背景
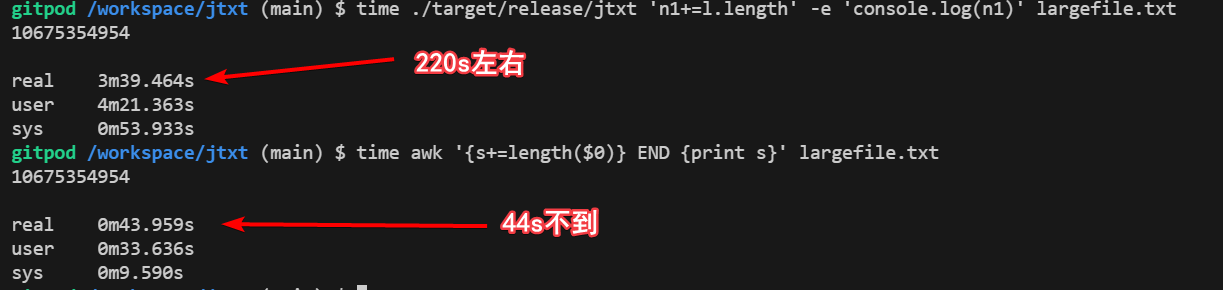
在之前的文章js语法的awk中,我们讲过awk语法比较难记,想要一个能处理文本的工具,但是使用简单且常用的js语法。在之前的文章中,我使用了一种非常简单的“缝合”方式,即使用rust逐行读取文件,对每一行执行命令行输入的js代码,执行方式则是直接使用了rust的一个库deno_core,也就是deno这个运行时的核心库。
这个方式很好的解决了awk语法的难记问题,单也带来了一些性能的问题,这令我耿耿于怀,我们在之前的文章中,简单测试过性能,对于基础的大文件字符串求长度的场景下,与awk有10倍的性能差距,虽然后面发现正则场景下反而速度比较快,猜测是正则匹配的逻辑上有区别导致的,本质上执行过程应该还是有一个数量级的差距。
另外,在生产场景下,我尝试用这个工具,来进行超大日志文件(10GB)的处理,在处理的过程中,发现该程序占用的内存一直在1G左右。这个现象,显然是因为使用了deno_core作为解释器,而deno_core又是基于v8引擎,后者有完整的内存管理和垃圾回收机制,对于超大文件的处理,每一行都要在v8中赋值到一个变量上,所以内存占用至少要申请10G,当然在1G左右的时候,应该是达到了v8默认的堆内存GC阈值,触发了垃圾回收,导致整体处理时间非常慢。大概要慢2-3个数量级了,处理10g文件,对当前机器的资源占用也远超过awk。
awk内存一直占用很少,不到100M(甚至不到10M)。

jtxt内存会到1.4G然后gc后降低到900M然后再到1.4G来回循环。

在上面10G文件的简单长度统计中,jtxt以慢5倍的速度还长期占用了超过1G内存。
所以,我就思考了一下,awk为什么能够比jtxt快的同时占用资源还少?我先做了一个实验,直接用nodejs来读取文件,并统计字符数,结果发现,统计时间只有41s,内存占用也不到100M,只有83M。
const fs = require('fs');
const readline = require('readline');
async function calculateTotalLineLength(filePath) {
// 创建文件流
const fileStream = fs.createReadStream(filePath);
// 使用 readline 模块逐行读取文件
const rl = readline.createInterface({
input: fileStream,
crlfDelay: Infinity // 适用于 \r\n 和 \n 换行符
});
let totalLength = 0;
// 逐行读取文件
for await (const line of rl) {
totalLength += line.length;
}
return totalLength;
}
// 使用异步函数来执行
(async function() {
try {
const filePath = './largefile.txt'; // 替换为你的文件路径
const totalLength = await calculateTotalLineLength(filePath);
console.log(`Total length of all lines: ${totalLength}`);
} catch (err) {
console.error('Error reading file:', err);
}
})();
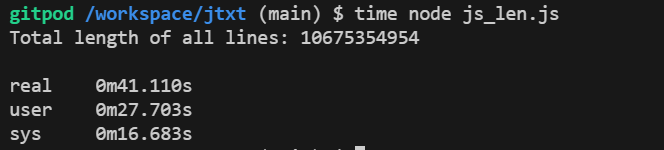

