书接上回,在上一篇文章用js语法实现awk小工具中,我们发现使用nodejs实现工具比rust+deno的效率要高很多,猜测是var变量赋值的语句导致的效率较低,或者node比deno快。
node版本的代码:
const fs = require('fs');
const readline = require('readline');
const { program } = require('commander');
// 定义命令行选项
program
.version('1.0.0')
.argument('<logic>', '处理逻辑的 JavaScript 代码')
.argument('[filename]', '要读取的文件名', null)
.option('-b, --begin <code>', '初始化的逻辑代码')
.option('-e, --end <code>', '结束后的逻辑代码')
.parse(process.argv);
// 解析命令行参数
const options = program.opts();
const logic = program.args[0];
const filename = program.args[1];
var beginFunc = function(){}, endFunc = function(){},
processFunc = new Function('l', 'ctx', logic);
if (options.begin) {
beginFunc = new Function('ctx', options.begin);
}
if (options.end) {
endFunc = new Function('ctx', options.end);
}
// 预定义全局变量
var ctx = {
n1: 0, n2: 0, n3: 0, s: '', arr: []
};
// 处理文件或标准输入
const processStream = (stream) => {
beginFunc(ctx);
const rl = readline.createInterface({
input: stream,
output: process.stdout,
terminal: false,
crlfDelay: Infinity // 适用于 \r\n 和 \n 换行符
});
rl.on('line', (line) => {
try {
processFunc(line, ctx);
} catch (error) {
console.error('Error processing line:', error);
}
});
rl.on('close', () => {
// 执行结束逻辑
endFunc(ctx);
});
};
// 判断处理文件还是标准输入
if (filename) {
const fileStream = fs.createReadStream(filename);
processStream(fileStream);
} else {
processStream(process.stdin);
}
deno
我们就让gpt把nodejs代码转换成deno版本
