(exp.toString());
if (value) return value;
// 没有赋值,直接拿来用,抛出异常
throw new RuntimeError(`Identifier ${exp.toString()} is not defined`, exp.token);
}
// ....
}
上面的方式是最简单的一种赋值方式,所有的变量都是全局作用域的,这种对于有作用域的块无法正常工作,例如:
var a = 1
var f = function() {
var a = 2;
return a;
}
print(f());
print(a); // a会被f()中的a覆盖掉,所以打印出来的是2,这是不符合预期的
函数中声明的变量,显然是函数自己的作用域的,不应该去修改全局作用域的值,因而变量的上下文ctx应该是分开的,块语句就是切分上下文,块中的作用域是独立的,块语句的最明显标志就是{},普通的块语句、if-else、for、function等都会携带一个块语句,继承自上一层的块作用域,所以应该设计一个ctx的嵌套结构,例如:
class Context {
constructor(parent) {
this.parent = parent;
this.variables = new Map();
}
get(name) {
// 自己有这个变量,就返回这个变量的值
if (this.variables.has(name)) {
return this.variables.get(name);
}
// 自己没有,则从parent中不断向上查找
if (this.parent) {
return this.parent.get(name);
}
// 最后也没有,返回null
return null;
}
// 对应Varstatement
set(name, value) {
this.variables.set(name, value);
}
// 更新变量,对应ASSIGN操作符
update(name, value) {
if (this.variables.has(name)) {
this.set(name, value);
return;
} else if (this.parent) {
this.parent.update(name, value);
return;
}
// 没有声明就更新,直接报错
throw new RuntimeError(`Identifier ${name} is not defined`);
}
}
这个上下文,需要在每个evalXXX函数中都需要改造,改为携带ctx参数进行上下文传递,然后在块语句的时候,创建一个新的Context,将当前的ctx作为新的上下文的父上下文:
function evalStatement(statement, ctx) {
if (statement instanceof ExpressionStatement) {
return evalExpression(statement.expression, ctx);
} else if (statement instanceof VarStatement) {
return evalVarStatement(statement, ctx);
} else if (statement instanceof BlockStatement) {
return evalBlockStatement(statement, new Context(ctx));
}
//..... 分别讨论不同的语句的作用
}
function evalBlockStatement(blockStatement, ctx) {
return evalStatements(blockStatement.statements, ctx);
}
function evalVarStatement(varStatement) {
// 对等号之后的表达式求值
var value = evalExpression(varStatement.value);
// 如果value是NumberElement,则返回一个新的NumberElement
// 因为数字/字符串/boolean/Null四大基础类型在赋值运算的时候是值拷贝,如果直接返回r则是引用拷贝。
// 而字符串是没有可修改value的方法,所以不需要对字符串拷贝。boolean和null则都是单例的,所以也不需要新创建。
// 只有数字类型是需要新创建一份,如果这里直接返回r的话,var a=1; var b =a; b++; print(a); 这段代码a就变成了2,不符合预期,所以返回一个新的NumberElement
// 同样的处理在ASSIGN操作符的时候,需要返回一个新的NumberElement。
if (value instanceof NumberElement) {
value = new NumberElement(value.toNative());
}
var name = varStatement.name.toString();
// 将变量名和对应的值set到一个全局的map中
ctx.set(name, value);
}
function evalExpression(exp) {
if (exp instanceof IdentifierAstNode) {
var value = ctx.get(exp.toString());
if (value) return value;
// 没有赋值,直接拿来用,抛出异常
throw new RuntimeError(`Identifier ${exp.toString()} is not defined`, `${exp.token.line}:${exp.token.pos}`);
}
// ....
}
function evalInfixOperator(infixOperatorAstNode) {
switch (infixOperatorAstNode.op.type) {
// .....
// 赋值运算符
case LEX.ASSIGN:
var r = evalExpression(infixOperatorAstNode.right);
// a = 100这种等号左侧是IdentifierAstNode的最简单形式
if (infixOperatorAstNode.left instanceof IdentifierAstNode) {
var l = evalExpression(infixOperatorAstNode.left);
if (r instanceof NumberElement) {
// 注意这里返回一个新的,保证值传递特性
r = new NumberElement(r.value);
}
ctx.update(infixOperatorAstNode.left.toString(), r);
return r;
}
// 点、index运算符,如a.age,需要先获取a,再对a进行属性赋值
if (infixOperatorAstNode.left instanceof InfixOperatorAstNode) {
if (infixOperatorAstNode.left.op.type === LEX.POINT) {
var lhost = evalExpression(infixOperatorAstNode.left.left);
assert(lhost instanceof Element, "Point should used on Element", infixOperatorAstNode.left.op);
if (r instanceof NumberElement) {
r = new NumberElement(r.value);
}
lhost.set(infixOperatorAstNode.left.right.toString(), r);
return r;
} else if (infixOperatorAstNode.left.op.type === LEX.LBRACKET) {
var lhost = evalExpression(infixOperatorAstNode.left.left);
assert(lhost instanceof Element, "[index] should used after Element", infixOperatorAstNode.left.op);
assert(infixOperatorAstNode.left.right instanceof IndexAstNode, "[index] should be IndexAstNode", infixOperatorAstNode.left.op);
var index = evalExpression(infixOperatorAstNode.left.right.index);
assert(index instanceof NumberElement || index instanceof StringElement, "[index] should be Number or String", infixOperatorAstNode.left.op);
if (r instanceof NumberElement) {
r = new NumberElement(r.value);
}
lhost.set(index.toNative(), r);
return r;
}
}
throw new RuntimeError(`Assignment to non-identifier ${infixOperatorAstNode.left.toString()}`, `${infixOperatorAstNode.op.line}:${infixOperatorAstNode.op.pos}`);
// ......