那么,我们看到nodejs或者说v8直接运行js代码,时间就只有41s,与awk接近,而使用deno(本质也是v8),逐行解释运行,时间就变成了3min+。这里我觉得有以下几点的差异:
- 1 直接运行有
字节码与JIT等优化,而jtxt每行代码都是重新解释执行,没法优化。 - 2 字符串获取方式不同,直接运行是直接读文件得到的字符串,而
jtxt是读取文件之后,用var l =+'...'的形式将rust读取到的数据,再拼接成一个变量扔到v8去解释运行。var赋值语句的解释本身就是多出的一部分成本。 - 3
nodejs运行效率比deno高,都是v8引擎,但是上层实现上可能有差异。
优化1
针对第一点,我们可以修改jtxt代码,将我们的输入指令封装到一个全局函数中,接收变量l,每次只要把读取当前行的文本赋值给l,然后调用全局函数process(l)即可,这样process(l)是提前声明的全局函数,多次调用后v8会进行jit的优化,这样应该能解决问题1中的一部分痛点。
修改代码:
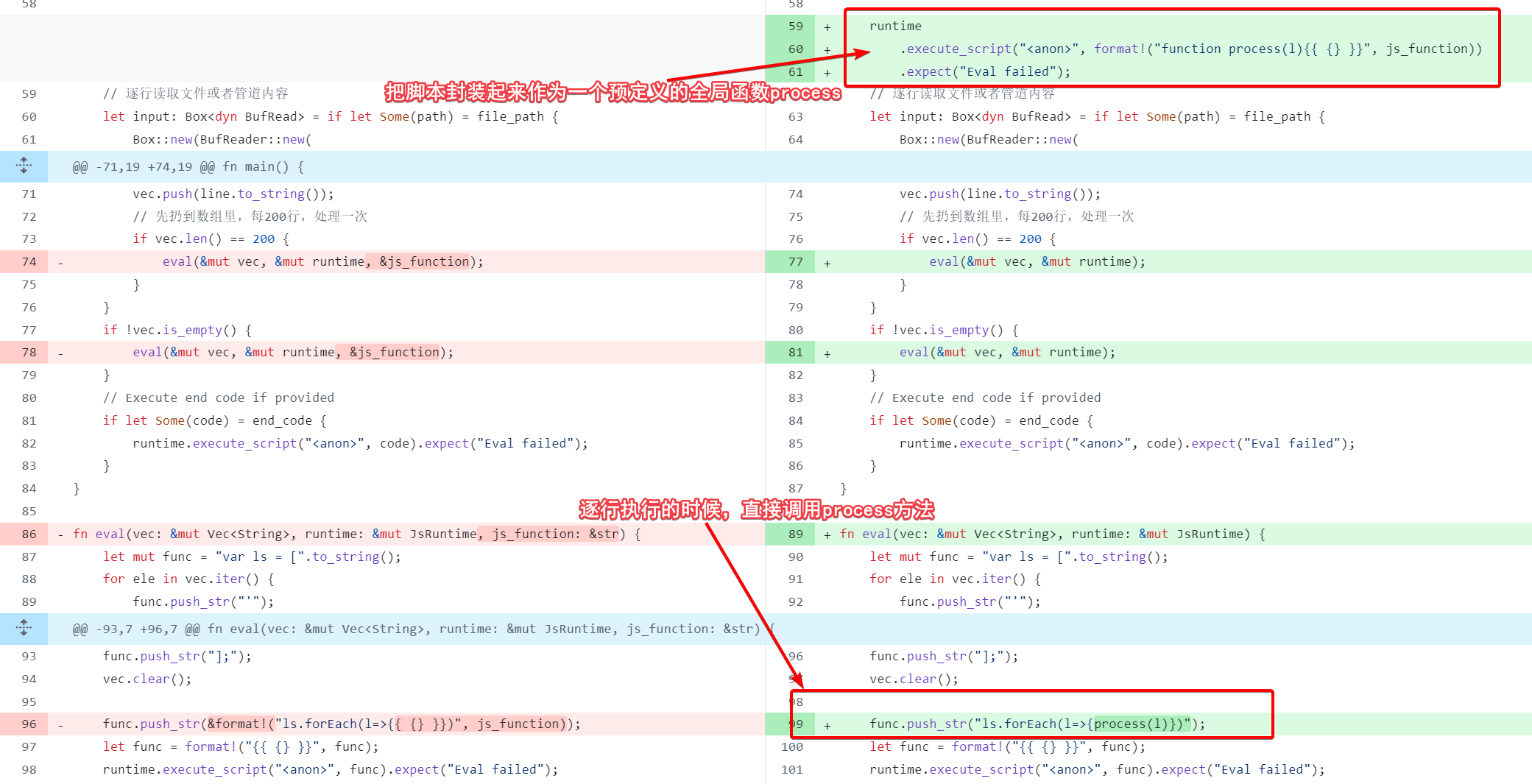
然而实际上效果如下,运行时间来到了200s,比原来220s强了一点点,但是整体还是离40s有很大差距。


