概述
jvm字节码中有有五种Invoke指令,其中4种功能和使用都非常好理解:
- invokestatic静态方法调用
- invokeinterface接口方法调用
- invokevirtual正常方法调用
- invokespecial特殊方法如private方法、构造方法调用
但是invokedynamic的作用和这四种完全不同,他更加复杂,更加黑盒。
描述一下invokedynamic的作用是,调用一个指定返回值为CallSite的Bootstrap方法,然后拿出CallSite中绑定的MethodHandle方法句柄,最后运行这个方法得到返回值,所以一行invokedynamic指令转换成伪代码是分别运行了三个函数如下:
bootstrapmethod(xxx).getTarget().invokeExact(xx);
看完会一头雾水,为什么要转换成这样三个函数调用,和直接生成这三个函数调用的字节码有区别吗,等等问题,本文我们来慢慢介绍。
MethodHandle
我们先来解释下MethodHandle方法句柄,他与用反射拿到的Method类似,两者都是方法的载体,并且也都能通过自身的invoke/invokeExact(xx)对方法进行调用,但是有一些重要的区别:
MethodHandle是编译器进行类型安全检查,并且只在创建的时候进行访问权限检查。Method是运行时进行类型安全检查,并且在每次invoke的时候进行访问权限检查。MethodHandle是更容易被JIT优化。Method每次使用都有开销。
大概就是MethodHandle使用更复杂一些,且不含有方法丰富的元数据信息,但是性能更好;Method则反之。反射比较简单,通过Class的getMethod/getDeclaredMethod可以获取,而MethodHandle需要通过Lookup进行方法查找获取。在官方的blog中也介绍了MethodHandle为什么要引入和对比反射Method的区别。
// 反射获取Method,并调用
Method m = String.class.getMethod("toString");
m.invoke("hi");
// MethodHandle需要用lookup查找(lookup是当前创建的,就无法找到当前看不到的方法,比如其他类的private方法,相比反射的后门写法更安全)
MethodHandles.Lookup lookup = MethodHandles.lookup();
// 查找String类中,名为toString的,入参为空返回值为String的方法
MethodHandle mh = lookup.findVirtual(String.class, "toString", MethodType.methodType(String.class));
mh.invoke("hi");
// or
mh.invokeExat("hi");
MethodHandle中invoke/invokeExact区别是后者的类型是静态的性能好,前者可以是动态的,动态场景可以使用,当前场景是静态的,只能是String类型。
findVirtaul是查找virtaul方法与上面提到的invokevirtual类似的查找虚方法(含接口方法),其他方法可以看下对应的其他findXXX。
提出疑问
我们回看invokedynamic伪代码,最后就是调用了MethodHandle#invokeExact方法,那换句话说,其实invokedynamic就是查找一个方法并调用他。那为什么还需要BootstrapMethod(BSM)和CallSite这两层嵌套呢?
这是因为BSM这个方法比较特殊,在多次invokedynamic中同一个BSM的返回值会在第一次调用后缓存,后续调用会直接读取缓存中的CallSite对象返回,BSM的描述信息会被单独记录到字节码的属性中,用来作为缓存的key的一部分,BSM有这个特殊的缓存机制,所以是必要的一层,那CallSite呢?
(下面MH作为MethodHandle的缩写,BSM作为BootstrapMethod缩写)
CallSite
上面的方法句柄是绑定到CallSite中的,CallSite是个抽象类,他有多种实现,常见的有三种ConstantCallSite静态调用点,即绑定的MethodHandle是固定的不会改变的;MutableCallSite是绑定的MH可以被修改,但是多线程需要手动同步,适合单线程可变场景;VolatileCallSite则是线程安全的可变场景。
回到上面的问题,为什么需要CallSite这一层,如果只有静态的调用点ConstansCallSite,那确实不需要CallSite这一层封装,但是考虑到绑定的MH可以修改的情况,而CallSite又是被BSM缓存的对象,缓存是不变的,对应的方法想要修改就只能用BSM-MutableCallSite/VolatileCallSite-MethodHandle这样三层结构了,这样只需要修改MutableCallSite中指向的MH即可改变缓存的实质内容咯。
BootstrapMethod (BSM)
上面已经提到了BSM在invokedynamic中的特殊的缓存机制,这里一定要注意,如果自己用java代码手动调用BSM方法是不会触发这个缓存机制的,只有通过invokedynamic指令调用的BSM才会有缓存和优化,上面提到BSM的返回值必须是CallSite类型,那么这个函数的入参呢?