}
}
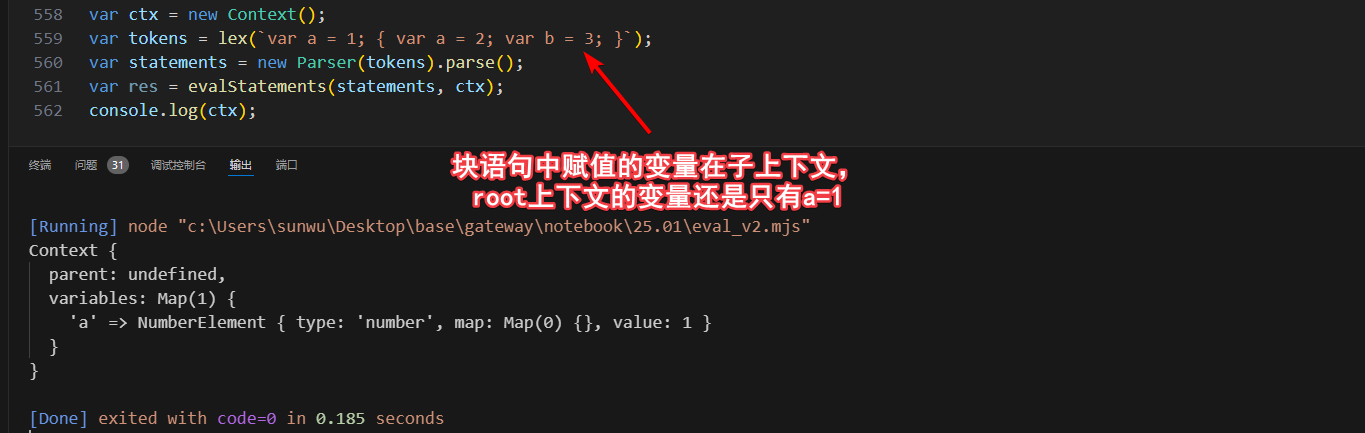
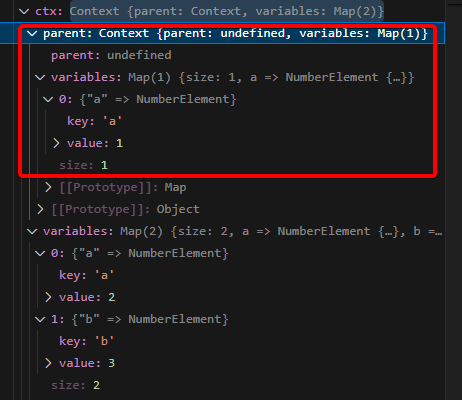
在块语句最后一句执行完的时候打断点,可以观察到,在块语句中,ctx中有a和b的变量值分别是2和3。
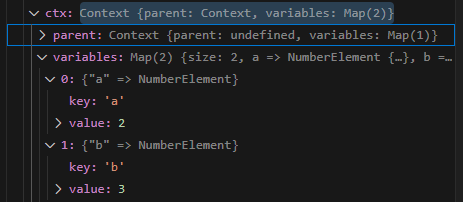
而ctx.parent指向的才是全局上下文,这里面的a=1,上下文中获取变量的get方法是先从当前上下文获取,获取不到再从parent一层层向上,所以在块语句中,会先获取a=2,在块语句外则获取到a=1。
3.2 FunctionCallAstNode/FunctionDeclarationAstNode与ReturnStatement
对于函数调用,在parse.js中我们采用了中缀运算符(来表示函数调用,在上面中缀运算符求值中,我们已经添加了这一段函数:
case LEX.LPAREN: // 小括号运算符特指函数执行
var functionCall = new FunctionCallAstNode(infixOperatorAstNode.token, infixOperatorAstNode.left, infixOperatorAstNode.right.args);
return evalExpression(functionCall, ctx);
而对于函数声明的表达式,返回的值是一个函数,我们目前四个基础的Element中显然还没有能表示函数类型的,所以需要新增一种FunctionElement,用来表示函数类型,下面是对应的代码,在属性上,有入参列表,函数体,以及函数声明时的上下文引用。这三个都有重要的作用:
- 入参列表例如
function(a,b)中就是a和b,因为这个变量名会在函数执行的时候使用到,所以需要保存起来,在body块语句执行的时候,需要在上下文中将a,b的值set为实际调用时候的入参值,对应call中this.params.forEach这一行代码。 - 函数体,直接保存了块语句,在实际执行的时候,即调用
call方法的时候,需要执行这部分代码,对应evalStatement(this.body, newCtx); - 声明时上下文的引用,这个上下文的作用主要是为了捕捉函数声明时的上下文中的变量,也就是闭包的功能。
在函数调用时,对应调用当前FunctionElement.call()方法,该方法有5个参数,他们作用如下:
name: 函数名,这个起到debug的作用,在throw中会用到。args: 函数的实际入参,会被依次赋给this.params。_this和_super:对应面向对象场景下,函数中出现this/super时候的指向,暂时不用管,等讨论到面向对象再展开。exp: 等讨论到throw异常处理再展开。
这里我们还需要在Context中添加一个funCtx属性,用于保存函数调用时的上下文,这个funCtx是一个对象,包含两个属性:
info: 函数信息,主要是函数名和函数id,之所以要记录每个函数id,是为了区分ReturnStatement是针对哪个函数的返回,有了ctx.funCtx.name,在运行返回语句的时候,就知道自己是对哪一个函数的返回了。returnElement: 用于记录返回值信息,具体来说当遇到ReturnStatement的时候,就把返回的值,设置到上下文中,同时向上把父ctx的returnElement都进行设置,直到最近的funCtx.name!=null的上下文为止,这就是函数开始的上下文。
class Context {
constructor(parent) {
this.parent = parent;
this.variables = new Map();
this.funCtx = {name : undefined, returnElement: undefined};
}
// 这个函数中可能又有多个块域,每个都需要设置返回值
setReturnElement(element) {
if (!this.funCtx.name) {
this.funCtx.returnElement = element;
if (this.parent) this.parent.setReturnElement(element, info);
}
}
// 获取当前函数所在的上下文,throw的时候会打印调用栈用
getFunctionCtx() {
if (this.funCtx.name) return this.funCtx;
if (this.parent) return this.parent.getFunctionCtx();
return null;
}
// ....其他方法
}
export class FunctionElement extends Element {
// params: string[], body: BlockStatement, closureCtx: Context
constructor(params, body, closureCtx) {
super('function');
this.params = params;
this.body = body;
// 函数声明的时候的上下文引用
this.closureCtx = closureCtx;
}
toString() {
return `FUNCTION`
}
// name: string, args: Element[], _this: Element, _super: Element, exp: 打印异常堆栈相关
call(name, args, _this, _super, exp) {
// 允许长度不匹配和js一样灵活
// if (args.length != this.params.length) {
// throw new RuntimeError(`function ${name+" "}call error: args count not match`);
// }
var newCtx = new Context(this.closureCtx);
if (_this) {
newCtx.set("this", _this);
}
if (_super) {
newCtx.set("super", _super);
}
newCtx.funCtx.name = name;
this.params.forEach((param, index) => {
newCtx.set(param, args[index] ? args[index] : nil);
});
evalBlockStatement(this.body, newCtx);
return newCtx.funCtx.returnElement = newCtx.funCtx.returnElement ? newCtx.funCtx.returnElement : nil;
}
}
接下来需要在evalExpression中增加对FunctionCallAstNode和FunctionDeclarationAstNode的支持:
function evalExpression(exp, ctx) {
//......
else if (exp instanceof FunctionDeclarationAstNode) {
return new FunctionElement(exp.params.map(item=>item.toString()), exp.body, ctx)
}
// 函数调用
else if (exp instanceof FunctionCallAstNode) {
var funcExpression = exp.funcExpression;
// 去掉冗余的组
while (funcExpression instanceof GroupAstNode) {
funcExpression = funcExpression.exp;
}
var fname = null;
if (funcExpression instanceof IdentifierAstNode) {
fname = funcExpression.toString();
} else {
fname = "uname";
}
// 注入一个print函数,来辅助调试
if (fname == 'print') {
console.log(...(exp.args.map((arg) => evalExpression(arg, ctx).toNative())));
return nil;
}
var funcElement = evalExpression(funcExpression, ctx);
if (funcElement instanceof FunctionElement) {
return funcElement.call(fname, exp.args.map((arg) => evalExpression(arg, ctx)), null, null, exp);
} else {
throw new RuntimeError(`${funcExpression.toString()} is not a function`,`${exp.token.line}:${exp.token.pos}`);
}
}
//......