针对第一点的优化收效甚微,而且内存问题没有解决。
优化2
rust代码中有一段拼写字符串的,为了避免转义问题有这样一行代码let line = line.replace("\\", "\\\\").replace("'", "\\'");,我们先给他去掉,虽然逻辑上有问题,但是我们文件中无引号,可以去掉后看看性能是否有提升,测试发现有30s左右的提升,算是很大的提升了,但是仍有2min+,相比40s还是慢了很多。
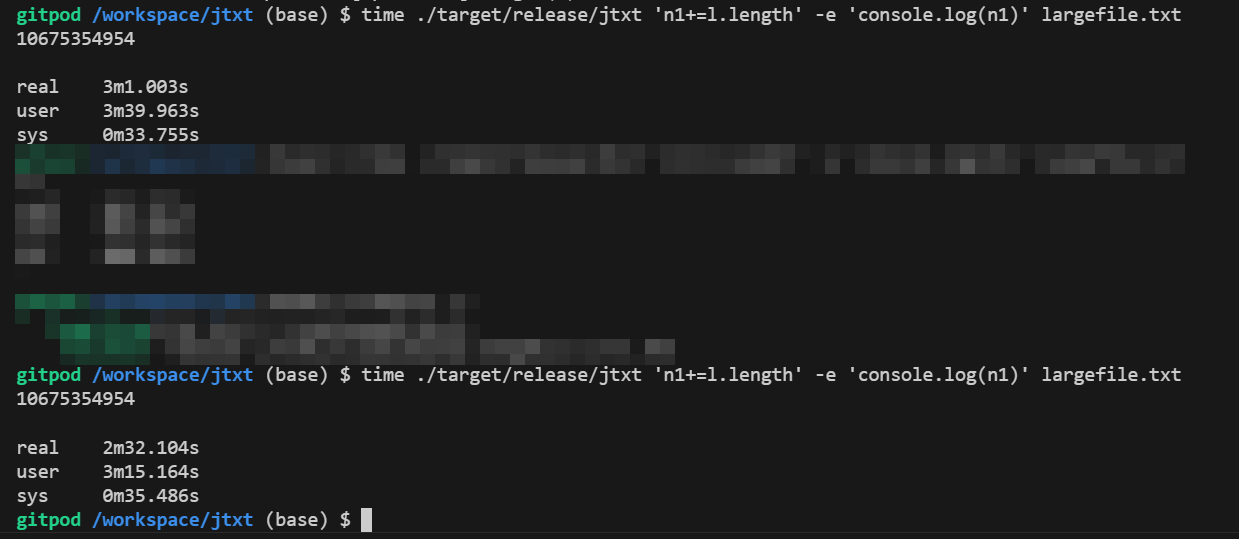
前面的猜想中有赋值语句,给字符串赋值的解释运行耗时过程,那么我们改成,在rust中直接求完长度,把长度数字传到process函数:
let mut func = "var ls = [".to_string();
for ele in vec.iter() {
// func.push_str("'");
func.push_str(&format!("{}", ele.len()));
// func.push_str("', ")
}
func.push_str("];");
果然这次的运行时间来到了1min以内,也是40s左右,和awk node的运行时间来到了同一档。但是内存还是很大。