BSM的入参也有着严格的规范,他的前三个参数分别是:
MethodHandles.Lookup:查找MH要用到的lookupString:MH指向的方法的名字MethodType:MH指向的方法的返回值入参描述。
这三个参数由JVM自动注入,不需要额外指定。后面参数是变长参数Object...,如果自己写BSM的话,需要特殊的参数可以放到最后,自己来定义逻辑。
lambda
这里我们以java中最常出现invokedynamic的lambda表达式为例,来看下是如何工作的。
这段使用了lambda的代码
String hi = "hi";
Runnable r = () -> {
System.out.println(hi);
};
产生的字节码是这样的
ALOAD 1 // 加载hi到栈顶
INVOKEDYNAMIC run(Ljava/lang/String;)Ljava/lang/Runnable; [
// handle kind 0x6 : INVOKESTATIC
java/lang/invoke/LambdaMetafactory.metafactory(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
// arguments:
()V,
// handle kind 0x6 : INVOKESTATIC
com/example/LambdaTest.lambda$main$0(Ljava/lang/String;)V,
()V
]
这里的BSM是java/lang/invoke/LambdaMetafactory.metafactory这个方法,他的入参是Lookup String MethodType(前三个是固定的,前面提到过),然后是MethodType MethodHandle MethodType三个参数如下图,前三个都是vm自动注入的,后面三个参数就分别对应上面字节码// arguments下面的三行会分别对应这三个参数。
在注释中有对后面三个参数的解释:samMethodType是lambda要实现的接口中的方法的签名,我们这里是void run()所以签名是()V;implMethod则是最终实现这个run方法的MH句柄,这里可以看到是LambdaTest.lambda$main$0当前类中的一个合成方法,这个方法是编译器自动生成的;最后instantiatedMethodType这里先认为和samMethodType要保持一致。

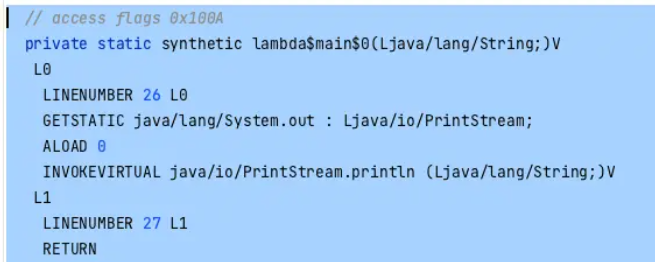
上面提到的当前类中的合成方法,在字节码中可以看到,他的内容如下,是一个入参String空返回值的函数,内容是打印入参的String。
我们继续看BSM做的事情,上来创建一个InnerClassLambdaMetafactory对象,主要是对一些字段赋值,并且这里用到了ASM库的ClassWriter准备在内存中创建一个匿名类的字节码。