}
最后在入口evalStatements中,还应该加上判断,如果某一句运行之后returnElement不为空了(这一句是return语句),那么该Block中后续的语句就不要执行了,直接跳过即可:
function evalStatements(statements, ctx) {
var res = nil;
for (let statement of statements) {
res = evalStatement(statement, ctx);
if (ctx.funCtx.returnElement) break;
}
return res;
}
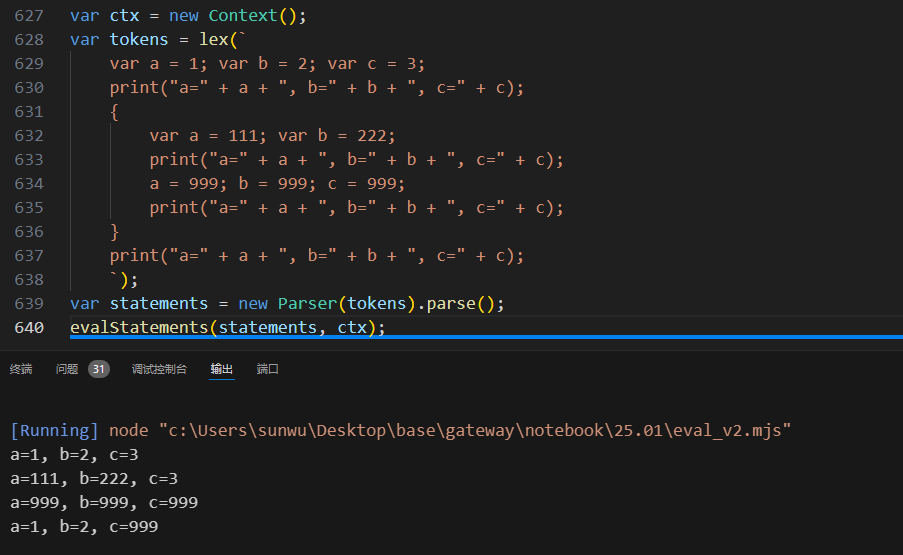
对应的代码在eval_v2.mjs文件中,我们简单运行一段代码,来验证前面上下文的作用域看是否是正确的,并测试下植入的print函数是否正常工作:
然后我们测试自己声明的函数是否能正常运行:
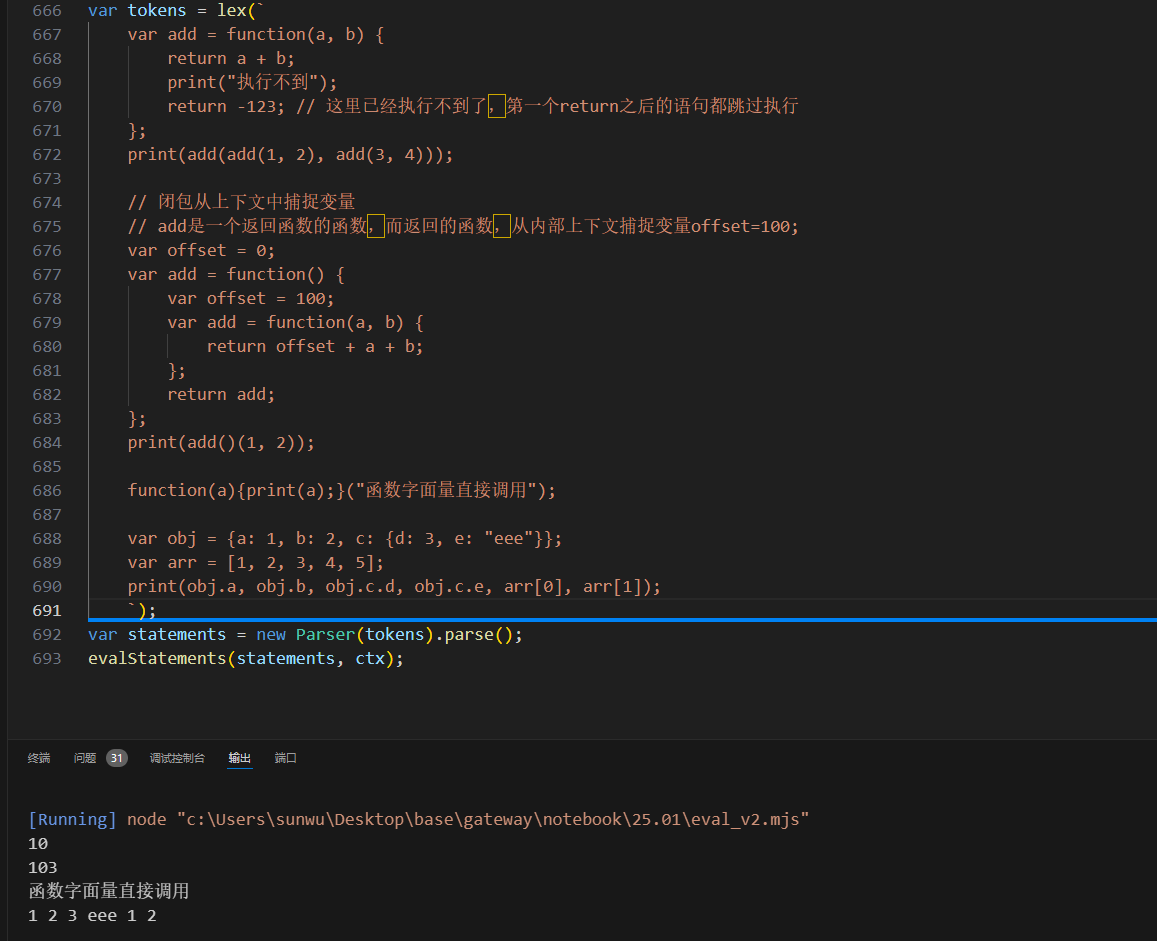
上面的测试中,我们还把普通对象声明和数组声明的逻辑也验证了。
目前为止,出了创建新对象的NewAstNode以外,所有的表达式都已经支持了,面向对象的部分我们放到最后来讲。
4 其他语句
经过前面的讨论,我们实现了对ExpressionStatement VarStatement ReturnStatement BlockStatement四种语句的支持,这刚好也是我们讲解语法分析的时候上来分析讨论的四种基本语句,后续我们还增加了if``for break continue throw try-catch和class 语句。我们分别来看如何实现求值:
4.1 IfStatement
对condition求值,如果为true,则执行IfBody如果为false,则执行ElseBody(如果有的话)。
function evalStatement(statement, ctx) {
// ...
else if (statement instanceof IfStatement) {
var condRes = evalExpression(statement.conditionAstNode, ctx);
if ((condRes instanceof NumberElement) && condRes.value == 0 && statement.elseBlockStatement) {
evalBlockStatement(statement.elseBlockStatement, new Context(ctx));
} else if (condRes == nil || condRes == falseElement) {
if (statement.elseBlockStatement) {
evalBlockStatement(statement.elseBlockStatement, new Context(ctx));
}
} else {
evalBlockStatement(statement.ifBlockStatement, new Context(ctx));
}
}
// ...