// 使用 URL 导入 Deno 版本的 commander 库
import { Command } from "https://deno.land/x/[email protected]/command/mod.ts";
import { readLines } from "https://deno.land/[email protected]/io/mod.ts";
// 定义命令行选项
const { options, args } = await new Command()
.version('1.0.0')
.arguments('<logic:string> [filename:string]')
.option('-b, --begin <code:string>', '初始化的逻辑代码')
.option('-e, --end <code:string>', '结束后的逻辑代码')
.parse(Deno.args);
const logic = args[0];
const filename = args[1];
let beginFunc = () => {};
let endFunc = () => {};
let processFunc = new Function('l', 'ctx', logic);
if (options.begin) {
beginFunc = new Function('ctx', options.begin);
}
if (options.end) {
endFunc = new Function('ctx', options.end);
}
// 预定义全局变量
let ctx = {
n1: 0, n2: 0, n3: 0, s: '', arr: []
};
// 处理文件或标准输入
const processStream = async (reader) => {
beginFunc(ctx);
for await (const line of readLines(reader)) {
try {
processFunc(line, ctx);
} catch (error) {
console.error('Error processing line:', error);
}
}
// 执行结束逻辑
endFunc(ctx);
};
// 判断处理文件还是标准输入
if (filename) {
const file = await Deno.open(filename, { read: true });
await processStream(file);
file.close();
} else {
await processStream(Deno.stdin);
}
经过测试发现deno版本的确实慢很多,执行的过程中内存占用大概也是100M以内,但是执行速度确实是deno慢很多,看来和赋值语句的效率关系不大。上面我们基本也就用到了readLines读文件的库,这个库还是官方提供的,虽然gpt给出的是一个比较老的版本,新版本已经不提供了。
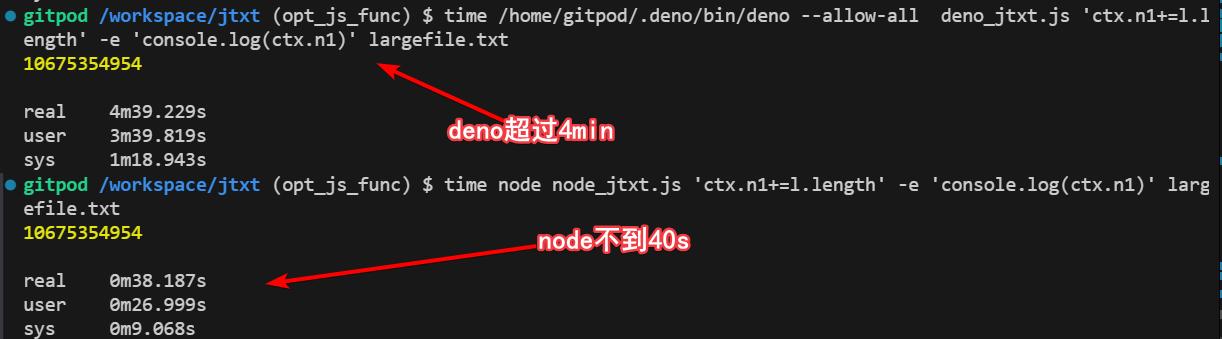