这个匿名类还没有完成,目前是有了类名、构造方法、参数的信息,但是还没有真正开始构建字节码,最终如下图其实是在spinInnerClass中完成了这个匿名了类的构建,并加载到当前jvm,然后CallSite的MH指向了匿名类get$Lambda函数(这是有捕捉上下文的情况),没有的话走if分支直接指向匿名类的空参数构造方法。

spinInnerClass的内容如下,可以不用逐行看,直接到最后,把生成类的字节码打个断点,写到一个文件中。
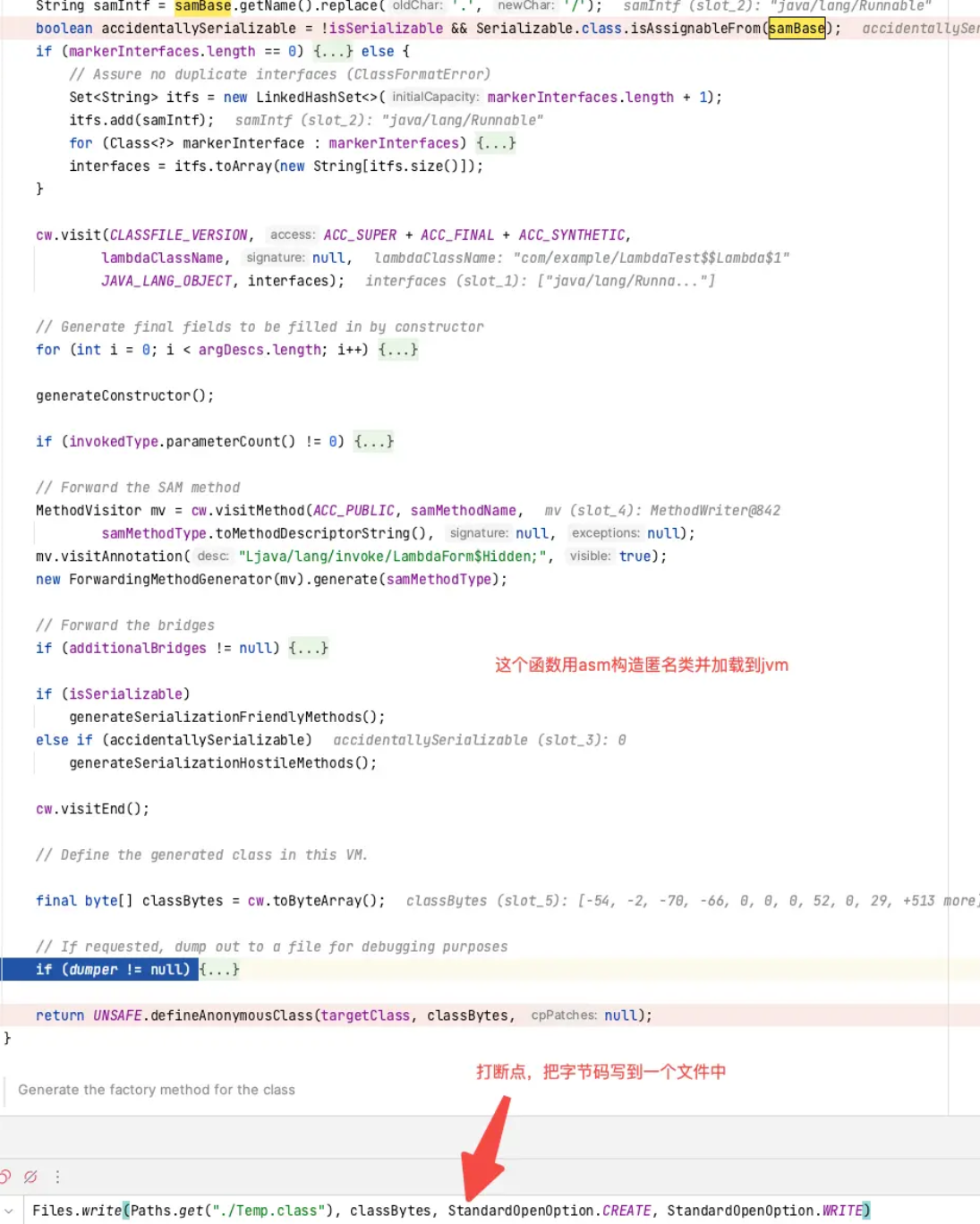
查看文件反编译结果,是一个实现了Runnable接口的类,并且构造方法有一个String入参,这个在run方法中会用到来打印,get$Lambda方法也看到了,是个静态方法,返回的就是new了一个当前类,把String传入了。
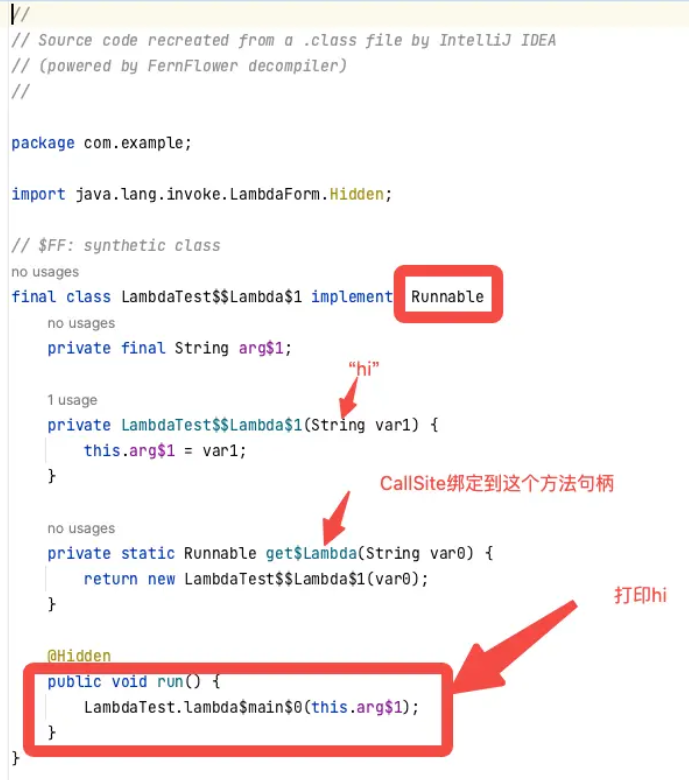
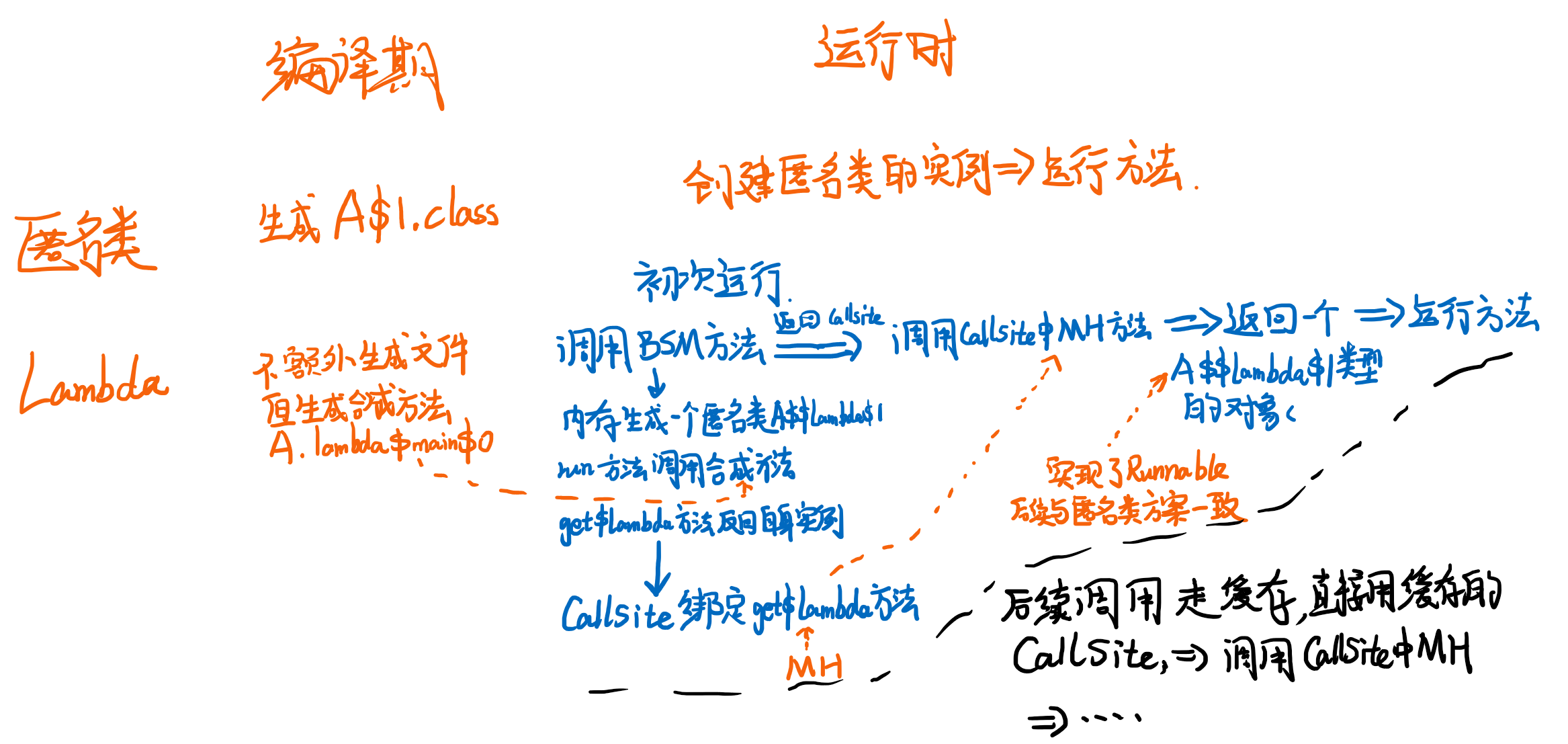
好了,最后理一下思路,lambda的工作原理:
- 第一步,编译器把
lambda函数构造一个当前类中的合成方法,如果有上下文捕捉变量则作为函数的入参,如果没有捕捉this则当前方法是static否则是非static。 - 第二步,
invokedynamic指令调用的BSM是会在内存中临时创建一个实现了Runnable接口的匿名内部类,并且如果有上下文变量捕捉,该类的构造方法会依次放置这些变量,将其设置为字段。然后run方法中直接调用合成方法,合成方法如果需要捕捉的上下文变量,则直接通过this.xx即可传入;最后产生一个get$lambda的静态方法创建一个当前类的对象。 - 第三步,