}
4.2 ForStatement/BreakStatement/ContinueStatement
对于for语句,我们要做的是先执行init语句,这个语句只会开始执行一次,不会循环执行多次。接下来执行condition,如果为true,则执行body,然后执行step。然后循环这个过程condition->body->step,直到condition为false。
// context中新增forCtx来处理循环语句,主要是设置break、continue标志位,来控制执行流程
class Context {
constructor(parent) {
this.variables = new Map();
this.funCtx = {name : undefined, returnElement: undefined};
// inFor主要是判断是否在for循环中,当出现break或continue的时候,设置对应的字段,并且从自己开始不断向上找到inFor=true,并将遍历路径上的上下文的对应字段都进行设置。
this.forCtx = {inFor: false, break: false, continue: false};
this.parent = parent;
}
setBreak() {
this.forCtx.break = true;
if (this.forCtx.inFor) {
return; //找到最近的for就结束
} else if (this.parent) {
// 不能跨函数
if (this.funCtx.name) throw new RuntimeError(`break not in for`);
this.parent.setBreak();
} else {
throw new RuntimeError('break not in for');
}
}
setContinue() {
this.forCtx.continue = true;
if (this.forCtx.inFor) {
return; //找到最近的for就结束
} else if (this.parent) {
if (this.funCtx.name) throw new RuntimeError(`continue not in for`);
this.parent.setContinue();
} else {
throw new RuntimeError('continue not in for');
}
}
// ...
}
function evalStatement(statement, ctx) {
// ...
else if (statement instanceof ForStatement) {
if (statement.initStatement) {
evalStatement(statement.initStatement, ctx);
}
while (true) {
if (statement.conditionStatement) {
if (!(statement.conditionStatement instanceof ExpressionStatement)) {
throw new RuntimeError("Condition should be an ExpressionStatement", `${statement.token.line}:${statement.token.pos}`);
}
var condRes = evalExpression(statement.conditionStatement.expression, ctx);
if (condRes instanceof NumberElement && condRes.value === 0) {
return nil;
}
if (condRes == nil || condRes == falseElement) {
return nil;
}
}
var newCtx = new Context(ctx);
newCtx.forCtx.inFor = true;
evalBlockStatement(statement.bodyBlockStatement, newCtx);
if (newCtx.forCtx.break || newCtx.funCtx.returnElement) break;
if (statement.stepAstNode) {
evalExpression(statement.stepAstNode, ctx);
}
}
} else if (statement instanceof BreakStatement) {
ctx.setBreak();
} else if (statement instanceof ContinueStatement) {
ctx.setContinue();
}
// ...
}
function evalStatements(statements, ctx) {
var res = nil;
for (let statement of statements) {
// break continue的上下文中也不需要继续执行了直接跳过后续的语句
if (ctx.funCtx.returnElement || ctx.forCtx.break || ctx.forCtx.continue) break;