因为都是v8理论上不会有这么大的差距,所以我感觉readlines这个函数有问题,也就是读文件这一步在IO擦欧洲哦上应该是有性能问题的,自己用原生的读文件实现一下:
// 使用 URL 导入 Deno 版本的 commander 库
import { Command } from "https://deno.land/x/[email protected]/command/mod.ts";
// import { readLines } from "https://jsr.io/@std/io/0.225.2/mod.ts";
// 定义命令行选项
const { options, args } = await new Command()
.version('1.0.0')
.arguments('<logic:string> [filename:string]')
.option('-b, --begin <code:string>', '初始化的逻辑代码')
.option('-e, --end <code:string>', '结束后的逻辑代码')
.parse(Deno.args);
const logic = args[0];
const filename = args[1];
let beginFunc = () => {};
let endFunc = () => {};
let processFunc = new Function('l', 'ctx', logic);
if (options.begin) {
beginFunc = new Function('ctx', options.begin);
}
if (options.end) {
endFunc = new Function('ctx', options.end);
}
// 预定义全局变量
let ctx = {
n1: 0, n2: 0, n3: 0, s: '', arr: []
};
const decoder = new TextDecoder();
const buffer = new Uint8Array(1024*1024);
// 处理文件或标准输入
const processStream = async (reader) => {
beginFunc(ctx);
let result = '';
while (true) {
const n = await reader.read(buffer);
if (n === null) break; // 文件读取完毕
result += decoder.decode(buffer.subarray(0, n));
// 处理每一行
const lines = result.split('\n');
for (let i = 0; i < lines.length - 1; i++) {
processFunc(lines[i], ctx);
}
result = lines[lines.length - 1];
}
// 执行结束逻辑
endFunc(ctx);
};
// 判断处理文件还是标准输入
if (filename) {
const file = await Deno.open(filename, { read: true });