BSM函数的返回值是ConstantCallSite他的MH指向匿名内部类的get$lambda方法,这是一个返回一个匿名内部类的实例的方法。 - 第四步,
BSM(xxx)返回了CallSite,然后调用CallSite.target()获取到这个get$lambda的MH,调用MH.invokeExact(xxx),入参xxx是栈顶的hi字符串,最后返回一个实现了Runnable的匿名类实例,并且接下来会赋值给变量r。 - 第五步,当第二次调用该指令的时候,不再走
BSM方法体,而是jvm缓存中拿到第一次执行后的CallSite避免再次生成一个匿名内部类。
如何验证第二次没有走BSM呢?在bsm java.lang.invoke.LambdaMetafactory#metafactory第一行打断点,运行下面函数,只有第一次运行会命中,第二次走了缓存。
....
public static void main(String... args) {
// 两次运行,
new LambdaTest().test();
new LambdaTest().test();
}
public void test() {
String hi = "hi";
Runnable r = () -> {
System.out.println(hi);
};
r.run();
}
...
最后一张图来总结Runnable用lambda和匿名类写法,创建和运行的过程。
思考:invokedynamic相比直接用匿名类实现lambda有什么优势呢?
invokedynamic也是一个匿名类,只不过是内存中的匿名类,不需要编译期生成class文件,避免了大量零碎的class文件;在性能上,MH可以被jvm的jit更好的内联增强,但是匿名类也会被jit增强,所以性能上没有优势,甚至因为forward一层转到调用合成方法,可能还要更慢一点。
动态语言
indy的介绍一般都会提及在lambda 字符串拼接(jdk9+) 动态语言支持上会被使用。那我们就来看一下动态语言支持上是如何使用的。以groovy为例,在groovy中是可以不指定类型的,变量是动态类型的。并且可以在对象上动态追加新的属性。
def obj = new Object()
// 类级别的MetaClass
Object.metaClass.getA = { -> "1" }
println obj.a // 1
// 实例级别的MetaClass
obj.metaClass.getA = { -> "2" }
println obj.a // 2
// 实例级别的MetaClass修改
obj.metaClass.getA = { -> "3" }
println obj.a // 3
def是不指定类型的动态类型,即obj当前是A类型,后面还可以赋值为B类型,动态类型是通过直接声明为Object来实现的:
def x = 1; // Object x = 1;
x = "str"; // x = "str";