res = evalStatement(statement, ctx);
}
return res;
}
for-break-continue逻辑和function类似,但循环没有名字,所以我们使用了inFor=true来标识for循环开始的上下文,另外for循环中的break、continue不能跨函数,所以上翻的过程,同时判断了是否跨函数了,如果有则抛出异常,以避免for(var i=0;i<10;i++) { function(){break;}(); },这样的语法应该是要报错的。
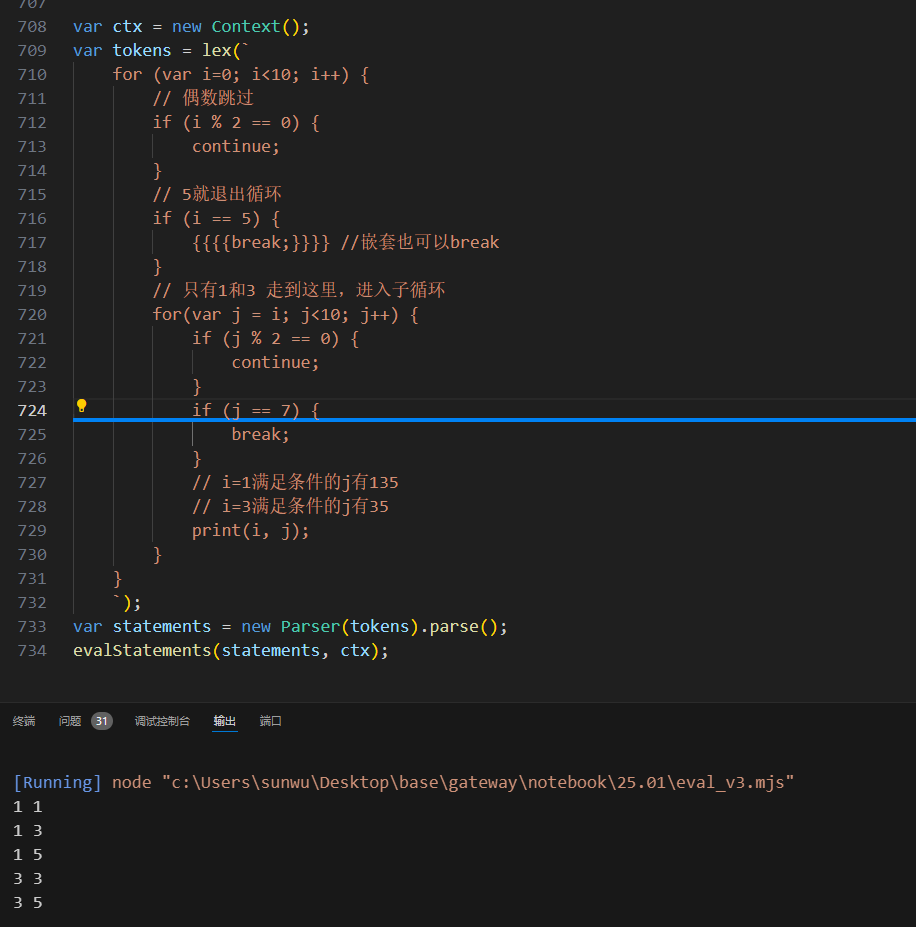
我们把4.1和4.2的内容整理到eval_v3.mjs中,并进行如下测试:
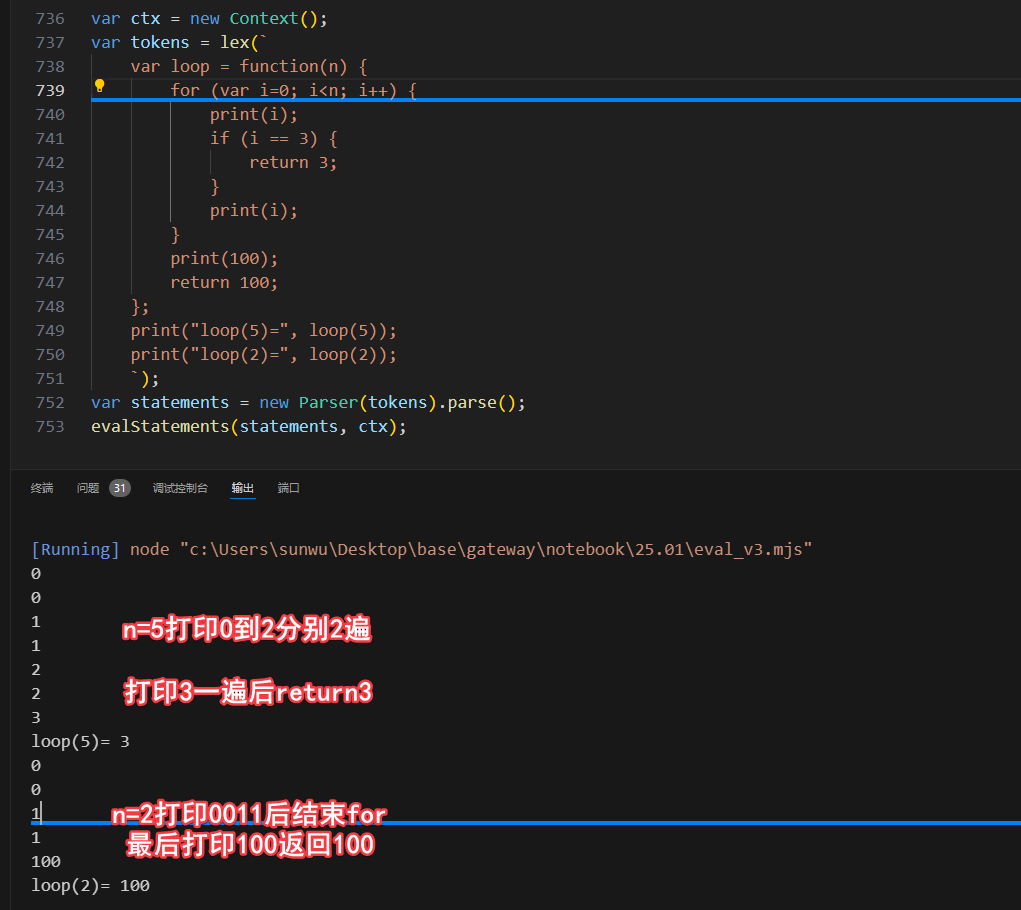
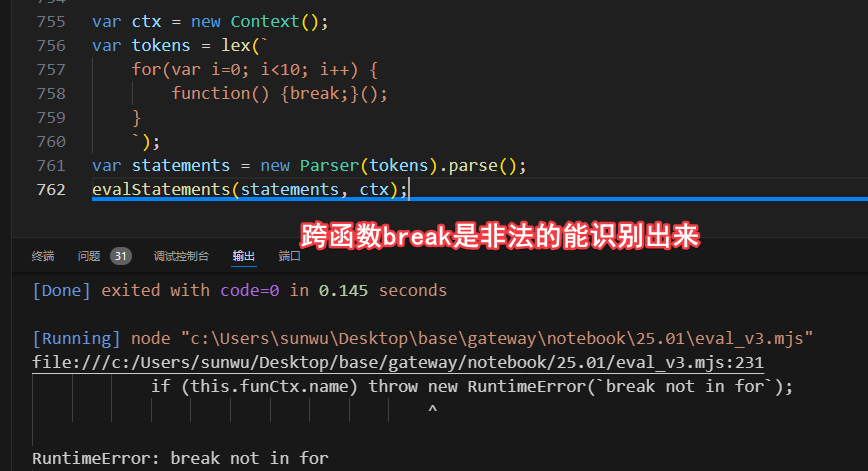
4.3 ThrowStatement
ThrowStatement和异常抛出有关,我们就来讨论下当前语言的异常处理机制。对于当前函数来说,异常和return是类似的,都会导致当前函数的结束。不同的是运行函数的地方,return value的value会作为函数表达式的返回值,而异常在函数运行完之后,会继续往上抛出,直到被try-catch捕捉到,如果直到最顶层上下文也没有被try-catch捕捉到,则需要让当前程序退出,并打印异常的堆栈信息。
我们先来讨论没有try-catch不断向上throw的场景,首先新增Context.throwElement,至于为什么不直接放到funCtx中,则是因为throw可以直接在函数外执行,这一点与return稍有不同。
class Context {
constructor(parent) {
this.variables = new Map();
this.funCtx = {name : undefined, returnElement: undefined};
this.forCtx = {inFor: false, break: false, continue: false};
this.parent = parent;
// 在Context中新增一个throwElement字段,用来记录当前函数抛出的异常
// 这里先假设throwElement就是一个普通的Element对象
this.throwElement = undefined;
}
// ...
}
然后解析ThrowStatement,直接把当前上下文的throwElement设置为当前throw的异常,这里和return不同,return是直接把当前上下文,一直上翻到函数进入的上下文,把每一层的returnElement都设置为return的值。throw只设置当前上下文的原因是,在某一级上下文可能存在try-catch就把异常给catch住了,就不会再往上了。
function evalStatement(statement, ctx) {
//......
else if (statement instanceof ThrowStatement) {
var err = evalExpression(statement.valueAstNode, ctx);
// 追加一个stack属性来记录堆栈
err.set("stack", [{funCtx : ctx.getFunctionCtx(), position: `${statement.token.line}:${statement.token.pos}`}]);
ctx.throwElement = err;
}
//......
}
而当发现没有被catch的时候,则向上一层上下文抛出,如下ctx.throwElement不为空的时候也需要break,同时在当前语句抛出异常的时候,需要加一个processThrow函数,这个函数主要判断如果是当前已经是根上下文,那么异常会导致程序退出,打印堆栈。如果不是根上下文,则需要往上传递,并且stack要记录每一层的函数信息,所以当出现函数上下文切换的时候,需要追加一层函数信息到stack,这里statement.token可以获取到具体的代码的行列位置信息,这对于排查问题非常重要。
function evalStatements(statements, ctx) {
var res = nil;
for (let statement of statements) {
if (ctx.funCtx.returnElement || ctx.forCtx.break || ctx.forCtx.continue || ctx.throwElement) break;
res = evalStatement(statement, ctx);
if (ctx.throwElement) processThrow(ctx, statement);
}
return res;
}
function processThrow(ctx, statement) {
if (!ctx.parent) { // 根上下文了,则直接结束进程,打印异常堆栈
console.error(ctx.throwElement.get("msg").toNative());
ctx.throwElement.get("stack").forEach(item=> {
item = item.toNative();