await processStream(file);
file.close();
} else {
await processStream(Deno.stdin);
}
这次好多了,deno耗时是35s,node是25s。
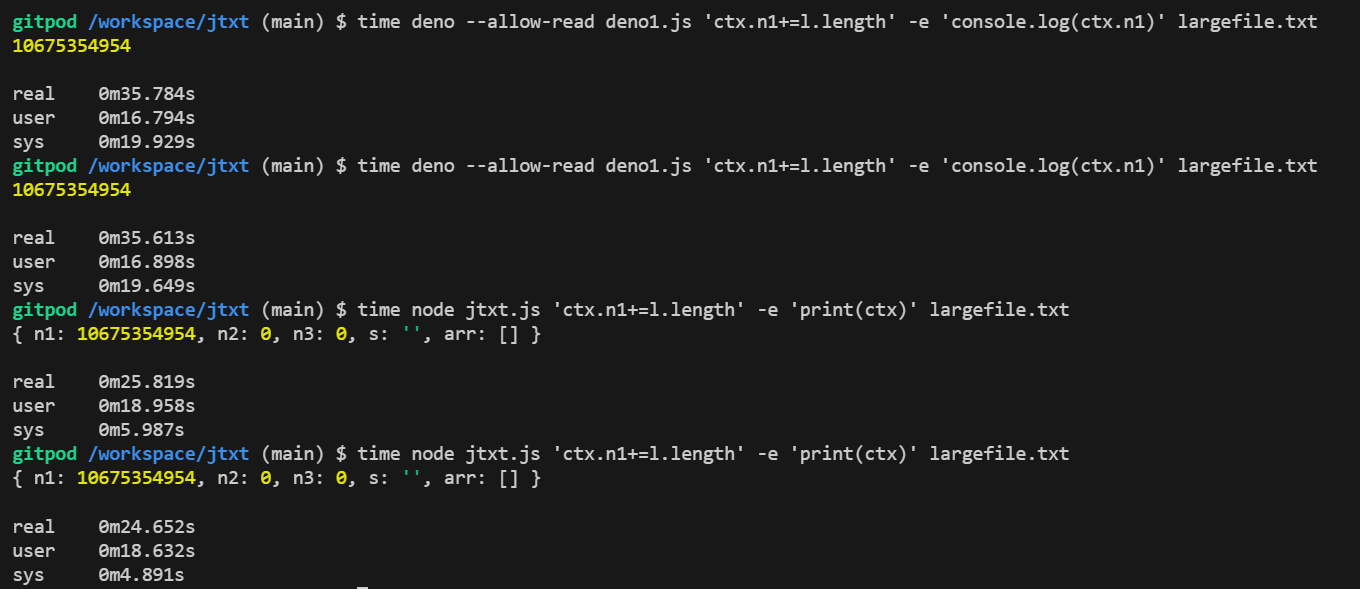
也就是deno比node稍微慢一些,但是整体差距不大,那之前出现较大性能差距的原因就找到了。是var语句导致的。
bun
bun的包兼容node-npm,并且还同时支持Es和commonjs写法,所以直接运行node版本的代码即可。
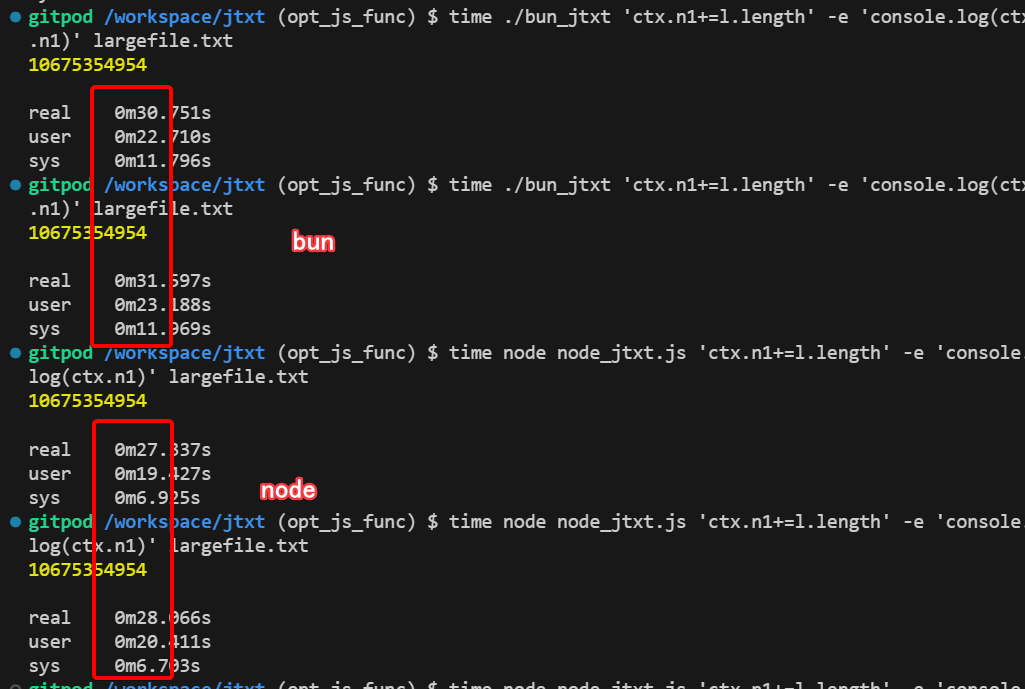
bun执行过程中内存稍高与其他两个,达到了150M左右,node/deno基本都是<100M

但是执行速度也是不到40s,与nodejs伯仲之间,当然因为使用的gitpod的虚拟环境,不同时间分别执行程序的耗时都会有波动,所以只能看个大概,目前来看三者的执行速度差不多,具体要细分的话node最快,然后是bun,最后是deno。
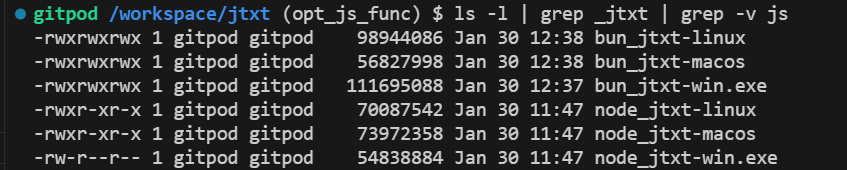
然后再对比bun和node的打包后的大小,差距也不大,都是50M以上了,都很大。
mocha-rs
除了js运行时,这里我加入对比了mocha-rs,这是我之前实现一门语言写的一个简易版本的js解释器,在我的解释器中,没有字节码,没有JIT,更没有编译,是0优化的纯解释运行。
这里需要把mocha-rs代码库下载,cargo add clap,然后修改一下main.rs即可:
extern crate core;
mod eval;
mod lexer;
mod parser;
mod sdk;
use crate::eval::eval::{eval_block, eval_statements};
use crate::eval::{get_null, Context, Element, ErrorElement, SimpleError};
use lexer::lexer as LEX;
use parser::parser as PARSER;
use std::cell::RefCell;
use std::{fs, io, panic};
use std::io::Write;
use std::panic::{panic_any, AssertUnwindSafe};
use std::rc::Rc;
use crate::sdk::get_build_in_ctx;
use clap::{Arg, Command};
use std::fs::File;
use std::io::{BufRead, BufReader};
use std::collections::HashMap;
fn main() {
panic::set_hook(Box::new(|_| {}));
env_logger::init();// 定义参数形式为 jtxt [option] function [file]
let matches = Command::new("jtxt")
.version("1.0")