而动态属性追加和动态属性的解析是groovy的核心功能,这个功能的实现invokedynamic并不是必须的,我们先来说不用invokedynamic的实现思路。
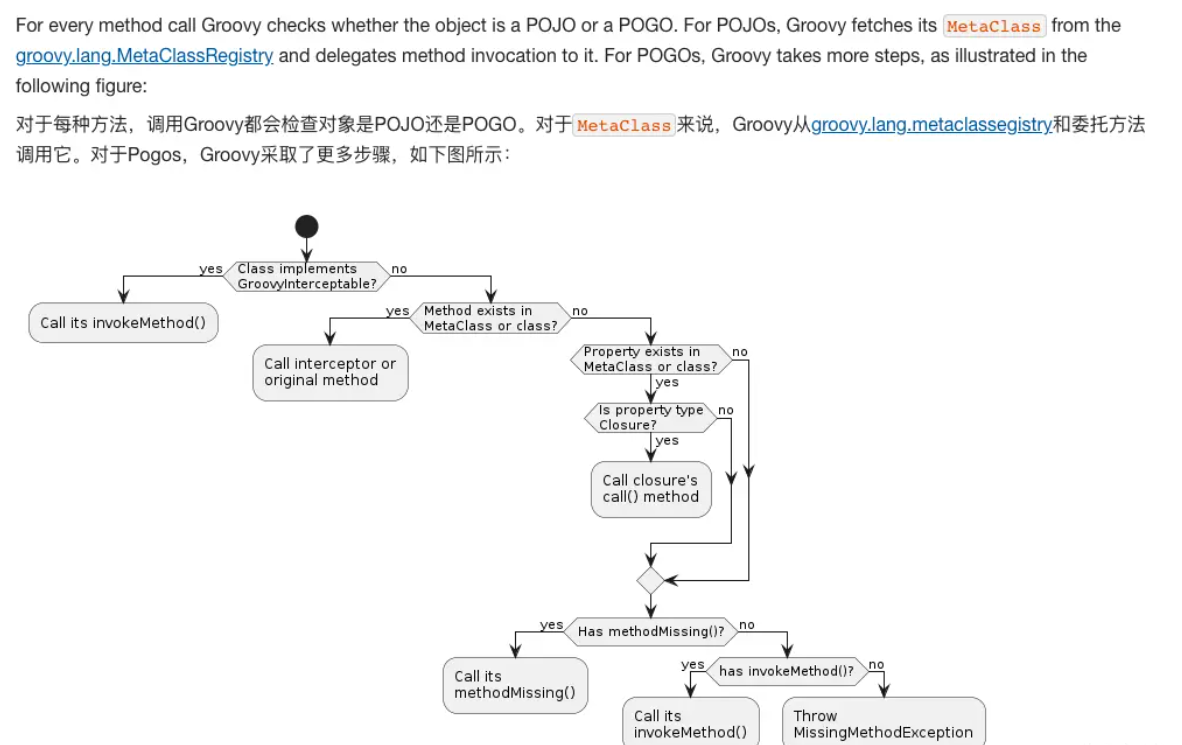
Groovy中有三种对象:java对象、groovy对象和实现了GroovyInterceptable接口的对象。
对于POJOjava对象来说,对于类和对象实例都有全局注册的Map存储了对应类/实例所对应一个扩展属性用的MetaClass对象,这个对象我们可以简单理解成一个Map来存储新增的属性的k和v。
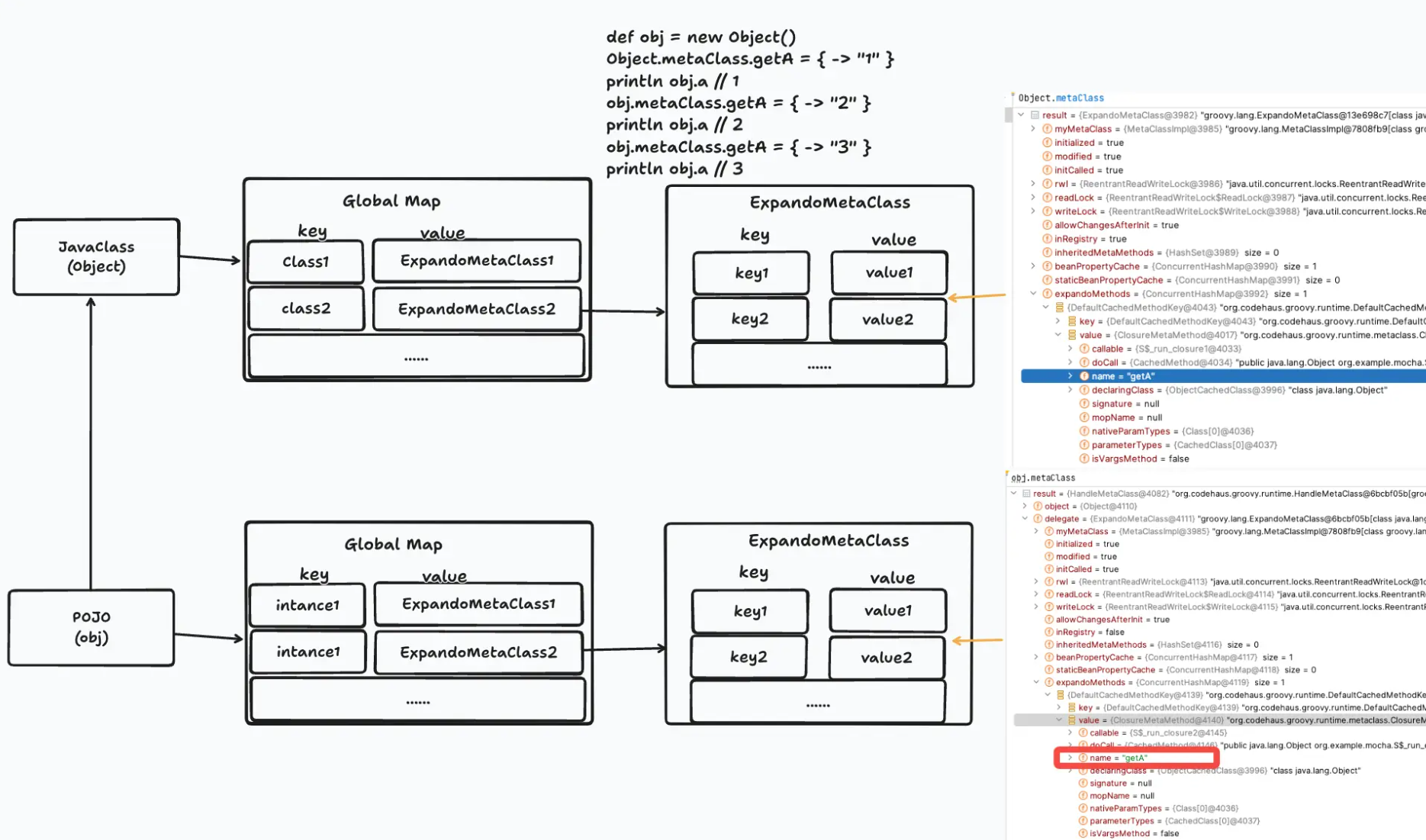
当调用obj.a的时候,会分别到对象的MetaClass->类的MetaClass->POJO对象本身中寻找有没有getA方法或者a属性,所以上面代码第一次打印,只有类的MetaClass中含有getA所以打印1,第二次运行的时候实例自身的MetaClass中有getA方法了,所以直接走实例的扩展MetaClass。
这个方案为已有的java类和对象,提供了很高的灵活性,可以动态增删属性,但是对于对象的MetaClass和对象本身的销毁需要额外的考虑,来避免内存长期占用。
对于第二种情况,在groovy中声明的class创建的GroovyObject就更简单一些了,groovy中的所有class在生成字节码的时候,会自动增强,来实现一个GroovyObject接口,这个接口中就需要有MetaClass的getset方法,直接在对象中关联MetaClass就不用全局的注册的Map了,不过最终效果是类似的,如下图。详细的元编程,可以看官方文档主要是运行时元编程部分。