console.error(` at ${item.funCtx.name} ${item.position}`);
});
// 打印堆栈后,退出运行
process.exit(1);
}
// 不是根上下文就继续上抛
ctx.parent.throwElement = ctx.throwElement;
// 如果当前已经是函数上下文声明的地方,则对栈顶函数名赋值,并追加一层新的栈
if (ctx.funCtx.name) {
var stack = ctx.throwElement.get("stack");
stack[stack.length-1].functionName = ctx.funCtx.name;
stack.push({functionName: "<anonymous>", position: `${statement.token.line}:${statement.token.pos}`});
}
}
那么来试一下throw {msg: "hello world"};这一句。
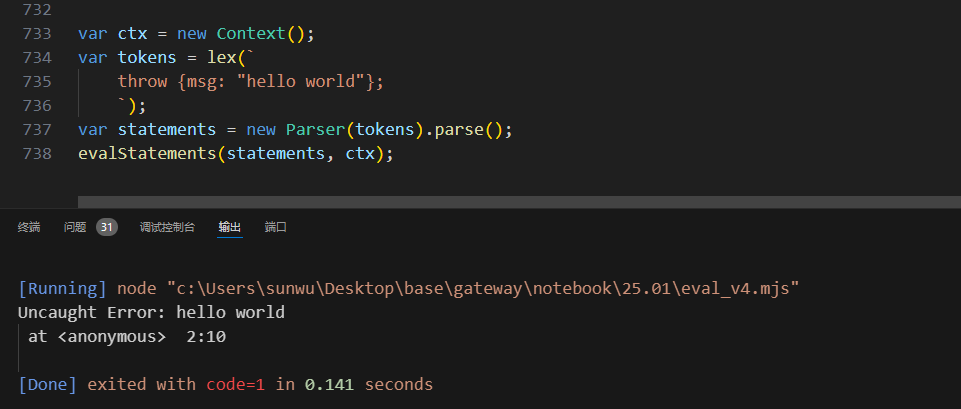
然后再看一个复杂场景,多层函数调用嵌套,最终触发throw,一层一层上翻
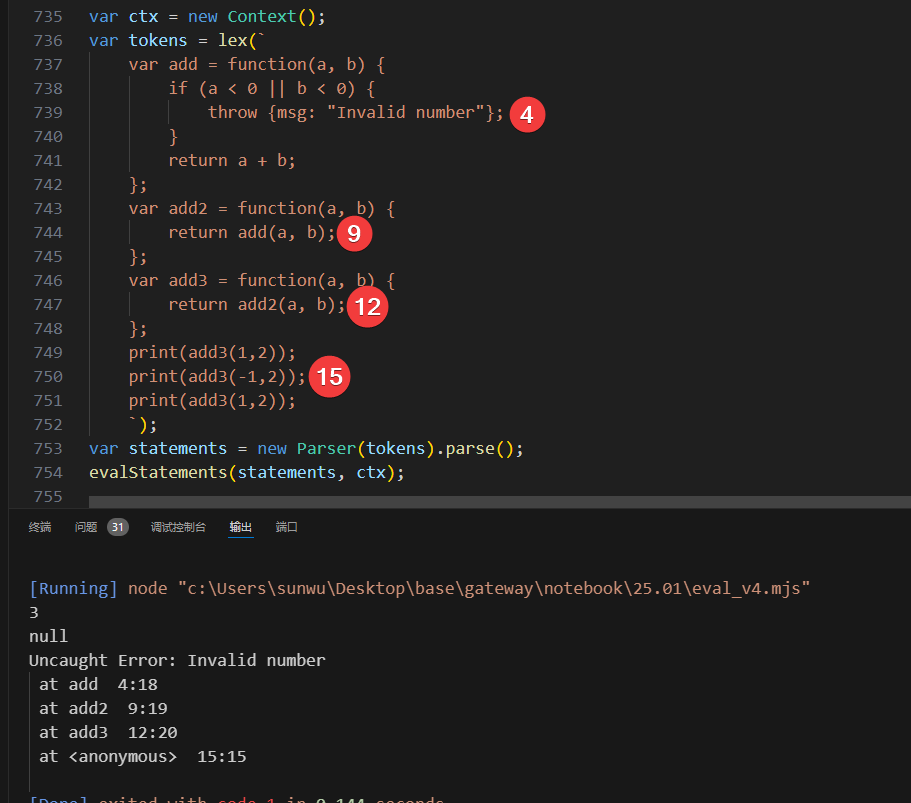
上面代码还有个问题,就是throw如果发生在某个表达式运行过程中,例如print(add(1,2))这个print函数中嵌套add函数,如果后者抛出异常,虽然判断中
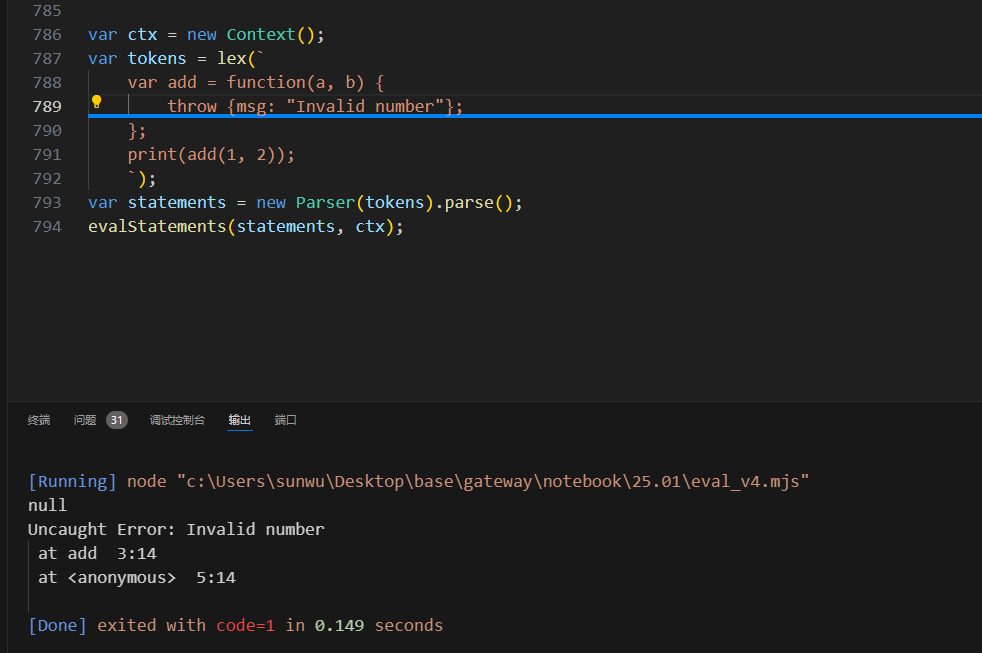
这个问题非常严重,因为add的时候已经异常了,所以不应该再print任何结果了,他出现的原因是我们对于throwElement判断非空,跳过执行,是在每一句statement执行之前判断的,而add和print是一个表达式AstNode节点先后执行的,他们在同一个语句中的多个表达式。而要想跳过print的执行,并非容易得事情,一种简单可行的方案是在每次运行完evalExpression之后,都需要判断一下ctx.throwElement是否为空,如果不为空,则需要跳过后续表达式的执行。还是以print(add(1,2))为例,Ast如下,dfs从叶子结点开始,1和2分别执行,返回两个数字,并且没有抛出异常,add函数可以继续执行,add过程中抛出了异常,此时再print函数继续执行的时候判断了ctx.throwElement!=null,即跳过打印的步骤。
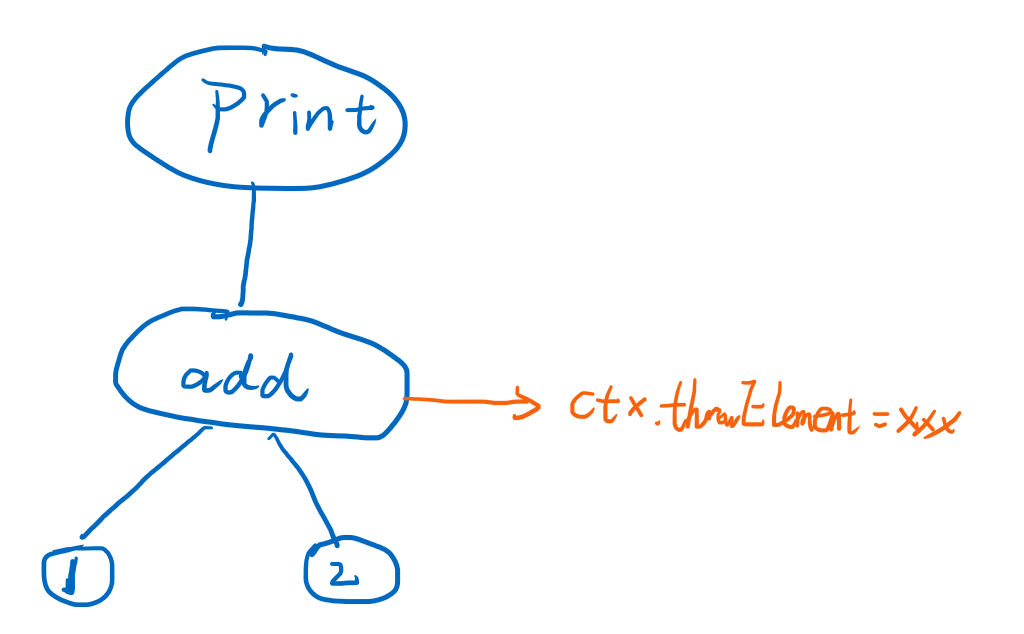
这个方法显然是可行的:
- 对于表达式中其他表达式执行完之后,需要判断是否抛出了异常,来跳过同一个语句中后续的表达式执行;
- 对于同一个块中的语句,通过判断当前语句执行完之后,是否抛异常,来跳过后续语句的执行,并将异常设置到父级上下文;
- 父级上下文也是一个块语句,也会因为抛出异常而跳过执行,继续上面步骤,直到抛出到根上下文,打印堆栈,退出进程。
- 堆栈需要再函数处记录,所以在函数
call方法中,需要判断是否函数体有异常抛出,如果有,则需要记录函数名行号等信息,并追加到堆栈中。
但是这个方法的改动有点多,即在每个evalExpression之后都需要进行判断是否跳过后续表达式,在Ast求值的过程中,本来就是一个dfs调用栈,有什么方法能不断的向上终止执行吗?有的,那就是异常,即我们可以利用Native语言的异常机制,来实现自己的异常机制,这是个非常讨巧的方法。在往前思考一步,我们为什么不直接用js的异常,还要自己封装一个异常呢?这是因为js的异常,最终打印的调用栈信息是js函数的,而不是我们的语言的,它对应的行号都是我们解释器代码的,这样用户是无法定位问题的,类比到java就是打印的异常如果是cpp代码的异常行号等信息。虽然没法直接使用js的异常,但是可以利用js的异常机制,来包装我们的语言的异常机制,大概的思路就是,在ThrowStatement的时候,抛出一个js异常,在evalStatements执行每一句的时候进行,try-catch,捕捉这个js异常,如果捕捉到了,就判断当前是否是根上下文,是的话,打印堆栈,退出进程,否则,就继续把这个异常throw,这样利用js的异常机制,throw的异常又会来到上一层调用栈。而在FunctionElement#call方法中,对body的执行,也使用try-catch,捕捉到异常时,则设置堆栈信息。
这个方法显然也是可行的:
- 对于表达式问题,一个jsError会导致所有代码停止执行,不断上抛,避免了后续表达式执行。
- 对于块中其他语句问题,随着jsError的继续上抛,也会停止后续代码,避免了执行到
throw后续代码。 - 对于父级块,同样的重复步骤,不断上抛,直到根上下文。
- 堆栈信息,在函数
call方法中,进行记录。
上面的代码我们推倒重来,应该在eval_v3.mjs的基础上,先声明RuntimeError增加一个element属性,我们要把自己语言的异常栈记录到这个element中,因为我们需要再自己程序中访问,秉持一切都是Element的思想,所以需要再封装一种错误的Element,如下需要msg和stack两个属性,并且这里我们用了一个辅助字段preSetPos来记录异常发生的详细位置,去掉这个字段也不影响程序的运行,异常的定位点就成是语句的维度。
// 1 修改RuntimeError这个js原生异常,新增一个element属性,用来记录我们语言的调用堆栈信息