.author("Your Name <[email protected]>")
.about("Processes lines of input with JavaScript")
.arg(
Arg::new("begin")
.short('b')
.long("begin")
.help("JavaScript code to execute before processing any lines")
.value_parser(clap::builder::ValueParser::string()),
)
.arg(
Arg::new("end")
.short('e')
.long("end")
.help("JavaScript code to execute after processing all lines")
.value_parser(clap::builder::ValueParser::string()),
)
.arg(
Arg::new("function")
.help("JavaScript code to process each line, l is the origin string")
.required(true)
.index(1),
)
.arg(
Arg::new("file")
.help("Path to the input file. If not provided, reads from stdin.")
.index(2),
)
.get_matches();
let begin_code = matches.get_one::<String>("begin");
let end_code = matches.get_one::<String>("end");
let js_function = matches.get_one::<String>("function").unwrap();
let file_path = matches.get_one::<String>("file");
// 逐行读取文件或者管道内容
let input: Box<dyn BufRead> = if let Some(path) = file_path {
Box::new(BufReader::with_capacity(1024 * 1024,
File::open(path).expect("Failed to open file"),
))
} else {
Box::new(io::stdin().lock())
};
let ctx = Rc::new(RefCell::new(get_build_in_ctx()));
// 预设的全局变量
eval_code(r#"
var ctx = {};
var n1 = 0;
var n2 = 0;
var n3 = 0;
var s = "";
var arr = []; "#, ctx.clone());
// 执行begin的代码块,如果有的话
if let Some(code) = begin_code {
eval_code(code, ctx.clone());
}
let mut total: f64 = 0.0;