我们就不再展开了,因为有一些扯远了,我们回到invokedynamic,对于obj.a这行代码会从groovy生成的脚本的字节码能看到invokedynamic指令。也就是groovy中最基础的.运算符都是用invokedynamic指令实现的,他的实现逻辑是通俗介绍:初次运行BSM,会将上面我们介绍的属性/方法层层查找的逻辑,找到之后将方法的MH设置到CallSite中缓存起来。第二次调用的时候,就可以直接用缓存中的MH,省去了查找的逻辑,这就是invokedynamic的对动态语言的效率增强的核心逻辑,当然这是一个通俗介绍,实际代码非常的复杂,考虑的情况也非常多。
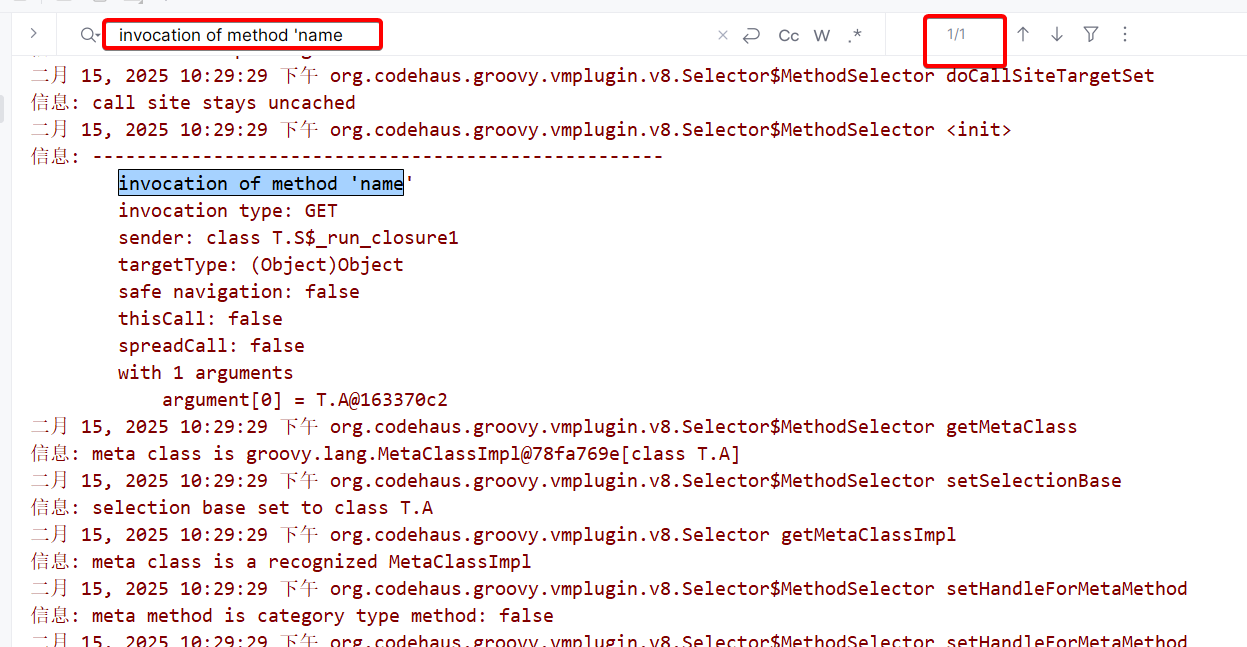
验证缓存的过程,给出这样一段groovy脚本
class A {
def name = "A"
}
def function = { x -> x.name}
function(new A())
function(new A())
配置启动参数-Dgroovy.indy.logging=true
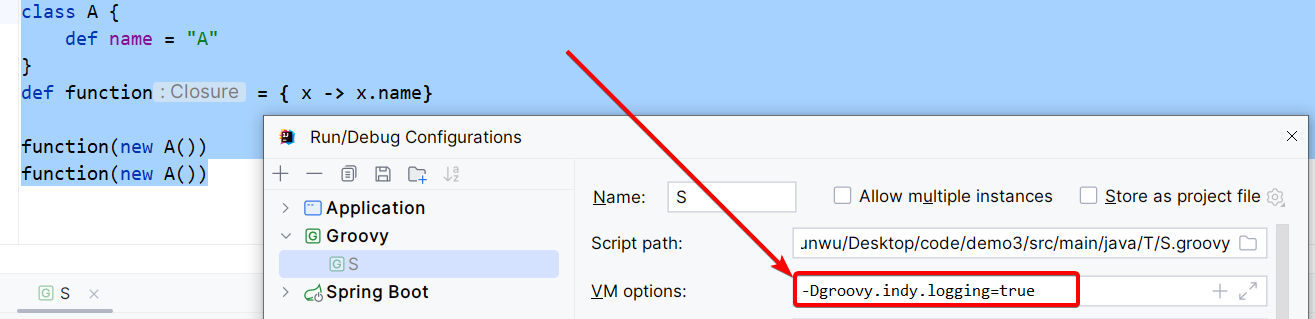
运行后,会打印动态的方法搜索的过程,x.name这里会搜索name的get方法,function运行2次,第一次走BSM会进行name的get搜索,第二次走缓存,不再搜索,所以只会搜到一次name的搜索。