到这里基本确定了就是赋值语句的解释运行导致执行较慢,因为我们的代码就是两步,第一步字符串赋值var ls = [字符串1, 字符串2...],第二步是ls.forEach(l => process(l)),上面把赋值改为了数字var ls = [100,111, ...]字符串的长度计算好之后,把长度传入解释运行就变快了。当然还有一个小区别,就是后者求长度是rust中的len函数,前者是js中l.length,js中是utf16,rust是直接求的字节数,可能rust中会快一点,为了排除这种差异,我们直接把process函数设置为空,只运行var ls = [字符串1, 字符串2...]看下耗时,果然只进行个变量的赋值消耗的时间就有140s了,而rust读文件+运行加法解释的时间大概40s,单纯用rust读文件+运行加法时间是20s左右,rust的加法时间可以忽略了,最后我们会得到结论:
- 读6kw行,每行100-200字符的文件,
rust中需要20s,node中也是20s。 rust中用deno运行6kw次,字符串求长度和加法操作,时间大概是20s,node中运行相同的内容也是20s,因而node总时间是40srust中对10G字节的字符串进行两次replace,需要30s。rust中用deno运行6kw次,字符串变量赋值操作,时间大概是120s,这是当前设计最大的瓶颈。- 最后
rust中完成读文件,replace,赋值,字符串求长度,数字加和 = 20 + 30 + 120 + 20 = 190s,完全符合我们之前测试的200s左右的耗时,还要考虑到容器资源的波动。

优化3
既然nodejs直接读取文件速度不慢,那么nodejs自身运行时嵌入一段eval函数执行代码,是不是就避免了var语句在v8中的解释运行了,因为nodejs读取出文件的内容已经是一个变量了,这岂不是一个最简单的方式避免var语句的解释,其实也是最应该想到的一种方案,但是因为觉得rust性能会高一些,所以一开始选了rust+deno,上面验证下来发现,读文件来说,解释型语言未必比编译型的差,因为都是调用系统调用进行文件读。
代码就是把之前的稍微改一下;
const fs = require('fs');
const readline = require('readline');
const { program } = require('commander');
// 定义命令行选项
program
.version('1.0.0')
.argument('<logic>', '处理逻辑的 JavaScript 代码')
.argument('[filename]', '要读取的文件名', null)
.option('-b, --begin <code>', '初始化的逻辑代码')
.option('-e, --end <code>', '结束后的逻辑代码')
.parse(process.argv);
// 解析命令行参数
const options = program.opts();
const logic = program.args[0];
const filename = program.args[1];
var begin_func = function(){}, end_func = function(){},
process_func = new Function('l', 'ctx', logic);
if (options.begin) {
begin_func = new Function('ctx', options.begin);
}
if (options.end) {
end_func = new Function('ctx', options.end);
}
// 预定义全局变量
var ctx = {
n1: 0, n2: 0, n3: 0, s: '', arr: []
};
// 处理文件或标准输入
const processStream = (stream) => {
begin_func(ctx);
const rl = readline.createInterface({
input: stream,
output: process.stdout,
terminal: false,
crlfDelay: Infinity // 适用于 \r\n 和 \n 换行符
});
rl.on('line', (line) => {
try {
process_func(line, ctx);
} catch (error) {
console.error('Error processing line:', error);
}
});
rl.on('close', () => {
// 执行结束逻辑
end_func(ctx);
});
};
// 判断处理文件还是标准输入
if (filename) {
const fileStream = fs.createReadStream(filename);
processStream(fileStream);
} else {
processStream(process.stdin);
}
然后竟然真的变快了,内存占用也变低了,没想到多一个赋值语句的eval竟然性能下降这么多。


小结
回头来看的话,原来的设想是基于rust作为宿主语言,可以在读文件和一些前期处理上有更好的性能,然后解释运行的部分在使用deno的v8引擎上,结果到头来发现,直接使用nodejs作为宿主语言反而更快,而且代码更简单,只不过使用起来比较麻烦需要node环境,或者pkg打包。打包之后的大小有70M还是比较大。
这里也可以直接试一下deno/bun实现类似的代码来对比一下三个运行时在读文件、解释运行、内存占用上性能的差距。也算是探索下到底是不是deno这个场景下有问题,这部分留到下一篇文章介绍了。