let tokens = LEX::lex(js_function);
let statements = PARSER::Parser::new(tokens).parse();
for line in input.lines() {
ctx.borrow_mut().set("l", Rc::new(RefCell::new(Element::new_string(line.unwrap()))));
eval_statements(&statements, ctx.clone(), true);
}
// 执行end的代码块,如果有的话
if let Some(code) = end_code {
eval_code(code, ctx.clone());
}
}
fn eval_code(code: &str, ctx : Rc<RefCell<Context>>) {
let tokens = LEX::lex(code);
let statements = PARSER::Parser::new(tokens).parse();
eval_statements(&statements, ctx.clone(), true);
}
运行
$ cargo b -r
$ ./target/release/jtxt 'n1=n1+l.length()' -e 'print(n1)' largefile.txt
结果可想而知,速度非常慢,下面是执行了2分钟的截图,此时还运算出结果,但是会发现内存占用很小只有6M。

直到3min才运算完成,相比第一梯队的40s,mocha-rs执行时间大概有200s,速度比较慢,当然这里有一些客观原因:mocha-rs中字符串长度,是每次对字符串运行,转换为utf8char[],然后求长度,而awk是直接求的字节数,不需要转换,nodejs是把底层utf-8字符串自动编码utf-16了,然后utf-16求长度是字节数除以2,即把转码工作量放到了底层。
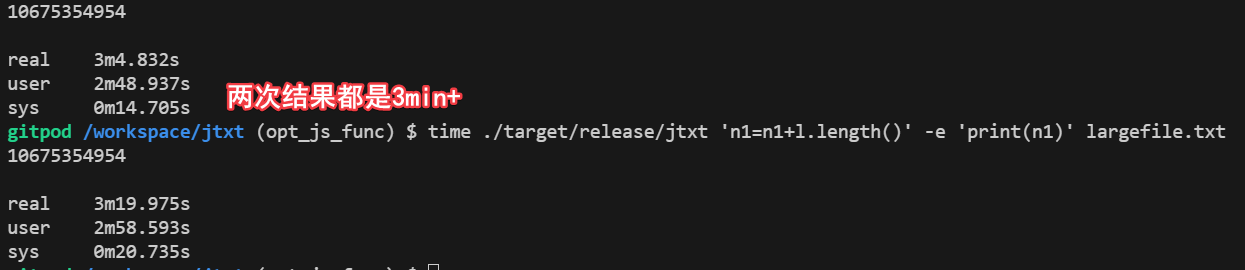
如果我们把mocha-rs求字符串长度的函数改为直接求字节数,会节省掉转码的过程,速度会快一些,大概在2min,130s左右。距离awk还有3~4倍左右的差距。
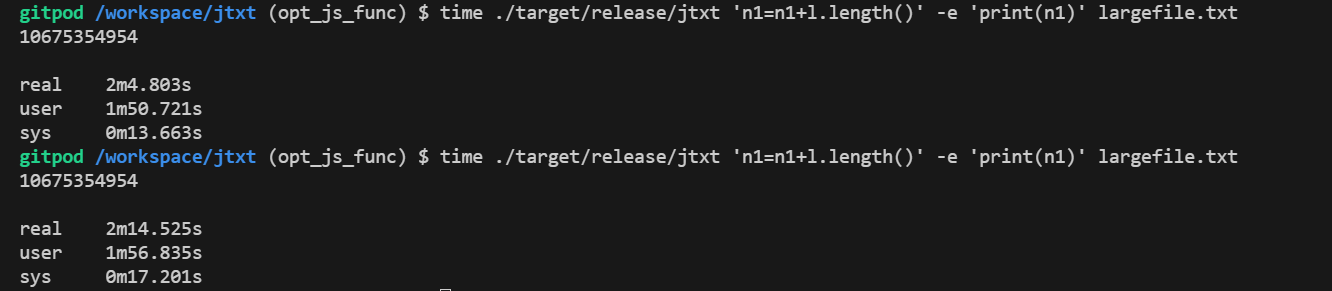
当然awk支持的表达式和语法较少,我们的解释器有闭包、函数、循环、条件、面向对象、异常捕捉等等语言特性,所以mocha-rs的运行速度会慢一些,和awk相比性能可以维持在相同的数量级,说明awk其本身也是解释运行的,也有一定的优化空间,字节码、JIT等。
此外,mocha-rs大量使用了Rc<RefCell<T>>,会有性能的开销,如果用golang重写的话,我个人觉得性能会有提升。
小结
以上测试存在一定误差,因为使用的是gitpod分配的容器资源,资源会存在波动,但整体差距不是很大。如果想严谨测试,可以用自己的电脑重新试一下。最后在对bun node和mocha进行了分别连续2次的测试,结果如下:
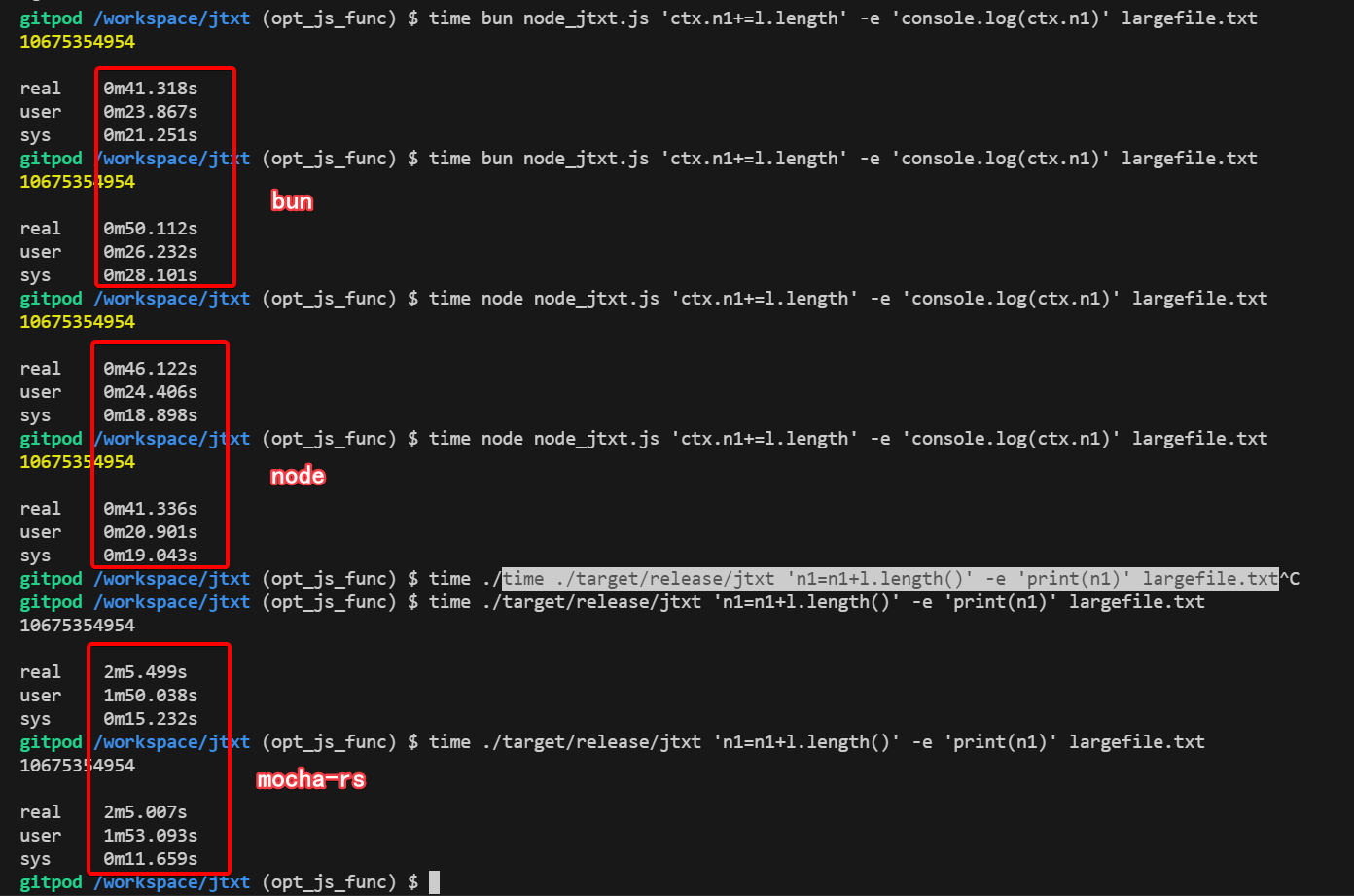
最后考虑到了通用性,我决定用nodejs把jtxt项目给重写了,放弃rust + deno_core。