export class RuntimeError extends Error {
constructor(msg, position, element) {
super(msg);
this.element = element ? element: new ErrorElement(msg, [{position}]);
}
}
// 2 这个ErrorElement是一种新的Element
export class ErrorElement extends Element {
constructor(msg, stack = []) {
super('error');
this.set("msg", jsObjectToElement(msg));
this.set("stack", jsObjectToElement(stack));
}
pushStack(info) {
this.get("stack").array.push(jsObjectToElement(info));
}
updateFunctionName(name) {
var last = this.get("stack").array[this.get("stack").array.length - 1];
if (last && last.get("functionName") == nil) {
last.set("functionName", new StringElement(name));
}
}
toNative() {
return {
msg: this.get("msg") ? this.get("msg").toNative() : null,
stack: this.get("stack") ? this.get("stack").toNative() : null
}
}
}
function jsObjectToElement(obj) {
if (typeof obj === 'number') {
return new NumberElement(obj);
} else if (typeof obj === 'string') {
return new StringElement(obj);
} else if (typeof obj === 'boolean') {
return obj ? trueElement: falseElement;
} else if (obj === null) {
return nil;
} else if (Array.isArray(obj)) {
return new ArrayElement(obj.map(e => jsObjectToElement(e)));
} else if (obj === null || obj === undefined) {
return nil;
}
// obj类型
const keys = Object.keys(obj);
const res = new Element("nomalMap")
res.map = new Map();
keys.forEach(key => res.map.set(key, jsObjectToElement(obj[key])));
return res;
}
接下来新增ThrowStatement的解析,主要修改以下三个地方:
// 1 修改evalStatement中,新增throw语句解析
else if (statement instanceof ThrowStatement) {
var err = evalExpression(statement.valueAstNode, ctx);
throw new RuntimeError(err.get("msg").toNative(), `${statement.token.line}:${statement.token.pos}`);
}
// 2 当块中多语句执行的时候,遇到RuntimeError,需要判断是否根上下文,如果是则打印堆栈,退出进程。
function evalStatements(statements, ctx) {
var res = nil;
for (let statement of statements) {
if (ctx.funCtx.returnElement || ctx.forCtx.break || ctx.forCtx.continue) break;
try {
res = evalStatement(statement, ctx);
} catch(e) {
if (e instanceof RuntimeError) {
if (e.stack[e.stack.length-1].position == "") {
e.stack[e.stack.length-1].position = `${statement.token.line}:${statement.token.pos}`;
}
if (!ctx.parent) { // 根上下文了,则直接结束进程,打印异常堆栈
console.error("Uncaught Error: " + e.message);
e.element.toNative().stack.forEach(item=> {
// 最顶层的栈一定是没有函数名的,补一个__root__默认函数名
console.error(` at ${item.functionName ? item.functionName : "__root__"} ${item.position}`);
});
// 打印堆栈后,退出运行
process.exit(1);
}
}
throw e;
}
}
return res;
}
// 3 修改FunctionElement#call方法,对函数体执行,也使用try-catch,捕捉到异常时,设置堆栈信息。
call(name, args, _this, _super, exp) { // exp就是用来取当前函数调用所在的pos的,体现在了pushStack中
var newCtx = new Context(this.closureCtx);
if (_this) {
newCtx.set("this", _this);
}
if (_super) {
newCtx.set("super", _super);
}
newCtx.funCtx.name = name;
this.params.forEach((param, index) => {
newCtx.set(param, args[index] ? args[index] : nil);
});
try {
evalBlockStatement(this.body, newCtx);
} catch (e) {
if (e instanceof RuntimeError) {
if (e.element instanceof ErrorElement) {
// 更新前面没有设置的函数名信息
e.element.updateFunctionName(name);
// 设置当前函数调用的位置,调用当前函数所在的函数信息也不更新
e.element.pushStack({position: `${exp.token.line}:${exp.token.pos}`})
}
}
throw e;
}
return newCtx.funCtx.returnElement = newCtx.funCtx.returnElement ? newCtx.funCtx.returnElement : nil;
}
这个“寄生”方案中,我们声明了一种新的Element来进行throw,也就意味着前面测试用的throw {msg:xxx}是非法的写法了,我们还需要规定一种创建ErrorElement的语法,这里我们植入一个内置函数error来返回ErrorElement:
// 注入一个print函数,来辅助调试
if (fname == 'print') {
console.log(...(exp.args.map((arg) => evalExpression(arg, ctx).toNative())));
return nil;
}
// 再注入一个error函数,来辅助调试
if (fname == 'error') {
if (exp.args.length == 0) {
throw new RuntimeError("error() takes at least 1 argument",`${exp.token.line}:${exp.token.pos}`);
}
var msg = evalExpression(exp.args[0], ctx);
if (!(msg instanceof StringElement)) {
throw new RuntimeError("msg should be a String",`${exp.token.line}:${exp.token.pos}`);
}
return new ErrorElement(msg.toNative());
}
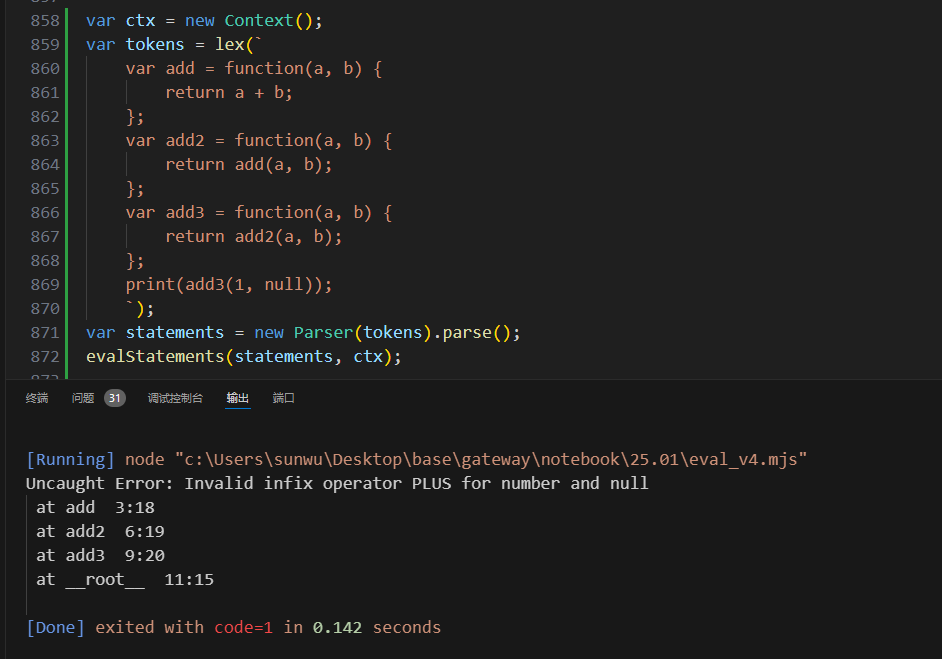
与此同时,我们代码中原来throw RuntimeError的地方也不需要修改,就能把异常体现到自己的语言中。
4.4 TryCatchStatement
TryCatchStatement目的是为了捕捉前面抛出的异常,对应了js中我们自定义的RuntimeError,新增这个类型的语句。
else if (statement instanceof TryCatchStatement) {
try {
return evalBlockStatement(statement.tryBlockStatement, new Context(ctx));
} catch(e) {
if (e instanceof RuntimeError) {
var catchCtx = new Context(ctx);
// try-catch的没机会上翻到函数定义的ctx了,所以主动设置
e.element.updateFunctionName(ctx.getFunctionName());
// 把errorElement设置到catch的变量名上
catchCtx.set(statement.catchParamIdentifierAstNode.toString(), e.element);
evalBlockStatement(statement.catchBlockStatement, catchCtx);
} else {
throw e; //未知异常,可能是程序bug了
}
}
}
就完成了:
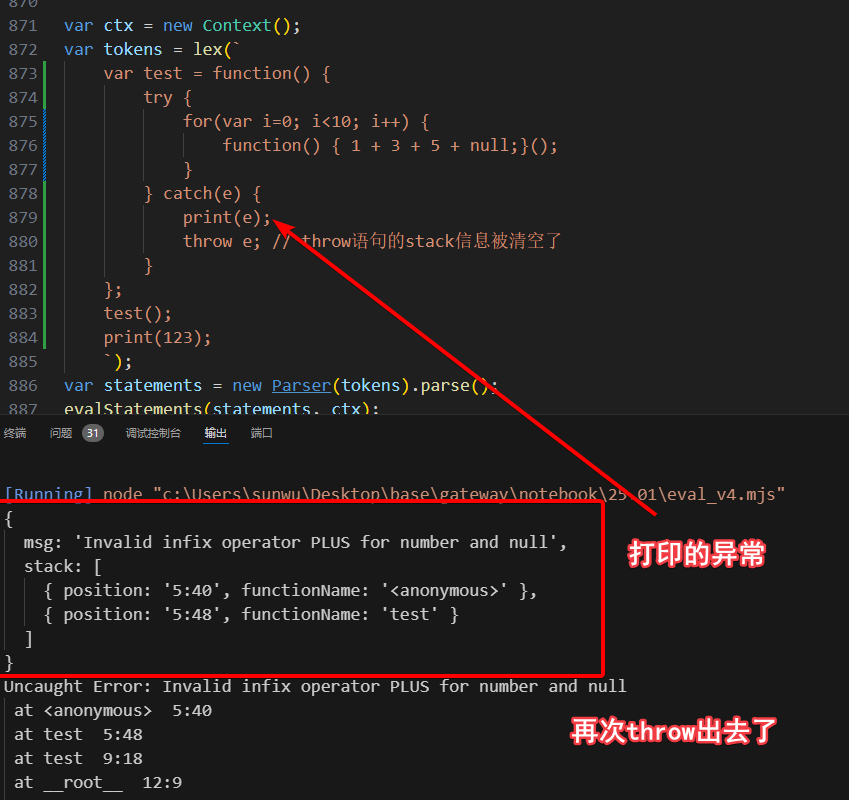
ThrowStatement和TryCatchStatement增加后的完整代码在eval_v4.mjs中。